
KAT 前端生成与美学评估白皮书
摘要
KAT-Coder-Pro V2 是快手自研的前端美学生成模型,面向 Landing Page 与 PPT 两大核心场景。其核心愿景是打破专业设计门槛,赋能千万中小商家与创作者,用自然语言即可生成高转化率的商业级页面。本报告从以下维度展开技术说明:用户自然语言输入的挑战、口语-美学映射体系的构建、标签体系的三位一体设计框架、训练数据工程,以及完整的评测 Benchmark 方法论与竞品横向对比结论。
核心数据
PPT 场景:
- KAT 标准化总分 57.6 分,领先 GLM 14.8 分,领先 Kimi 22.8 分;
- 配色维度(78 分)领先竞品 22~30 分,图片维度(48 分)是竞品的约 5 倍(vs GLM)和 8 倍(vs Kimi)
Landing Page 场景:
- KAT 标准化总分 59.8 分,综合排名第一(领先第二名 2.2 分);
- 配色(+10 分)、元素(+8~+12 分)、布局(+4~+8 分)三个维度建立核心优势
代际跃升:
- KAT 从基线版本(上一代)到最新版本,PPT 场景均分翻倍提升(+103%),LP 场景均分提升 42%
美学展示
Landing Page页面(同case页面) |
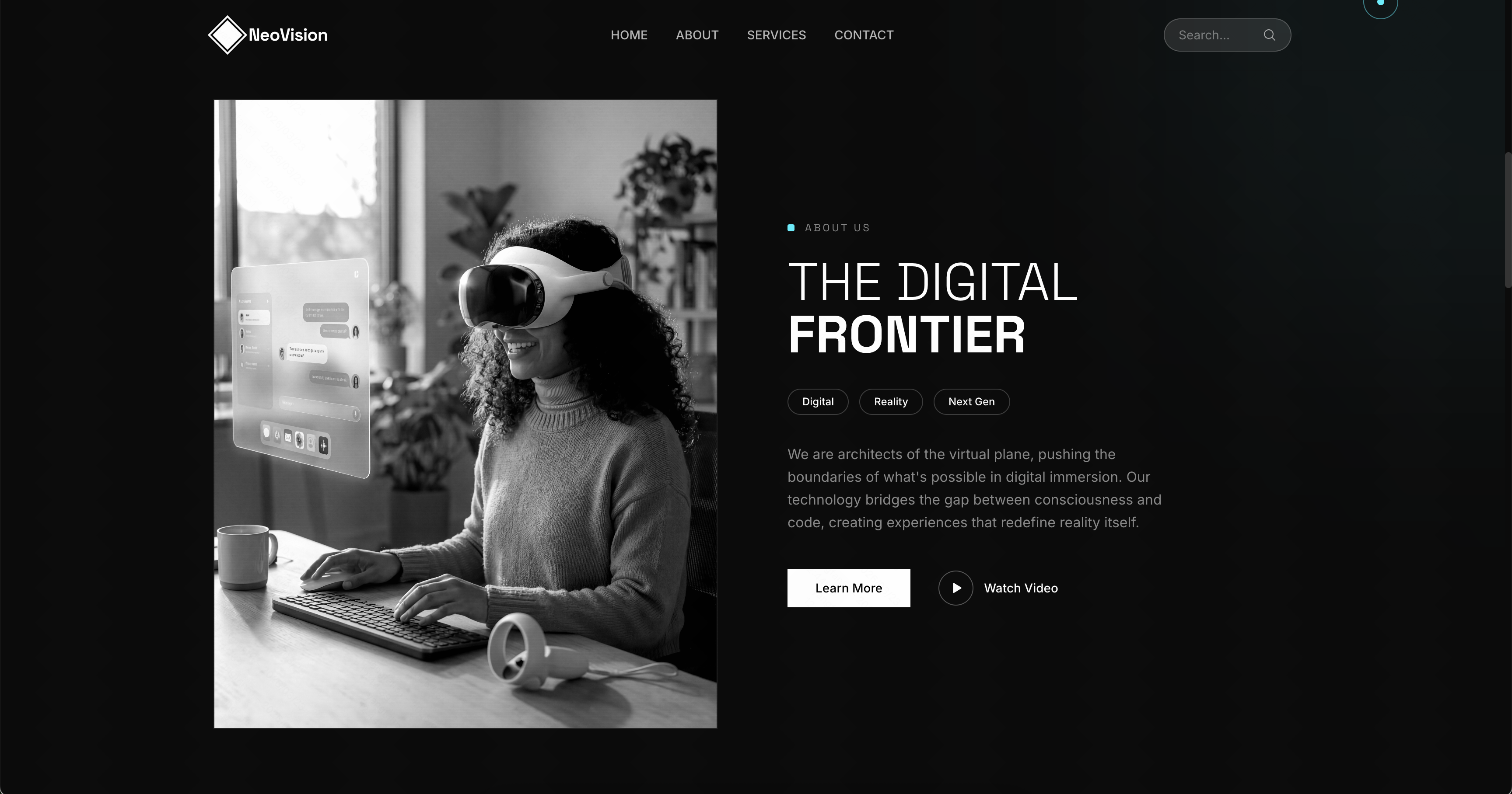
PPT页面(不同case页面) |



一、问题起点:用户是怎么说话的
1.1 真实用户的输入长什么样
在构建 KAT 评测体系之初,我们做了一项基础性的用户输入研究。通过收集真实使用场景下的 Prompt 样本,我们发现用户输入可以清晰地划分为三种类型,覆盖从完全口语到完整 spec 的连续谱系:
▌ 第一类:普通用户(口语)
没有设计背景,以情绪、场景、比喻驱动描述:
- "我们公司是做潮牌的,帮我做一个官网首页。要很酷很街头的那种感觉,像那些国际大牌一样。颜色深一点,黑色系的,图片要大,有点冲击力。按钮什么的别太普通,要有那种点进去的欲望。"
- "做个活动页,双十一的,要喜庆热闹,大红色,数字要大要亮,感觉赚到了一样。顶部放个倒计时,下面是商品,看着就想点。"
▌ 第二类:专业用户(口语)
有设计或产品背景,能使用部分专业词汇,但仍以自然语言描述,不写完整 spec:
- "这是一个 SaaS 产品的落地页。整体走简洁的商务风,主色用品牌蓝,首屏要有一个强有力的 Hero 区,突出核心卖点。下面跟功能介绍、用户证言、CTA,结构清晰,交互要流畅。字体别用默认字体,显得更专业一点。"
- "游戏推广页,赛博朋克风格,深色背景加荧光色强调。首屏全屏背景图,叠加标题和下载按钮。往下是角色介绍,卡片式布局,有 hover 动效。整体要有科技感,入场动画别太夸张。"
▌ 第三类:专业用户(spec)
提供全面的结构化规范,覆盖商业、设计、技术三个视角,且输入格式往往不是自然语言,而是 JSON、Markdown、表格等结构化格式。
spec 的内容通常包含以下一个或多个层次:
【商业与营销视角】完整的文案与信息架构
- 首屏标题:"让每一次创作,都值得被看见"
- 副标题:"KAT 智能设计引擎,10 秒生成专业级落地页"
- CTA 按钮文案:"免费开始创作" / "查看案例"
- 功能模块三项:智能排版 / 配色系统 / 一键导出,每项附 40 字以内描述
- 用户证言:3 条,附头像/姓名/职位
【视觉与交互视角】精确的 UI/UX 规范
- 设计 Token:主色 #1A1A2E、强调色 #E94560、圆角 8px、阴影 0 4px 16px rgba(0,0,0,0.12)
- 字体系统:标题 Bebas Neue 72px/加粗,正文 PingFang SC 16px/常规,行高 1.6
- 动效规范:入场动效从下向上淡入 0.6s ease-out,按钮延迟 0.3s 出现,hover 颜色加深 10%
【工程与实现视角】明确的工程实现约束
- 开发框架:React 18 + TypeScript,CSS 使用 Tailwind CSS
- 组件库:基于 shadcn/ui,按钮、卡片、表单全部使用该库的组件规范
- 响应式断点:mobile 375px / tablet 768px / desktop 1440px
- 性能要求:首屏加载 < 2s,图片懒加载,动效使用 CSS transform 不用 JS
【格式举例】spec 用户常用的结构化输入格式:
Markdown 格式:
## 页面结构
- Hero: 全屏背景图 + 主标题 + 副标题 + 双 CTA
- Features: 三列图标卡片,标题+描述
- Testimonials: 轮播,3条用户评价
JSON 格式:
{
"theme": { "primary": "#1A1A2E", "accent": "#E94560" },
"sections": [
{ "type": "hero", "headline": "让每一次创作都值得被看见",
"cta": [{"label":"免费开始","variant":"filled"},
{"label":"查看案例","variant":"outlined"}] }
],
"framework": "react",
"cssFramework": "tailwind"
}
三类输入描述的可以是完全相同的需求,但信息密度、覆盖维度和模型推断负担差距悬殊。spec 用户的输入不只是减少了歧义,更是从商业/设计/技术三个角度同时收窄了模型的解空间。
1.2 三类输入的本质挑战
三类用户对模型提出的挑战,在性质上不同,不只是难度的高低差异:
类型 | 语义解码 | 设计推断 | 技术推断 | 商业推断 | 核心挑战 |
普通用户(口语) | 极高 | 极高 | 高 | 高 | 情绪词/比喻/场景 → 全维度美学决策 |
专业用户(口语) | 中 | 中 | 高 | 中 | 补全缺失的系统规范 没有 spec 约束兜底 |
专业用户(spec) | 低 | 低 | 低 | 低 | 严格执行规范 保持各维度的高还原度 |
说明:
- 语义解码:理解用户意图,把模糊描述转化为明确需求
- 设计推断:从已知信息推导出完整的视觉与交互决策(配色/排版/字体/动效)
