
批量推理任务 API
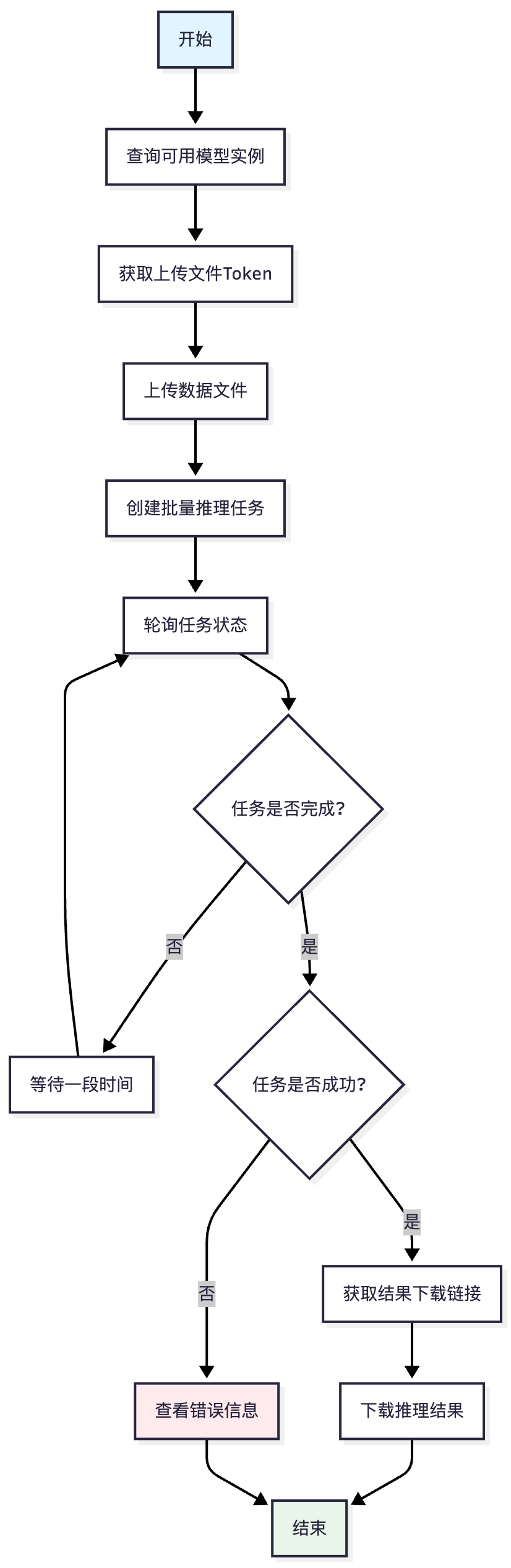
操作流程
批量推理API调用详细步骤
步骤1: 查询模型实例
获取支持离线推理的模型实例列表,用户可以根据需求选择合适的模型。
步骤2: 获取上传Token
系统生成临时的上传凭证,确保文件上传的安全性。
步骤3: 上传数据文件
使用获取的Token将数据文件上传到指定的存储服务。
步骤4: 创建推理任务
提交推理任务请求,包含模型实例ID、文件Token等必要信息。
步骤5: 监控任务状态
定期查询任务执行状态,直到任务完成。
步骤6: 下载结果
任务成功完成后,获取结果文件的下载链接并下载。
流程图
API接口详情
使用说明:
1. 获取项目 ID
项目 ID 需要从控制台 URL 中提取。例如,在访问项目详情页时,URL 地址栏中会包含对应的项目 ID。

2. API Key 配置要求
API Key 必须与对应的项目相匹配,否则将导致身份验证失败。请确保使用正确的项目 API Key 进行接口调用。详情可参考:API Key管理。
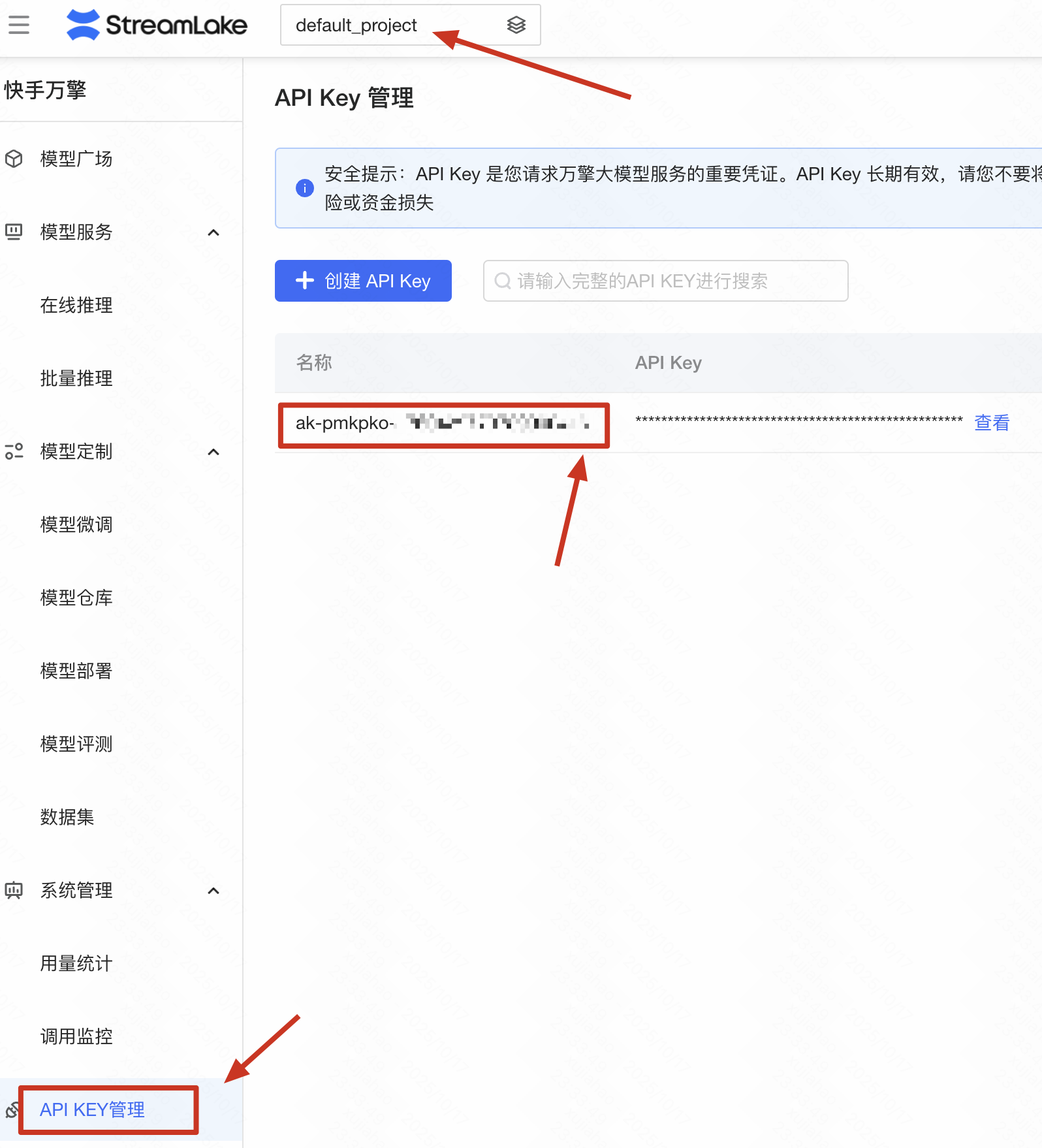
请检查apikey是否位于目标项目下
1. 查询模型实例
接口地址: `GET https://wanqing.streamlakeapi.com/api/openapi/v1/model-instances`
请求参数:
参数名 | 类型 | 必填 | 描述 |
customTags | string | 否 | 自定义标签过滤,如"supportOffline" (由于需要过滤支持离线推理的模型需要增加supportOffline) |
请求头:
参数名 | 值 | 必填 | 描述 |
Authorization | Bearer xxxxx | 是 | 认证令牌 |
响应结构:
{
"ResponseMeta": {
"RequestId": "string",
"HostId": "string",
"ErrorCode": "string",
"ErrorMessage": "string"
},
"ResponseData": {
"total": "number",
"list": [ModelInstance]
}
}
2. 获取上传文件Token
接口地址:`GET https://wanqing.streamlakeapi.com/api/openapi/v1/batch-reasoning-tasks/upload/upload-url`
请求参数:
参数名 | 类型 | 必填 | 描述 |
fileName | string | 是 | 上传文件名 |
projectId | string | 是 | 项目Id |
请求头:
参数名 | 值 | 必填 | 描述 |
Authorization | Bearer xxxxx | 是 | 认证令牌 |
响应结构:
{
"ResponseMeta": {
"RequestId": "string",
"HostId": "string",
"ErrorCode": "string",
"ErrorMessage": "string"
},
"ResponseData": {
"httpEndpoint": "string",
"fileToken": "string"
}
}
响应字段说明:
字段名 | 类型 | 描述 |
httpEndpoint | string | 文件上传的HTTP端点地址 |
fileToken | string | 文件上传凭证,用于后续文件上传操作 |
3. 上传文件
接口地址: `POST http://upload.kuaishouzt.com/api/upload`
请求参数:
参数名 | 类型 | 必填 | 描述 |
upload_token | string | 是 | 上传凭证 (同前文fileToken) |
请求头:
参数名 | 值 |
Content-Type | application/octet-stream |
请求体:
参数类型 | 值 |
data-binary | 文件 |
响应结构:
- 返回200即成功
{
"result": 1
}
- 非200即上传失败
4. 创建批量推理任务
接口地址: `POST https://wanqing.streamlakeapi.com/api/openapi/v1/batch-reasoning-tasks`
请求体:
{
"name": "string", //任务名【必填,项目下唯一】
"projectId": "string", //项目Id【必填】
"modelInstanceId": "string", //模型实例Id【必填】