- 技术推断:决定使用什么框架/组件库/CSS 实现方案
- 商业推断:补全页面所需的文案、转化漏斗、信息结构、各模块的具体内容
spec 用户明确指定了框架(React/Vue)、组件库(shadcn/Ant Design)、响应式断点等,因此技术推断量也显著低于前两类。商业推断同样是:spec 用户往往附带完整的 CTA 策略和信息架构,模型不需要「编造」页面内容。
这构成了前端美学生成的核心语义鸿沟:用户语言的模糊性 vs. 设计实现的精确性。
KAT 的目标是让普通用户(口语)也能获得接近专业用户(spec)的输出质量。
1.3 三类用户的体量分布与转化现实
▌ 用户体量:一个倒金字塔结构
三类用户在真实市场中的分布,呈现出明显的倒金字塔形态:
普通用户(口语) ████████████████████████████████ 绝大多数
专业用户(口语) ████████████ 少数
专业用户(spec) ████ 极少数
普通用户(口语)
- 覆盖人群:所有「需要一个页面但没有设计/开发背景」的人——个体商家、创业者、运营人员、销售、自媒体博主、学生等
- 核心特征:他们知道「我要什么感觉」,但不知道「怎么实现」
- 市场体量:中国互联网环境中,这一群体的潜在规模在亿级以上
专业用户(口语)
- 覆盖人群:设计师、产品经理、有一定审美积累的运营、对技术有了解的创业者
- 核心特征:能用不同职能的专业语言描述需求,但日常工作中不写完整 spec——写 spec本身就是一项费时费力的专业工作,大多数专业人士也不会为每个需求都写完整的文档
- 市场体量:百万量级,远小于普通用户群体
专业用户(spec)
- 覆盖人群:资深设计师、前端架构师、已有完整设计系统的成熟团队
- 核心特征:需同时具备「商业与营销 + UI/UX + 工程实现」三个专业视角,才能写出覆盖完整维度的 spec;三种能力各需独立积累,极少集中于同一人
- 市场体量:三类中最小的群体,潜在规模不足口语用户的 1%
▌ 为什么普通用户无法「学会写 spec」
直觉上看,一个显而易见的解法是:「教用户写更好的 Prompt」或「提供 spec 模板让用户填写」。但这条路在现实中行不通,原因是结构性的:
① 写 spec 的前提是「已经完成了设计决策」
spec 用户之所以能写出「主色 #1A1A2E,强调色 #E94560,入场动效 0.6s ease-out」,是因为他们在写之前已经在头脑中完成了整套视觉决策——这些决策本身就是专业工作的输出,是数年设计训练积累的结果。要求普通用户直接填写 spec,相当于要求他「先成为设计师,再使用工具」。但普通用户使用这类工具的动机,恰恰是「因为我不是设计师」。
② 三个专业领域的复合壁垒,一份完整的 spec 实际上要求用户同时具备三种专业视角:
- 商业与营销视角:信息架构、转化漏斗设计、CTA(行动号召)策略、文案说服力
- 视觉与交互视角(UI/UX):色彩理论、字体排印、栅格系统、微交互与动效规范
- 工程与实现视角:前端框架选型、CSS 属性映射、响应式断点、组件库约束
每一项都需要独立的专业积累。要求普通用户同时掌握这三项,等同于要求他一个人扮演「产品运营 + UI/UX设计师 + 前端工程师」的完整产研团队角色。
③ 行业数据印证:Prompt 优化的用户渗透率极低
AI 产品领域的普遍观察:能够主动、持续优化 Prompt 的用户比例通常低于5%。市场上已存在大量「Prompt 教学」内容,但用户的实际使用行为并没有因此发生根本性改变。用户倾向于「直接说想要什么」,而不是「先学习如何正确地描述需求」。
④ 核心悖论:能写 spec 的用户不需要 AI 生成工具
如果一个用户真的有能力写出完整的商业 + 设计 + 技术 spec,他很可能已经有了获取高质量页面的其他途径——直接雇设计师/开发者、使用专业设计工具(Figma + 代码实现)、或者自己动手。spec 用户选择使用 AI 生成工具,动机通常是「快速原型验证」或「提升已有工作流的效率」,而非「因为我不会做」。他们是效率用户,不是依赖用户。
▌ 正确的产品逻辑:提升模型能力,而非改造用户行为
以上分析得出一个清晰的结论:
- 「教用户变成 spec 用户」是一条成本极高、收益极低、现实中行不通的路径。真正的产品价值,是让模型拥有足够强的口语-美学映射能力,使普通用户(口语)的输入,能稳定产出接近专业用户(spec)水平的输出质量。
- 这正是 KAT 美学能力建设的核心命题——不是降低用户的表达门槛,而是提升模型对低信息密度输入的理解与补全能力。
- 如果这个能力真正做到,市场空间将从「口语用户 1% 量级以内的 spec 用户」扩展到「亿级的普通用户」,是一次真正意义上的目标用户规模跃迁。
二、口语输入如何直接影响美学输出质量
2.1 为什么用户感受上"很差"
当模型无法有效处理口语输入时,最常见的两类失败模式:
▌ 第一类:语义漂移
- 用户说"喜庆热闹",模型只捕捉到"红色"这一字面关键词,输出了大面积单一红色填充,缺少金色强调色、渐变背景的层次感、数字动效的烘托。用户看到的是"刺眼"而非"喜庆"。
- 核心原因:模型将情绪词降维成了单一的视觉属性(颜色),而没有将其还原为一套协同的美学决策(配色体系 + 布局节奏 + 动效强度)。
▌ 第二类:维度缺失
- 用户说"SaaS 产品,整体走简洁商务风",模型正确输出了蓝白配色,但页面布局仍是堆砌式的单列结构,没有合理的 Hero 区视觉焦点,没有功能区块的空间呼吸感,字体仍是系统默认宋体。用户感受是"配色看着还行,但整体很廉价"。
- 核心原因:口语输入涉及的审美意图,被分散在布局、排版、配色、字体、元素、动效等多个维度中,而模型只响应了「有显式对应」的维度(配色),忽略了需要从场景推断的隐性维度(布局节奏、字体选型)。
- 用户的主观感受是"不好看",真正的技术原因是:缺乏将整体语义统一映射到多维度协同输出的能力。
2.2 核心瓶颈:输入降维带来的「美学折损」
在前端生成领域有一个行业共识:提供完整 spec 的专业输入,其生成的页面质量远高于模糊的口语输入。这种差异的本质,是输入信息降维带来的系统性「美学折损」。
当模型面对专业用户的 spec 时,它执行的是「精确还原」任务,有明确的边界和坐标;而面对普通用户的口语(如"高端大气的商务风")时,由于缺乏具体的色彩、排版、动效约束,通用大模型在推断时往往会退回到一种"最安全的平均态"——为了不出错,只能使用最保守的蓝白配色、系统默认字体和基础的单列栅格。
这种"安全但平庸"的退化,导致普通用户的输出结果被死死锁在了"勉强及格"的区间。无论底层的代码渲染能力有多强,只要前端缺乏对模糊语义的结构化推导,最终的页面就无法触及真正的专业设计水准。
这意味着:当前美学生成的最大瓶颈,不在于代码渲染引擎的细微优化,而在于如何跨越「口语-美学映射」的语义鸿沟。如果能让普通用户的口语输入,也能逼近 spec 输入的美学上限,其带来的整体质量跃升,将远大于单纯在某个单一技术维度(如排版或动效)上做微调的收益。
这也是 KAT 投入核心资源攻坚「三位一体标签体系」(见第三章)的根本原因。
三、标签体系:三位一体的架构设计
3.1 为什么需要标签体系
直接让语言模型从口语 Prompt 生成 HTML/CSS 存在两个结构性问题:
① 路径过长
- 从"酷酷的街头感"到 background: #0A0A0A; font-family: 'Bebas Neue'; animation: slideIn 0.6s ease-out; 需要跨越语义理解、设计决策、工程实现三个层次,单步端到端跳跃的错误率极高。
② 可干预性差
- 端到端映射是黑箱。当输出不理想时,无法定位根因——是语义理解出了问题、设计决策出了问题,还是代码实现出了问题?三层错误混在一起无从调优。
- 标签体系的核心价值是将这条链路显式化,把每一层的决策固化为可检验、可干预、可复用的结构化标签节点。
3.2 三位一体:贯穿全局的映射原则
「三位一体」不是三种独立的标签,而是一个贯穿整个标签体系所有层级的映射原则:对于每一个规范项,都同时维护三个视角的表述。
[用户感受] ──→ 用户会怎么描述这个效果(口语化,无需专业背景) ↓ 映射 [设计原理] ──→ 设计师用什么专业概念来定义这个效果 ↓ 映射 [技术实现] ──→ 工程师用什么代码/属性来实现这个效果
举例:同一个配色规范的三个视角表述:
[用户感受]:主要是黑白,但突然会出现很刺眼的黄绿色或亮橙色,非常醒目
[设计原理]:酸性波普(Acid Pop)配色逻辑。以绝对黑为底色,高饱和度酸性色(Acid Lime, Safety Orange)作为视觉锚点,制造冲击力
[技术实现]:Base: bg-black/text-white; Accents: bg-[#E2F05D], bg-[#F25C05]
这个映射原则解决了三类用户输入的差异问题——无论用户是口语描述还是给出 spec,标签体系都能在对应的视角层找到锚点,然后向上下两层推导补全。
3.3 标签框架的完整层级:从粗到细
整个标签框架按粒度由粗到细分为七层。其中第三至第五层都属于「全局层」,分别从视觉、交互动效、排版三个专业方向定义贯穿全页面的统一规范:
层级 | 名称 | 粒度 | 核心问题 |
引导层 | |||
第一层 | 风格标签 | 最粗 | 这个页面整体是什么风格? |
第二层 | 摘要(业务信息) | 粗 | 这个页面给谁看?要达到什么目的? |
全局层(三层) | |||
第三层 | 全局视觉规范 | 中 | 整个页面的色彩/字体/图标/组件体系是什么? |
第四层 | 全局交互动效规范 | 中 | 整个页面的交互反馈和动效体系是什么? |
第五层 | 全局排版规范 | 中 | 整个页面的栅格/信息层级/间距体系是什么 |
模块层 + 工程层 | |||
第六层 | 模块级规范 | 细 | 每个具体区块的布局/视觉/交互是什么? |
第七层 | 技术实现规范 | 最细 | 用什么框架、库、代码约束来实现? |
▌ 第一层:风格标签(索引锚点)
风格标签是整个标签体系的入口,用五个字段快速定性一个页面的整体风格调性:
- style_name(风格命名):给风格一个具有辨识度的专业名称
示例:Digital Editorial Brutalism(数字编辑野兽派)
- style_user_impression(用户感受):用最接近目标用户的口语描述这个风格
示例:就像在看一本高端的时尚艺术杂志,但是是互动的。排版非常大胆,字很大,颜色对比强烈,既有复古的网格纸质感,又有很酷的磨砂玻璃效果。
- style_animation_vibe(动效氛围):专项描述这个风格的整体动态感受
示例:像幻灯片切换一样利落,配合视差滚动,有一种"慢动作重力"的滞后感
- palette_hex(色板快速索引):风格的核心调色盘,以 HEX 值快速标注
示例:#000000 (Black), #E2F05D (Acid Lime), #F25C05 (International Orange)
作用:作为后续全局视觉规范色彩系统的快速参照,便于跨模块复用和一致性校验
- ui_framework(技术框架快速索引):整个页面首选的 CSS/UI 框架
示例:Tailwind CSS
作用:在第一层就锁定实现路线,确保全局规范和模块规范中的技术实现字段都对齐到同一技术栈,避免混用冲突
风格标签的作用:一旦命名,它成为整个标签体系的索引键,同类风格的全局规范可以复用,不需要每次从零构建。palette_hex 与 ui_framework 是两个快速索引字段,在后续层级中会被详细展开。
▌ 第二层:摘要(业务信息)
摘要层是页面的业务上下文,决定了所有后续设计决策的「服务对象」和「目标」。包含以下字段:
- 页面主要语言:页面的内容语言(中文/英文/双语)
作用:直接影响字体选型、排版规范和字体回退栈的选择
示例:English
- 排版特征(高层级摘要):对整体排版风格的一句话描述
作用:在进入详细规范之前,给模型一个高层级的排版方向锚点
示例:标题紧凑(tracking-tight),正文舒适(relaxed),混合字体排印(Serif 与 Sans-serif 混用)
- 页面目标:这个页面要达到什么商业结果
示例:展示年度设计趋势报告,引导用户订阅或深度阅读
- 受众画像:目标用户是谁,有什么特征和期望
示例:UI/UX 设计师、创意总监、前端开发者、数字营销人员
- 一句话价值主张:首屏核心传递的信息
示例: WEB DESIGN IN 2021: The Report.