"accessType": "string", //模型类型【必填,当前仅支持PUBLIC】
"fileToken": "string", //上传file token【必填,同前文fileToken】
"fileName": "string", //上传文件名【必填,仅用于用户上传文件前端展示以及后续文件下载,只要满足.jsonl后缀,没有前置依赖】
"maxWaitTime": "number" //最长等待时间【必填,单位为秒(s)最短设置1天(86400),最长28天(2419200)】
}
响应结构:
{
"ResponseMeta": {
"RequestId": "string",
"HostId": "string",
"ErrorCode": "string",
"ErrorMessage": "string"
},
"ResponseData": {
"id": "string"
}
}
响应字段说明:
字段名 | 类型 | 描述 |
id | string | 批量推理任务ID,用于后续查询任务状态和获取结果 |
5. 查询任务状态
接口地址: `GET https://wanqing.streamlakeapi.com/api/openapi/v1/projects/{projectId}/batch-reasoning-tasks/{taskId}`
响应字段说明:
字段名 | 类型 | 描述 |
status | string | 任务状态: pending/running/succeeded/failed |
progress.totalCount | number | 总任务数 |
progress.succeededCount | number | 成功任务数 |
progress.failedCount | number | 失败任务数 |
progress.runningDuration | string | 运行时长(秒) |
6. 获取输出文件Url
接口地址: `GET https://wanqing.streamlakeapi.com/api/openapi/v1/projects/{projectId}/batch-reasoning-tasks/{taskId}/download-url`
请求参数:
参数名 | 类型 | 必填 | 描述 |
projectId | string | 是 | 项目ID |
taskId | string | 是 | 任务ID |
status | string | 是 | 文件类型"output":输出文件 |
响应结构:
{
"ResponseMeta": {
"RequestId": "string",
"HostId": "string",
"ErrorCode": "string",
"ErrorMessage": "string"
},
"ResponseData": {
"fileUrl": "string"
}
}
响应字段说明:
- 如果任务完成并输出成功返回:
字段名 | 类型 | 描述 |
fileUrl | string | 推理结果文件的下载链接,可直接访问下载文件 【如任务未完成,fileUrl返回为空】 |
数据结构定义
ModelInstance 结构体
{
"name": "GPT-4 Turbo", // 模型名称
"description": "OpenAI's most advanced language model", // 模型描述
"modelId": "gpt-4-turbo-2024-04-09", // 模型唯一标识符
"vendorName": "OpenAI", // 供应商/厂商名称
"icon": "https://example.com/icons/gpt4.png", // 模型图标URL
"modelFamily": "GPT-4", // 模型系列/家族
"familyModelCount": 5, // 该系列中的模型数量
"visibleModelTags": { // 可见的模型标签(用于前端展示)
"modelTypes": ["Large Language Model", "Multimodal"], // 模型类型
"realContextLength": ["128K"] // 实际上下文长度标签
},
"invisibleModelTags": { // 不可见的模型标签(内部使用)
"customTags": ["production-ready", "enterprise"], // 自定义标签
"supportApiProtocols": ["OpenAI"], // 支持的API协议
"contextLengthTypes": ["32k以上"], // 上下文长度类型
"capabilities": [] // 模型能力列表