- 核心卖点:3 条支撑价值主张的具体内容
- 信任要素:背书、数据、评价等建立信任的内容
示例:"By Editor X"(知名设计工具品牌背书)
- 行动按钮文案:主 CTA 和次 CTA 的具体文字
示例:主按钮:Subscribe;次按钮:Customize
摘要层是「内容视角」的主要来源。对于普通用户(口语)而言,摘要层的大部分字段需要从口语描述中提取或推断;对于 spec 用户,这些字段通常已被完整提供。「页面主要语言」和「排版特征」是两个前置定向字段,优先级高于其他内容字段。
▌ 第三层:全局视觉规范(三位一体)
全局视觉规范定义贯穿整个页面的视觉语言体系。每一项都用三位一体原则表述:
- 视觉一致性:整体排版风格与主视觉逻辑
- 色彩系统:主色 / 辅助色 / 强调色体系(含 HEX 值和应用规则)
- 字体系统:标题字体 / 正文字体 / 字号层级 / 行高 / 字重
- 图标系统:图标风格 / 图标库选型 / 大小规范
- 组件系统:按钮 / 卡片 / 表单的统一视觉规范(圆角/阴影/边框)
- 图像与装饰:图片风格、纹理、装饰元素的使用规范
示例(色彩系统的三位一体表述):
[用户感受]:主要是黑白,但突然会出现很刺眼的黄绿色,非常醒目
[设计原理]:酸性波普配色。绝对黑为底,高饱和度酸性色作视觉锚点
[技术实现]:bg-black/text-white; Accents: bg-[#E2F05D], bg-[#F25C05]
▌ 第四层:全局交互与动效规范(三位一体)
独立成层,定义整个页面的动态体验体系:
- 基础交互反馈(Hover/Active):鼠标悬停/点击/表单聚焦的视觉反馈规范
- 进场动画(Scroll Entry):元素滚入屏幕时的出现方式
- 持续动态(Ambient Motion):页面静默状态下的常驻动效(跑马灯、循环动画等)
示例(进场动画的三位一体表述):
- [用户感受]:滑下来的时候,大标题是慢慢滑进来的,图片像卡片一样叠上去
- [设计原理]:视差层叠(Parallax Stacking)。sticky 定位让侧边标题停留,内容区产生 Z 轴视差,模拟杂志翻页的物理质感
- [技术实现]: sticky top-0; animate-in slide-in-from-bottom; scroll-behavior: smooth
▌ 第五层:全局排版规范(三位一体)
与视觉规范、动效规范并列,独立成层,定义贯穿全页面的排版结构体系:
- 栅格与对齐:页面的列数、列宽比例、对齐规则(是否允许破格布局)
- 信息层级:字号的跨度(最大标题 vs 最小正文的比例关系)、层级数量
- 间距体系:模块间垂直间距、内边距节奏、密度风格(紧凑/舒适/宽松)
示例(栅格与对齐的三位一体表述):
- [用户感受]:有时候一边宽一边窄,文字经常压在图片上,感觉很有设计感
- [设计原理]:破格布局(Broken Grid)。在 12 栏栅格基础上有意打破对齐线,通过重叠(Overlapping)与错位(Off-set)创造视觉张力
- [技术实现]:grid-cols-12; col-span-4/col-span-8; -ml-10(负边距)
示例(间距体系的三位一体表述):
- [用户感受]:东西塞得满满的,没有太多空隙,很紧凑
- [设计原理]:密集排版(Dense Typography)。减少模块间垂直间距,利用分割线区分内容,营造高密度信息流体验
- [技术实现]:border-b border-black; py-8 / py-12(比常规更紧)
全局排版规范与视觉规范的关键区别:视觉规范管「颜色/字体/图标是什么」,排版规范管「它们之间的空间关系和信息组织逻辑是什么」。两者共同构成全局设计语言,缺一不可。
▌ 第六层:模块级规范(三位一体 × 逐模块)
模块级规范按页面实际区块顺序逐一定义,是粒度最细的设计层。每个模块包含:
- 模块目标:这个模块要完成什么业务/体验目标
- 排版规范:该模块的布局方式、字号、对齐、间距(三位一体)
- 视觉规范:该模块的背景色、图片风格、装饰元素(三位一体)
- 交互与动效:该模块特有的交互行为和动效(三位一体)
示例(Hero 模块的视觉规范三位一体):
- [用户感受]:背景是很淡的黄绿色,那几张卡片是半透明的,上面有刻度
- [设计原理]:玻璃拟态(Glassmorphism)应用。卡片使用高模糊度背景滤镜,模拟光学折射,叠加技术美学元素
- [技术实现]:bg-gradient-to-br from-[#EEF2C3] to-[#E2F05D];Cards: bg-white/30 backdrop-blur-xl border border-white/50
模块规范与全局规范的关系:模块规范在全局规范的约束下运作(继承全局色彩、字体、排版体系),但可以有局部变体——如某个模块用深色背景打破全局的浅色基调,或某个模块使用特殊的非常规布局强化视觉焦点。
▌ 第七层:技术实现规范(工程约束)
最后一层专门处理工程侧的实现约束,独立于设计决策之外:
- 技术栈:前端框架(React/Vue/原生 HTML)、CSS 方案(Tailwind/SCSS/内联)
- 图标与字体:具体的图标库(RemixIcon/FontAwesome)和字体加载方案
- 网络环境约束:CDN 选择(国内/国际)、字体回退栈
- 图片资源:图片来源(Unsplash URL、本地路径、占位图)
- 代码结构约束:必须包含的 `<style>` 块、`<script>` 逻辑、自定义动画
- 输出格式要求:纯净 HTML / 组件化 / 多文件等
示例:
- 技术栈:Tailwind CSS (CDN 引入)
- 图标:RemixIcon (国内 CDN)
- 字体栈:font-family: "Playfair Display", "Times New Roman", system-ui
- 图片:使用 Unsplash 真实 URL,禁止使用 picsum 等测试占位图
- 输出:只输出 HTML 代码,无需 Markdown 包裹
3.4 三位一体 × 七层框架:整体结构图
综合以上,完整的标签框架结构如下:
第一层:风格标签 | ||
style_name | style_user_impression | animation_vibe |
palette_hex | ui_framework | |
第二层:摘要(业务信息) | ||
页面语言 | 排版特征 | 页面目标 |
受众画像 | 价值主张 | 核心卖点 |
信任要素 | CTA文案 | |
第三层:全局视觉规范 | 第四层:全局交互动效规范 | 第五层:全局排版规范 |
色彩系统 | Hover/Active | 栅格与对齐 |
字体系统 | 进场动画 | 信息层级 |
图标系统 | 持续动态 | 间距体系 |
组件系统 | ||
图像/装饰 | ||
每项规范均使用三位一体表述: [用户感受] → [设计原理] → [技术实现] | ||
第六层:模块级规范(按页面区块顺序逐一定义) | ||
Hero | Features | Testimonials |
CTA | Footer | ... |
每个模块 = 模块目标 + 排版规范 + 视觉规范 + 交互动效 | ||
每项规范均使用三位一体表述: = [用户感受] → [设计原理] → [技术实现] | ||
第七层:技术实现规范 | ||
技术栈 | 图标库 | 字体回退栈 |
图片资源 | 代码结构 | 输出格式 |
全局三层(第三/四/五层)= 页面统一设计语言,三位一体原则全面运用
模块层(第六层)= 继承全局语言,逐区块落地,三位一体原则全面运用
技术层(第七层)= 工程约束,不涉及三位一体映射
3.5 三类用户的输入在框架中的落点
三类用户的输入,在七层框架中的填充程度不同,决定了模型需要补全的工作量:
层级 | 普通用户(口语) | 专业用户(口语) | 专业用户(spec) |
第一层 风格标签 | 模型需完整推断 | 通常可直接确定 | 直接给出 |
第二层 摘要 | 部分可提取 | 大部分可提取 | 完整提供 |
第三层 全局视觉 | 模型需全部推断 | 部分已知补全细节 | 精确给出 |