},
"accessType": "PUBLIC", // 访问类型(公有模型PUBLIC)
"introduction": [ // 模型介绍信息数组
{
"title": "Overview", // 介绍标题
"content": "GPT-4 Turbo is our most capable model" // 介绍内容
},
{
"title": "Key Features", // 特性标题
"content": "Supports 128K context window" // 特性内容
}
],
"tokenLimit": { // Token限制信息
"maxTokens": "4096", // 最大总Token数
"maxInputTokens": "128000", // 最大输入Token数
"maxOutputTokens": "4096", // 最大输出Token数
"maxThinkingTokens": "32768", // 最大思考Token数(用于推理模型)
"contextLength": "128000", // 上下文窗口长度
"tpm": "2000000", // 每分钟Token限制 (Tokens Per Minute)
"rpm": "10000", // 每分钟请求限制 (Requests Per Minute)
"tpd": "100000000" // 每天Token限制 (Tokens Per Day)
},
"capabilityOverview": { // 能力概览
"inputs": ["text", "image"], // 支持的输入类型
"outputs": ["text", "json"], // 支持的输出类型
"canFunctionCall": true, // 是否支持函数调用
"canExperience": true // 是否可以体验/试用
},
"priceInfo": [ // 价格信息数组
{
"usageScene": "onlineInference", // 使用场景
"inputRange": [0, 1000000], // 输入Token范围
"outputRange": [0, 1000000], // 输出Token范围
"pricingType": "fixed", // 定价类型
"pricingTiers": [ // 定价层级
{
"tierName": "default", // 层级名称
"input": 0.01, // 输入价格(每1K tokens)
"output": [ // 输出价格数组
{
"mode": "thinking", // 输出模式(完成模式)
"price": 0.03 // 价格(每1K tokens)
},
{
"mode": "normal", // 输出模式(流式模式)
"price": 0.03 // 价格(每1K tokens)
}
],
}
]
}
],
"storageInfo": { // 存储信息
"storageType": "cloud", // 存储类型(cloud/local/hybrid)
"storageUrl": "https://storage.example.com/models" // 存储URL
},
"recommendedQuestions": [ // 推荐问题列表
"Explain quantum computing in simple terms",
"Write a Python function to sort a list",
"Analyze this image and describe what you see"
],
"createdAt": "2024-04-09T10:00:00Z", // 创建时间
"updatedAt": "2024-11-15T14:30:00Z", // 更新时间
"modelInstance": { // 模型实例详情
"modelInstanceId": "mi-gpt4-turbo-001", // 模型实例ID
"modelInstanceName": "GPT-4 Turbo Production", // 模型实例名称
"modelServiceName": "openai-api-service", // 模型服务名称
"deploymentType": "cloud", // 部署类型(cloud/on-premise/edge)
"modelRegion": "us-west-2", // 模型部署区域
"description": "Production deployment", // 实例描述
"status": "running", // 实例状态(running/stopped/error)