第四层 全局动效 | 模型需全部推断 | 通常已知动效强度 | 精确给出 |
第五层 全局排版 | 模型需全部推断 | 部分布局意图已知 | 精确给出 |
第六层 模块规范 | 模型需全部生成 | 结构意图已知补细节 | 可能已给出 |
第七层 技术规范 | 模型按默认选型 | 部分技术偏好已知 | 完整约束已给 |
普通用户(口语):模型需从少量口语输入推断并填写七层中的绝大多数字段 | |||
专业用户(口语):模型主要承担「补全」工作,将设计意图转译为完整规范 | |||
专业用户(spec):模型主要承担「执行」工作,精确将规范还原为高质量代码 | |||
无论哪类用户,标签体系的存在都使这个过程从黑箱变为可追踪、可调优的结构化推导——这是 KAT 区别于纯端到端生成方案的核心技术差异。
3.6 标签体系的工程落地:双层实现机制
三位一体标签框架并非停留在设计原则层,而是以串行两阶段的方式落地于训练管线:
▌ 第一阶段:数据生产——System Prompt 驱动 Teacher 模型标注
三位一体的映射规范以结构化形式嵌入 Teacher 大模型的 System Prompt。对于每条口语 Prompt,Teacher 模型在该规范约束下,依次在七层框架中展开推导——先确定风格标签和业务摘要,再推导三个全局规范层,最后逐模块落地并生成代码——产出带完整中间层标注的三段式训练样本:
口语 Prompt → 三位一体标签(七层填充) → HTML 输出
▌ 第二阶段:模型训练——以三段式数据固化推断路径
以上述三段式结构作为训练数据,使 KAT 模型不只是学习「输入→输出」的端到端映射,而是学习「如何从口语输入推导出结构化的美学决策,再从决策生成代码」的完整推断路径。标签层在训练中作为可监督的中间节点,让推断逻辑本身成为可学习的目标。
两个阶段形成闭环:
第一阶段用 System Prompt 将三位一体原则编码进训练数据的结构中,第二阶段将这套推断逻辑固化为 KAT 模型的内生能力。这正是 KAT 具备泛化能力的工程基础——模型掌握的是推断逻辑本身,而非特定样本的模板记忆。
3.7 训练数据工程:基于标签体系的数据扩增
数据构建的核心挑战高质量前端美学训练数据的稀缺性远超想象。原因在于:
- 网络上的 HTML 代码数量庞大,但美学质量合格的占比极低
- 设计评分需要专业设计师逐样本标注,成本高、周期长
- 同一 Prompt 需要多样化的高质量正样本,防止模型退化为单一模板
数据扩增策略:参数化变异
基于原始优质样本的参数化变异扩增方法:
- 配色变异:系统性替换主色/辅助色/强调色为色轮上合理的替代方案,保持设计规范前提下产生多样化配色
- 内容变异:替换文案内容、图片 URL、品类信息,覆盖不同行业和场景
- 结构变异:在保持整体布局的基础上,调整组件顺序、间距参数、排版配置
质量门控机制:每个变异样本需通过自动检测(色值替换完整性、HTML/TXT 对应一致性)和人工抽检(视觉效果不退化),才能进入训练集。
四、评测 Benchmark 设计
4.1 两个不同的问题:代码还原度 vs 美学还原度
在讨论 KAT Benchmark 的设计之前,必须先厘清前端生成领域存在的两个根本性问题。
▌ 什么是代码还原度
代码还原度,衡量的是:生成的 HTML/CSS 代码,在技术层面是否正确执行了给定的设计意图。它回答的核心问题是:「代码对不对?」
代码还原度的典型检测项包括:
- 元素是否正常渲染(没有报错、没有空白)
- 布局是否按照预期结构出现(非白屏、非长图)
- 组件是否可以正常交互(按钮响应、表单可用)
- 资源是否正确加载(图片不裂、字体不乱码)
代码还原度是一个二值性强的指标:要么渲染了,要么没有。它可以被自动化检测,且与视觉美感无关。
▌ 什么是美学还原度
美学还原度,衡量的是:生成的页面,在视觉层面是否达到了专业设计师认可的美学质量标准。它回答的核心问题是:「页面好不好看?」
美学还原度是一个连续性指标,无法被自动化检测,必须依赖具备专业判断力的评审者,从配色、布局、排版、元素、动效等多个维度综合评估。
▌ 两者的关系
差异项 | 代码还原度 | 美学还原度 |
核心问题 | 代码对不对 | 页面好不好看 |
检测方式 | 可自动化 | 需人工专家评审 |
评分特征 | 二值性强(有/无) | 连续性(百分制多维度评分) |
必要性 | 美学的前提条件 | 最终价值的度量 |
典型失败 | 白屏、报错、资源404 | 配色混乱、布局单调、无动效 |
两者的关系是:代码还原度是美学还原度的必要非充分条件。
代码崩溃的页面,美学一定失分(0 分);但代码完整渲染的页面,美学得分可以从最低分横跨至满分的整个区间。
我们在评测中发现,大量样本能正常渲染,但美学评分仍处于严重缺陷区间——这正是现有代码 Benchmark 无法覆盖的盲区。
▌ 现有 Benchmark 的局限
目前主流的前端代码生成评测(如 WebArena、HumanEval-Web、Design2Code)主要聚焦于代码还原度。
这些 Benchmark 有其合理性,但对于以美学生成为目标的模型而言,存在以下系统性缺口:
【局限一】参照物缺失:无 Ground Truth 可比对
现有代码 Benchmark 的基本范式是"给定参考设计 → 对比生成结果",本质上是一个还原度(Fidelity)任务。但 KAT 所面对的场景截然不同:
用户输入:「帮我做一个科技感十足、高端大气的 SaaS 产品官网」 参考设计:不存在
当输入是口语描述时,根本不存在一个可供像素级对比的 Ground Truth。评测的核心问题不是"和参考图有多像",而是"有没有达到专业设计师认可的美学标准"。
这是一个范式层面的错位——现有 Benchmark 的整体框架就不适用于这类任务。
【局限二】评测主体错配:算法无法替代设计师判断
现有 Benchmark 的评测主体通常是:
SSIM / LPIPS(像素级图像相似度算法)
CLIP Score(语义相似度模型)
代码执行测试(元素是否渲染、坐标是否正确)
这些方法的共同问题在于:它们衡量的是"与某个参考状态的距离",而非"是否达到了美学质量标准"。
反例:一个色彩搭配极佳、布局充满张力的破格设计,SSIM 分数可能很低(因为它"不像"常见布局),但设计师评分会很高。算法会系统性地惩罚原创性。
KAT 的选择:所有美学评分均由经过校准的专业设计师团队执行,并通过跨团队一致性检验保证评分稳定性(详见 4.6)。
【局限三】评测维度错配:静态截图无法捕捉动态体验
现有 Benchmark 的主流评测方式是:截一张截图,在图像层面进行对比或打分。
这个方式在评测「交互」和「动效」两个维度时会完全失效:
- Hover 状态的视觉反馈是否丰富、精准
- 元素进场动画是否有节奏感、层次感
- 跑马灯、视差滚动等持续动态是否正常运转
这两个维度在 KAT Landing Page 评测体系中占 2/10,在用户的主观感受中权重更高(动效往往是"好不好看"的第一印象来源)。
KAT 的选择:评审员在标准化浏览器环境中进行完整的交互操作,包括滚动、悬停、点击,而非仅凭截图评分(标准化渲染环境规范详见 4.8)。
【局限四】语义无法量化:口语意图的满足度不可被算法捕捉
代码 Benchmark 的得分反映的是"结构是否完整",但完全无法回答:
「这个页面是否传达出了'豪华感'?」
「这个页面是否符合'极简北欧风'的调性?」
「这个页面的配色是否与'活力运动品牌'的气质匹配?」
上述问题涉及的是「语义-美学映射」的质量——这正是 KAT 口语美学映射能力的核心评测对象,也是用户感受上"好不好用"的决定性因素。
CLIP Score 在一定程度上可以评估语义相关性,但它能处理的是"是否出现了猫",而不是"这张图是否有高端感"——这两类问题的难度不在同一个数量级上。
KAT 的选择:通过多维度的美学评分体系,间接量化"语义意图是否在视觉上被充分实现"——当配色、字体、元素、动效均达到高分,意味着语义映射成功。
【局限五】维度独立性问题:缺少跨维度协调性评估
现有代码 Benchmark 通常逐元素打分(这个按钮在不在、那段文字有没有),对各元素的联合审美效果缺乏评估。