"capabilityInfo": { // 实例能力信息
"contextLength": "128000", // 上下文长度
"maxTokens": "4096", // 最大Token数
"deepThinkable": true, // 是否支持深度思考
"modelParameters": [ // 模型参数配置
{
"type": "float", // 参数类型
"name": "temperature", // 参数名称
"displayName": "Temperature", // 显示名称
"min": 0, // 最小值
"max": 2, // 最大值
"defaultValue": 1, // 默认值
"step": 0.1, // 步进值
"description": "Controls randomness" // 参数描述
},
{
"type": "float",
"name": "top_p",
"displayName": "Top P",
"min": 0,
"max": 1,
"defaultValue": 1,
"step": 0.01,
"description": "Nucleus sampling threshold"
}
],
"greetingMessage": "Hello! How can I assist you?", // 欢迎消息
"guidanceContent": "I can help with various tasks", // 引导内容
"suggestedQuerys": [ // 建议查询
{
"title": "Code Generation", // 查询标题
"query": "Write a Python function", // 查询示例
"content": [ // 相关内容提示
"Generate efficient code",
"Include error handling",
"Add documentation"
]
}
]
},
"spec": { // 规格配置
"replicas": 3, // 副本数量
"image": "openai/gpt-4-turbo:latest", // 容器镜像
"deviceType": "GPU", // 设备类型(GPU/CPU/TPU)
"cpu": "16", // CPU核心数
"memory": "64Gi", // 内存大小
"engineConfig": { // 引擎配置
"type": "transformer", // 引擎类型
"tensorParallelSize": 4, // 张量并行大小
"pipelineParallelSize": 2, // 流水线并行大小
"customArgs": "--enable-flash-attention" // 自定义参数
},
"env": { // 环境变量
"CUDA_VISIBLE_DEVICES": "0,1,2,3", // CUDA设备配置
"MODEL_CACHE_DIR": "/cache/models" // 模型缓存目录
},
"multimodality": { // 多模态配置
"vision": { // 视觉能力配置
"enabled": true, // 是否启用
"maxImageSize": "20MB", // 最大图片大小
"supportedFormats": ["jpeg", "png", "webp"] // 支持的图片格式
}
}
},
"createdAt": "2024-04-09T10:00:00Z", // 实例创建时间
"updatedAt": "2024-11-15T14:30:00Z" // 实例更新时间
}
}
BatchReasoningTask 结构体
{
"name": "Customer Sentiment Analysis Batch", // 批量任务名称
"description": "Batch processing of customer reviews", // 批量任务描述
"tags": { // 标签信息
"department": "customer-service", // 部门标签
"priority": "high", // 优先级
"category": "sentiment-analysis" // 任务类别
},
"id": "batch-task-20241115-001", // 任务唯一标识符
"projectId": "proj-cs-analytics-2024", // 所属项目ID
"projectInfo": { // 项目详细信息
"projectName": "Customer Analytics Platform", // 项目名称
},
"createdBy": { // 创建者信息
"userId": "user-12345", // 用户ID
"userRole": "data-scientist", // 用户角色
"itTenantId": "tenant-abc123", // IT租户ID
"userName": "John Smith" // 用户名称
},
"createdAt": "2024-11-15T10:30:00Z", // 创建时间
"updatedBy": { // 最后更新者信息
"userId": "user-12345", // 用户ID
"userRole": "user", // 用户角色
"itTenantId": "tenant-abc123", // 主账号租户ID
"userName": "John Smith" // 用户名称
},
"updatedAt": "2024-11-15T14:45:00Z", // 最后更新时间
"modelInfo": { // 模型信息
"modelId": "gpt-4-turbo-2024", // 模型ID
"modelName": "GPT-4 Turbo", // 模型名称
"modelInstanceId": "mi-gpt4-prod-001", // 模型实例ID
"modelInstanceName": "GPT-4 Production Instance", // 模型实例名称
"modelServiceName": "openai-service", // 模型服务名称
"accessType": "API", // 访问类型(API/SDK)
"deploymentType": "cloud", // 部署类型(cloud/on-premise)
"modelRegion": "us-west-2", // 模型部署区域
"loraId": "lora-sentiment-v2", // LoRA适配器ID(如果使用)
"canExperience": true, // 是否可以体验
"supportApiProtocols": "OpenAI" // 支持的API协议
},
"maxWaitTime": 3600, // 最大等待时间(秒)
"authorizations": { // 授权信息
"apiKey": "sk-proj-xxxxx", // API密钥
"accessLevel": "full", // 访问级别
"quotaLimit": 1000000 // 配额限制
},
"inputDataFile": { // 输入数据文件信息
"file": { // 文件详情
"fileName": "customer_reviews_batch_20241115.jsonl" // 文件名
},
"expiredAt": "2024-11-22T10:30:00Z" // 文件过期时间
},
"outputDataFile": { // 输出数据文件信息
"file": { // 文件详情
"fileName": "sentiment_results_20241115.jsonl" // 文件名
},
"expiredAt": "2024-11-22T14:45:00Z" // 文件过期时间
},
"status": "running", // 任务状态(pending/running/completed/failed)
"errorReason": "", // 错误原因(如果有错误)
"progress": { // 进度信息
"startedAt": "2024-11-15T10:35:00Z", // 开始时间
"endedAt": "", // 结束时间(运行中为空)
"runningDuration": "4h10m", // 运行时长
"totalCount": 10000, // 总任务数
"succeededCount": 7500, // 成功数量
"failedCount": 23 // 失败数量
},
"defaultTokenLimit": { // 默认Token限制
"maxInputTokens": 2048, // 最大输入Token数
"maxOutputTokens": 512, // 最大输出Token数
"maxTotalTokens": 2560 // 最大总Token数
}
}
任务状态说明
状态 | 描述 | 说明 |
pending | 等待中 | 任务已创建,等待开始执行 |
running | 运行中 | 任务正在执行推理 |
succeeded | 成功 | 任务执行完成,所有推理成功 |
failed | 失败 | 任务执行失败,需要查看错误原因 |