但美学体验是一个整体性的涌现属性:
色彩系统与字体重量的协调性(暖色系配衬线体的古典感)
间距节奏与动效节奏的同步性(紧凑排版配合利落动效)
组件风格与整体调性的一致性(圆角按钮 vs 直角按钮对品牌感的影响)
任何一项单独评测都不能反映这个整体。一张在每个维度均处于中游得分的页面,和一张在配色/排版/动效三项高度协调而其余项普通的页面,用户感受可能截然不同。
KAT 的选择:10 维度独立评分 + 整体审阅的两阶段评审模式,捕捉维度间的协调效果(详见 4.6)。为保证评测的绝对客观性与跨模型可比性,当前版本采用 10 维度等权相加计算总分。
【局限六】奖励平庸效应:自动化指标系统性压制原创设计
由于现有自动化指标(SSIM、CLIP)的参照基准是"常见的页面样式",模型为了提分,会被隐性引导趋向"安全的平均态"——按钮要长得像大多数按钮,布局要接近大多数网站。
这从根本上与美学生成的目标背道而驰:KAT 的训练目标是生成具有鲜明风格、高辨识度的页面,而非平庸的及格品。
KAT 的选择:以"是否达到专业设计标准"为绝对评分基准,而非"是否接近参考图",5 分标准是"出彩无瑕疵"而非"最像某个平均值"。
【小结】:KAT Benchmark 针对上述六项局限的系统性回应
局限 | KAT 的回应 |
无 Ground Truth | 以专业美学标准为绝对参照,而非相对相似度 |
算法评测主体 | 专业设计师团队执行,校准后跨团队验证 |
静态截图局限 | 标准化浏览器环境 + 完整交互操作评审 |
语义无法量化 | 10 维度间接量化语义-美学映射质量 |
维度孤立评测 | 独立评分 + 整体协调性两阶段评审 |
奖励平庸效应 | 绝对质量基准,5 分 = 出彩,非"最像参考" |
KAT Benchmark 的设计初衷:
建立一套可量化、可重复、由设计专家执行的美学还原度评估体系,填补现有代码 Benchmark 在美学判断层面的系统性缺口。
4.2 业界 Benchmark 现状与 KAT 的行业站位
目前业界关于前端代码生成的 Benchmark 主要有以下几个代表流派:
- 交互逻辑派(如 WebArena / Mind2Web):侧重于 Agent 在网页上的操作和任务完成率,不关注页面生成的视觉质量。
- 像素临摹派(如斯坦福 HumanEval-Web / Design2Code):侧重于给定一张设计图,模型生成 HTML/CSS 的像素级相似度(通过 CLIP / SSIM / 元素匹配率评估)。
- 感性展示派(如 Vercel / v0 内部评测):未公开详细的量化标准,多为感性的 case 展示。
在此背景下,KAT Benchmark 确立了其独特的行业站位:
① 独特性(Uniqueness):填补「创作」空白
KAT 是目前业界唯一一个公开的、系统性的、针对"无参考图(Text-to-UI)"场景的纯美学 Benchmark。它填补了 Design2Code 只能测"临摹"不能测"创作"的行业空白。
② 维度颗粒度(Granularity):远超学术界现有标准
Design2Code 等通常只看整体相似度或大块布局。KAT 拆解出 10 个独立维度(连"动效"和"字体"都单独拆出),其颗粒度和专业度远超学术界现有的前端生成评测。
③ 评测范式(Paradigm):坚持专家人工评测
业界普遍追求"自动化评测"(因为成本低、速度快),KAT 逆势而行,坚持 "专家人工评测",并用强逻辑论证了"美学无法被算法自动化"的合理性。这在学术上可能显得"不够自动化",但在工业界和设计界确立了极高的公信力与认同感。
4.3 KAT 美学 Benchmark 的整体设计
KAT 将美学还原度拆解为 10 个独立维度(Landing Page 场景),覆盖从结构完整性到视觉细节的完整美学链路:
结构层 → 布局 · 排版
视觉层 → 配色 · 字体 · 图片 · 背景 · 元素
组件层 → 组件
动态层 → 交互 · 动效
每个维度在「代码还原度」和「美学还原度」之间的侧重:
维度 | 代码还原度侧重 | 美学还原度侧重 |
布局 | 元素不重叠、不截断 | 间距规律、视觉层次、空间节奏 |
排版 | 文字可读、不乱码 | 字号层级对比、行距节奏、轻重表达 |
配色 | 颜色正确渲染 | 主/辅/强调色三层体系完整性与和谐度 |
字体 | 字体正常加载 | 字体选型与场景匹配、中英文视觉重量协调 |
图片 | 图片正常显示 | 图片风格统一性、内容主题相关性 |
背景 | 背景正确渲染 | 区块区分度、渐变质量、前后景落差感 |
元素 | 图标正常加载 | 图标库统一性、SVG 绘制质量、Logo 还原准确度 |
组件 | 按钮/表单可用 | 组件规范一致性、主次层级视觉区分 |
交互 | 事件有响应 | 反馈视觉的丰富度与精准度 |
动效 | 动画不卡顿 | 动效序列设计、时间节奏、视觉吸引力 |
【测试集 Prompt 类型说明】
本 Benchmark 的测试集完全采用普通用户口语 Prompt,即第一章定义的「第一类:普通用户(口语)」——以情绪、场景、比喻驱动描述,不包含设计规范(如色值、字号)和工程约束(如框架、响应式断点)。
这一选择是有意为之,直接对应 KAT 的核心命题:模型在低信息密度的口语输入下,能否稳定产出接近专业水准的美学输出。以 spec Prompt 进行测试无法验证这一能力——spec 输入本质上已经替模型完成了设计决策,它测量的是「执行能力」而非「推断能力」。
因此,本 Benchmark 在竞品横向对比中得出的分数,直接反映了各模型在真实主流用户场景(亿级口语用户群体)下的美学生成能力上限,而非在理想化输入条件下的技术天花板。
【计分规则说明】
在实际评审中,专家对每个维度进行 0-5 分的独立打分。为便于跨场景(LP 的 10 维度与 PPT 的 5 维度)对比与直观理解,本报告在最终数据呈现时,统一将各维度的原始得分加总,并等比例折算为 100 分制标准分(即:百分制得分 = 原始总分 / 满分 × 100)。单维度的得分也同步折算为百分制(即:单维度百分制得分 = 原始维度分 / 5 × 100)。
4.4 美学评分标准
每个维度从 0 分到 5 分均有明确的评判锚点。
◆ 布局(Layout)
5分|无瑕疵且出彩
- 上下相邻模块之间的间距完全一致(或呈明显规律);
- 同行的多列内容底部对齐;
- 页面内容区两侧留有等宽空白,不顶边
4分|可忽略或没有
- 主要模块对齐良好,间距基本均匀,无明显忽大忽小
3分|明显小瑕疵
- 大部分区域整齐,但能指出 1-2 处间距明显偏大或偏小的地方
2分|大瑕疵
- 全页使用 1 种布局方式,高度重复;
- 内容明显偏向页面某一侧;
- 布局过于简单(四周大面积留白);
- 布局严重拥挤;
- 多处间距严重不统一
1分|不可用
- 元素之间发生物理重叠遮挡(文字压住按钮、导航栏盖住内容);
- 多种布局同时存在,发生严重视觉冲突;
- 发生严重对齐错误;
- 内容被容器截断显示不完整;
- PPT 场景未出现 PPT 布局,反而出现长图布局
0分|偏离/未实现
- 浏览器未显示任何布局
◆ 排版(Typography)
5分|无瑕疵且出彩
- 页面有至少 3 个明显的字号层级(大标题/小标题/正文);
- 标题无标点符号影响对齐;
- 大标题与正文字号视觉上至少相差一倍;
- 重要词句有加粗,与正文形成明显轻重对比;
- 行与行之间有明显间距,不紧贴
4分|可忽略或没有
- 标题和正文字号有明显区分;
- 标题无标点符号影响对齐;
- 有加粗区分重点;行距正常,不拥挤
3分|明显小瑕疵
- 能看出标题比正文大,但差距不够,3 秒内看不出重点在哪;
- 标题出现标点符号影响对齐;
- 或全文字重一致(全加粗或全不加粗),缺乏轻重对比;
- 内容位置轻微不正确;段落折行逻辑有问题
2分|大瑕疵
- 不同层级字号、粗细、行间距区分不明确;
- 标题和正文字号几乎一样大,视觉上无法区分;
- 同层级内容字号不一致;
- 使用多种不同对齐方式,造成视觉混乱;
- 或全页文字堆在一起,密不透风;
- 重点内容无强调
1分|不可用
- 大量文字小到难以辨认;
- 或文字颜色与背景太接近,核心内容无法阅读;
- 显示错误,未被正确渲染
0分|
- 无内容无排版
◆ 配色(Color)
5分|
- 全页主色不超过 2 种;
- 辅助色明确;
- 强调色(如 CTA 按钮)单独使用 1 种且只出现在关键位置;
- 所有同类型元素(如全部主按钮)颜色完全一致;
- 找不到"游离"在主色系之外的颜色
4分|
- 主辅色明确;
- 全页颜色不超过 3-4 种;
- 整体色调和谐;
- 无不协调撞色
3分|
- 有主色意图,但能找到 1-2 个与主色系不搭的颜色;
- 或主/辅/强调三类颜色缺失某 1-2 类但未造成丑陋;
- 或整页颜色过少,缺乏设计感(黑白色调除外)
2分|
- 主/辅/强调三类颜色缺失导致页面配色丑陋;
- 页面颜色超过 5 种且彼此不协调;
- 同层级颜色或同类型元素颜色前后不统一;
- 出现不协调的撞色
1分|
- 文字和背景颜色几乎相同,核心内容看不清
0分|
- 出现浏览器兜底页面,无配色
配色三层体系说明
主色:面积最大、最频繁的颜色,决定整体基调。通俗说:"这个页面第一眼看上去是什么颜色"
辅助色:配合主色的次级颜色,用于卡片背景、分割区域,面积小于主色大于强调色
强调色:只出现在最关键位置(CTA按钮/重要标签),面积很小但视觉最跳眼。
注意:黑白灰不能作为强调色
◆ 字体(Font)
5分|
- 全页只用 1-2 种字体(使用了非系统"默认"字体);
- 中英文混排时视觉重量协调,不一粗一细;
- 字体有明显的设计感;
- 字体风格与页面场景高度匹配(科技感页面用现代感强的无衬线体,文艺页面用衬线体);
- 有 SVG 或图片绘制的强设计感字体
4分|
- 全页只用 1-2 种字体(使用了非系统"默认"字体);
- 与页面无明显冲突;渲染正常无乱码;
- 字体样式比较单一;
- 无 SVG 绘制强设计感字体
3分|
- 使用了系统默认字体(黑体/Arial/宋体),安全但无特色;
- 或字体与场景无冲突但看不出设计用心;
- 无字体样式(只用了颜色样式等于没用)
- 效果不好
- 无SVG或图片绘制的强设计感字体
2分|
- 同页出现 3 种及以上差异明显的字体;
- 或字体与页面场景明显冲突(如严肃金融页用了卡通手写体)
1分|
- 字体加载失败,出现乱码、方块字符;
- 或整页降级为浏览器默认字体,与设计意图完全背离
0分|
- 没有文字
◆ 图片(Image)
5分
- 图片清晰无压缩噪点,没有图裂;
- 所有图片为同一视觉风格(同为摄影且色调一致,或同为同风格插画);
- 每张图片内容与页面主题直接相关,找不到"凑数"的图片
4分
- 图片清晰,无变形拉伸,内容与主题间接相关,没有图裂;
- 多图风格基本一致
3分
- 图片清晰度一般,有轻微压缩感;
- 多图中有 1-2 张风格与其他图片有差异;
- 或有图片感觉与主题关联不强
2分
- 图片有拉伸变形(人脸被压扁/产品被拉宽);
- 或有水印/明显压缩马赛克;
- 或多图风格差异极大(摄影照片混卡通插画)
1分
- 图片加载失败,显示破图图标;
- 或存在未替换的占位符或测试图(如picsum.photos、placehold.it 域名)
0分
- 没有图片
◆ 背景(Background)
5分
- 相邻区块背景颜色或深浅明显不同,能清晰感知页面分区;
- 有明显的设计手法装饰;
- 渐变过渡平滑无硬边(颜色之间看不出明显分界线);
- 背景与前景(文字/卡片)之间有明显落差,前景内容有"浮起来"的感觉
4分
- 不同区块背景有区分(如白色区块与浅灰区块交替);
- 渐变平滑;
- 整体干净
3分
- 全页背景颜色相同(如全白或全浅灰)
- 从上到下无任何视觉分区,但也不造成问题
2分
- 相邻区块颜色出现明显冲突;
- 或渐变出现色带硬边;
- 或背景太花,内容"陷"在背景里
1分
- 背景色与文字颜色几乎相同,导致内容消失不可见
0分
- 浏览器页面崩溃,没有背景
◆ 元素(Elements)
5分
- 全页图标线条粗细完全一致(来自同一套图标库);
- 相同布局中的图标大小完全统一;
- 品牌 Logo 与真实 Logo 一致;
- 装饰图形颜色在页面主色系范围内,找不到风格游离的装饰元素;
- SVG 图形绘制优质
4分
- 图标风格统一,来自同一套图标库;
- 大小基本一致;
- 真实品牌 Logo 具有明显的特征(AI 自己设计的);
- 无明显异类图标混入;
- SVG图形绘制普通;
3分
- 图标大部分统一,但能找到 1-2 个线条粗细或样式明显不同的图标
- 图标使用1个一致重复,但统一
- 没有真实品牌logo,用文字代替
- SVG图形绘制粗糙
2分
- 图标来自多套不同风格的图标库,线条粗细和样式各异;
- 或大量使用 emoji 代替设计图标
- 图标出现绘制错误
- SVG图形绘制错误
1分
- 图标全部加载失败,显示空白或问号方块
0分
- 没有使用元素
◆ 组件(Components)
5分
- 全页所有同类主按钮圆角/高度/颜色/阴影完全一致;
- 有特别的样式效果;
- 主按钮和次按钮有明确视觉区分(填充色 vs 描边);
- 同行卡片高度完全一致;卡片内边距统一
4分
- 同类组件样式统一,无明显异类;
- 样式效果较普通单一;
- 主次按钮有区分;
- 卡片结构清晰不拥挤
3分
- 同类组件基本统一,但能指出 1-2 处细节不一致(如某个按钮圆角明显更大);
- 或按钮设计极其简陋(纯色矩形无任何样式细节)但统一
2分
- 同类组件样式各异(按钮大小/颜色/圆角前后不统一);
- 或出现未经任何美化的浏览器原生输入框
1分
- 主按钮或导航栏无法正常渲染;
- 或关键组件视觉完全崩坏
0分
- 没有组件
◆ 交互(Interaction)
5分
- 所有可点击元素悬停时有至少 2 种同时发生的视觉变化(如颜色变深 + 阴影扩大,或背景出现 + 文字位移);
- 点击时有明显按压感(颜色加深或轻微缩小);
- 表单获得焦点时边框颜色变化;
- 鼠标悬停时变为手型光标
4分
- 主要按钮和导航链接悬停时有颜色变化;
- 表单获得焦点有边框高亮;
- 鼠标变手型
3分
- 部分元素有交互,但不完整(如悬停变化主按钮有,卡片和链接没有);
- 或鼠标悬停时未变为手型光标
2分
- 全页几乎没有悬停反馈;
- 点击后无任何视觉确认,不知道是否点中
1分
- 点击后页面布局错乱;
- 或主要按钮点击完全无反应
0分
- 没有交互
◆ 动效(Animation)
5分
- 有完整动画效果,且丰富,效果好,吸引眼球;
- 同一区块内的不同元素入场时间错开(先出现标题,再出现副标题,再出现按钮,形成依次出现的效果);
- 动画结束后元素停在正确位置无抖动;
- 单个动画时长在 0.3-0.8 秒之间
4分
- 有完整动画效果,但比较基础,不吸引人;
- 主要区域有入场动画;
- 滚动触发元素有序出现;
- 动画流畅无卡顿
3分
- 有动效,但同一区块的所有元素同时出现(无错开),动效单一(仅淡入,无位移);
- 或动画时长偏长(超过 1 秒)
2分
- 动效夸张(大幅旋转、弹跳过大)影响阅读;
- 或动画时长超过 2 秒,需要等待内容才出现;
- 效果实现不完整
1分
- 动效导致元素消失或闪烁(动画结束后内容不见了);
- 或动效引起严重卡顿,页面几乎无法滚动
0分
- 没有动效
4.5 评分标准的设计原则
这套标准的核心设计哲学体现在三个地方:
① 0分的定义必须精确
模糊的下限是评测体系最大的漏洞。在最终版标准中,我们为每个维度都明确定义了 0 分(完全未实现)和 1 分(实现但不可用)的边界,使问题可定位、可追踪。
② 得分锚点对应可执行的设计规范
每个分值的描述,都可以直接转化为评审者可执行的检查项——不是模糊的「整体不错」,而是「上下相邻模块间距完全一致」、「主按钮和次按钮有明确视觉区分(填充色 vs 描边)」。这使得不同评审者对同一样本的判断趋于一致。
③ 美学层指标与代码层指标显式分离
5 分的描述聚焦美学质量,而 1/0 分的描述聚焦代码失效。评分系统同时捕捉「代码还原度失败」和「美学还原度不达标」两类问题,无需在两套体系之间切换。
4.6 评审可靠性:设计团队 vs 非设计团队对比实验
为验证评分体系的可信度,我们对同一批样本进行了双轨评分实验。
差异项 | 数据 |
整体系统性偏差 | 非设计团队标准化总分比设计团队高 5.4 分,两组独立实验均复现(+5.4 分 / +5.6 分) |
最大单样本误判 | 渲染崩溃样本:设计团队给 30 分,非设计团队给56 分,差距 +26 分 |
最不可靠的维度 | 布局、排版、元素(非设计团队系统性偏宽松16~18 分) |
动效判断方向错误 | 非设计团队出现好坏识别方向颠倒(优质动效打0分/无动效打高分),不是松紧问题,是判断能力缺失 |
结论:本报告所有评测数据均采用设计团队版本。非设计团队评分数据仅作为「评审系统偏差研究」的参照,不参与最终竞品美学对比结论。
4.7 PPT 场景的维度精简逻辑
PPT 场景采用 5 维度评测(布局/排版/配色/图片/元素),精简逻辑如下:
移除维度 | 原因 |
字体 | PPT 场景惯用系统默认字体,以达到高效标准化协作目的,非美学个性化决策的体现,不纳入评测维度 |
背景 | PPT 多页结构中背景统一为常态,难以有效区分质量层级 |
组件 | PPT 组件规范较 LP 简单,复用 LP 标准易产生误判 |
交互 | PPT 翻页交互为基础功能,不作为美学评分维度 |
动效 | PPT 翻页动效为基础功能预设,属于默认期望而非美学加分项;页面元素动效在 PPT 场景下属于锦上添花,不具备评测必要性 |
5 维度保留了对 PPT 美学质量影响最大的核心维度,在评审效率与评测精度之间取得最优平衡。
4.8 渲染环境标准化
KAT Benchmark 制定了标准化渲染环境,确保所有模型的评分结论在同一物理条件下产生:
浏览器 | Chrome 最新版,禁止深色模式 |
视窗分辨率 | 1920×1080,全屏无缩放 |
字体加载 | 完整系统字体环境 |
评审方式 | 设计团队独立评分。 在交付评审前,已通过脚本抹除所有模型特有的代码签名(如特定框架类名、注释、占位图域名等),确保绝对双盲公正性。 |
五、竞品横向对比结论
5.1 PPT 场景(三方对比)
维度(折算百分制) | KAT 模型新版本 | Kimi 2.5 | GLM 5.0 |
配色 | 78.0 ★ | 48.0 | 56.0 |
布局 | 68.0 ★ | 40.0 | 54.0 |
排版 | 58.0 ★ | 54.0 | 56.0 |
图片 | 48.0 ★ | 6.0 | 10.0 |
元素 | 36.0 | 26.0 | 38.0 ★ |
标准化总分 | 57.6 ★ | 34.8 | 42.8 |
★ = 该维度最高分
关键发现:
- 图片生成能力是最显著差距——竞品在 PPT 场景的图片得分仅 6~10 分(核心基准测试集中 70% 完全无图),KAT 达到 48 分
- 配色是 KAT 的核心壁垒:唯一达到 78 分的维度,竞品均不超过 56 分
- 布局结构稳定性:竞品出现多个整页白屏/渲染失败样本,KAT 无不可用级别的结构崩溃
5.2 Landing Page 场景(三方对比)
维度(折算百分制) | KAT 模型新版本 | GLM 5.0 | Kimi 2.5 |
布局 | 60.0 ★ | 52.0 | 56.0 |
排版 | 62.0 ★ | 62.0 ★ | 60.0 |
配色 | 68.0 ★ | 58.0 | 58.0 |
字体 | 62.0 | 56.0 | 64.0 ★ |
图片 | 40.0 ★ | 40.0 ★ | 14.0 |
背景 | 66.0 | 70.0 ★ | 60.0 |
元素 | 64.0 ★ | 52.0 | 56.0 |
组件 | 60.0 ★ | 60.0 ★ | 54.0 |
交互 | 66.0 | 72.0 ★ | 68.0 |
动效 | 50.0 | 54.0 | 56.0 ★ |
标准化总分 | 59.8 ★ | 57.6 | 54.6 |
★ = 该维度最高分
关键发现:
- LP 场景三方差距较 PPT 更为收窄,是目前各模型竞争最激烈的场景
- KAT 在配色(+10 分)、元素(+8~+12 分)、布局(+4~+8 分)三个维度建立核心优势
- Kimi 在背景(70 分)、交互(72 分)两个维度领先;GLM 在字体(64 分)、动效(56 分)有局部领先
- GLM 图片得分仅 14 分,是 LP 场景最严重的单维度失败
5.3 核心竞争力小结
- 配色体系规划:
LP 配色 68 分、PPT 配色 78 分,双场景均为三方最强维度,领先竞品 10~30 分;主辅强调色三层体系输出稳定,无配色崩溃样本
- 布局结构稳定性:
LP 布局 60 分(领先 Kimi 8 分),PPT 布局 68 分(领先 Kimi28 分);全量样本零渲染崩溃、零白屏,多屏结构理解能力扎实
- 元素完整性:
LP 元素 64 分,领先竞品 8~12 分;在竞品普遍缺失图标、以 emoji替代的情况下,KAT 能稳定输出完整图标系统
六、KAT 代际能力跃升
6.1 Landing Page:上一代 → KAT 模型新版本
维度(折算百分制) | 上一代基线版 | KAT 模型新版本 | 提升分值 | 提升幅度 |
元素 | 16.0 | 64.0 | +48.0 | +300%↑ |
图片 | 12.0 | 40.0 | +28.0 | +233%↑ |
动效 | 22.0 | 50.0 | +28.0 | +127%↑ |
布局 | 38.0 | 60.0 | +22.0 | +58%↑ |
配色 | 44.0 | 68.0 | +24.0 | +55%↑ |
组件 | 50.0 | 60.0 | +10.0 | +20%↑ |
排版 | 52.0 | 62.0 | +10.0 | +19%↑ |
背景 | 58.0 | 66.0 | +8.0 | +14%↑ |
字体 | 60.0 | 62.0 | +2.0 | +3%↑ |
交互 | 68.0 | 66.0 | -2.0 | -3% |
标准化总分 | 42.0 | 59.8 | +17.8 | +42%↑ |
6.2 PPT:上一代 → KAT 模型新版本
维度(折算百分制) | 上一代基线版 | KAT 模型新版本 | 提升分值 | 提升幅度 |
元素 | 16.0 | 36.0 | +20.0 | +125%↑ |
图片 | 22.0 | 48.0 | +26.0 | +118%↑ |
配色 | 36.0 | 78.0 | +42.0 | +117%↑ |
布局 | 32.0 | 68.0 | +36.0 | +113%↑ |
排版 | 36.0 | 58.0 | +22.0 | +61%↑ |
标准化总分 | 28.4 | 57.6 | +29.2 | +103%↑ |
基线特征:上一代 基线版 PPT 场景在核心基准测试集中,满分率为 0,整体处于「能渲染但无美学价值」状态。最新版本已出现多个配色满分案例,标志着模型从「能用」走向「局部优质」的能力跃迁。
七、结语
本报告的核心命题,始终聚焦于一个行业共性挑战:如何系统性地弥合“用户自然口语表达”与“专业级前端代码输出”之间的巨大语义鸿沟。
KAT 的技术哲学在于:
绝不将专业门槛转嫁给用户,而是通过强大的底层模型能力,去理解、推断并补全低信息密度输入背后的美学意图。我们所构建的精细化标签体系与 Benchmark 评测框架,正是支撑这一能力进化的技术基石。
最新的评测结果充分验证了 KAT 的代际跃升:
在 Landing Page 与 PPT 两大核心业务场景中,KAT 均展现出强劲的竞争力。
不仅在配色、布局、元素等核心美学维度上确立了对竞品的全面领先,更相较于上一代版本实现了跨越式的分值倍增。这证明了 KAT 的美学生成能力并非简单的样本记忆,而是真正具备了深度的审美泛化与结构重组能力。同时,我们也清晰地认识到,在精细化背景构建、复杂交互动效以及字体排版个性化等维度,仍有持续打磨的空间,这将指引我们下一阶段的技术攻坚。
从服务极少数能撰写专业 spec 的开发者,到赋能千万级习惯使用日常口语的普通创作者——这是 KAT 正在引领的生产力范式跃迁。Benchmark 上的每一次得分突破,都在让“一句话生成专业级商业页面”的技术愿景,一步步化为现实。