
模型推理
在线推理
在线推理 (Online Inference):模型在收到用户请求(如点击按钮、输入查询)时实时进行计算,并立即返回单个预测结果(通常在毫秒级)。它要求模型服务低延迟、高并发,常用于需要即时反馈的应用,如推荐系统、欺诈检测、聊天机器人对话等。用户在新建推理接入点后,通过API Key的方式调用接入点。
体验链接:在线推理
推理接入点类型
- 预置推理接入点:当用户调用KAT系列模型时,平台提供对应模型的预置推理服务,用户可快捷调用。
- 自定义推理接入点:需由用户主动创建推理接入点,支持更丰富的模型选择。
新建自定义推理接入点
- 权限申请:
- 主账号(即溪流湖账户)拥有账号下所有项目的访问/管理权限,无需权限申请;
- 子账号:可由主账号为名下子账号设置某项目的只读/管理权限;
- 若账户余额不足,请先充值;
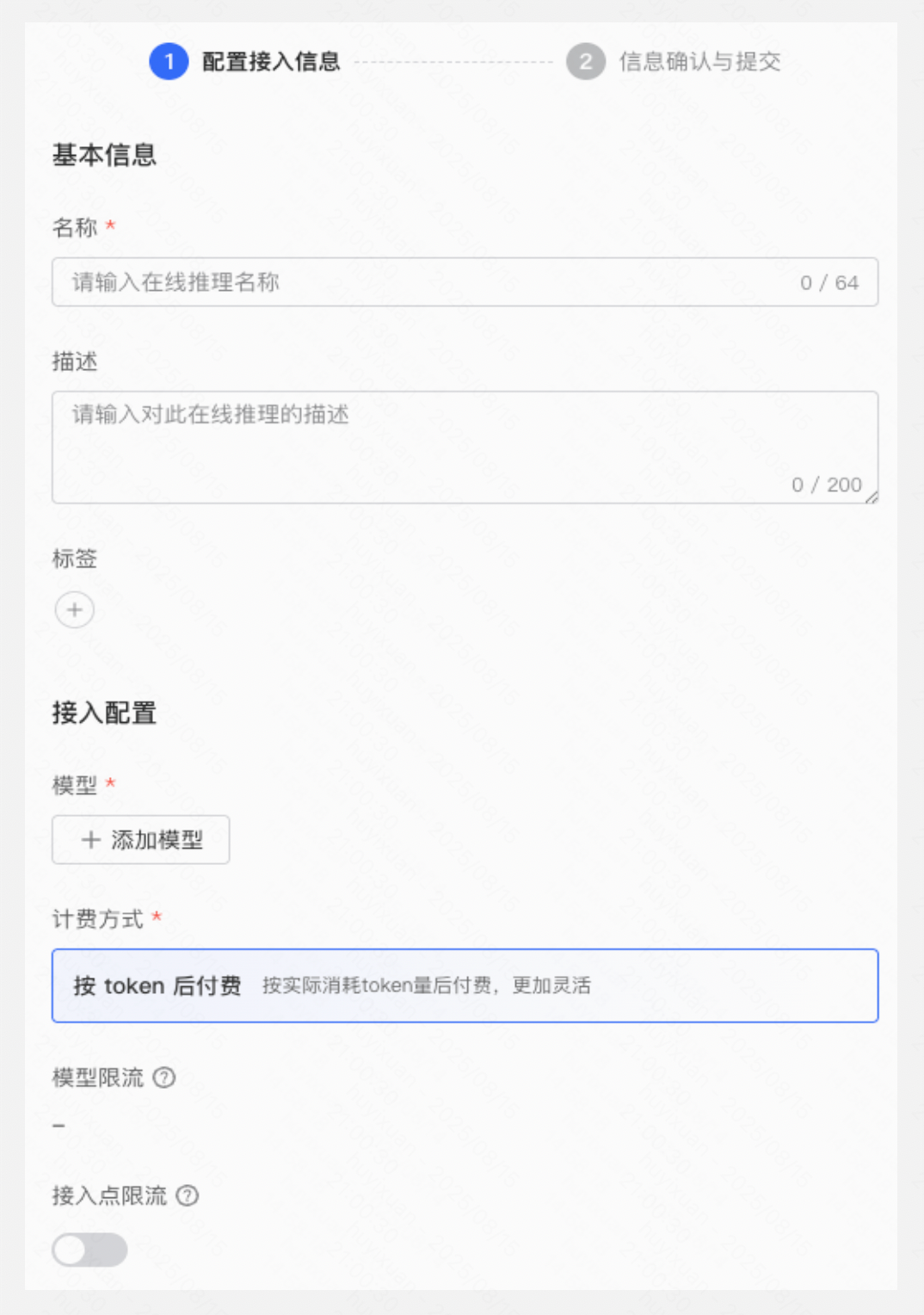
- 确认权限及余额无问题后,进入在线推理页面,选择「自定义推理接入点」,点击「新建推理服务」,进入创建页面;
- 填写名称、应用描述、标签等基础信息,用户可对接入模型配置限流:
- 模型限流:账号下此模型的总限流。此模型推理点的所有请求,将共同消耗该模型的限流额度。如您希望提升模型访问总限流,可点击提交工单(当前仅支持主账户申请)。
- 接入点限流:为每个推理接入点单独设置的独立调用频率上限,用于控制该接入点的最大请求量。建议按业务重要性,为重要接入点设置独立限流,确保核心业务有保障资源,避免被其他业务挤占。执行逻辑如下:

用户填写完成后点击「下一步进入信息确认与提交页面,提交成功后将自动跳转至推理点详情-API 调用页面。
调用推理点
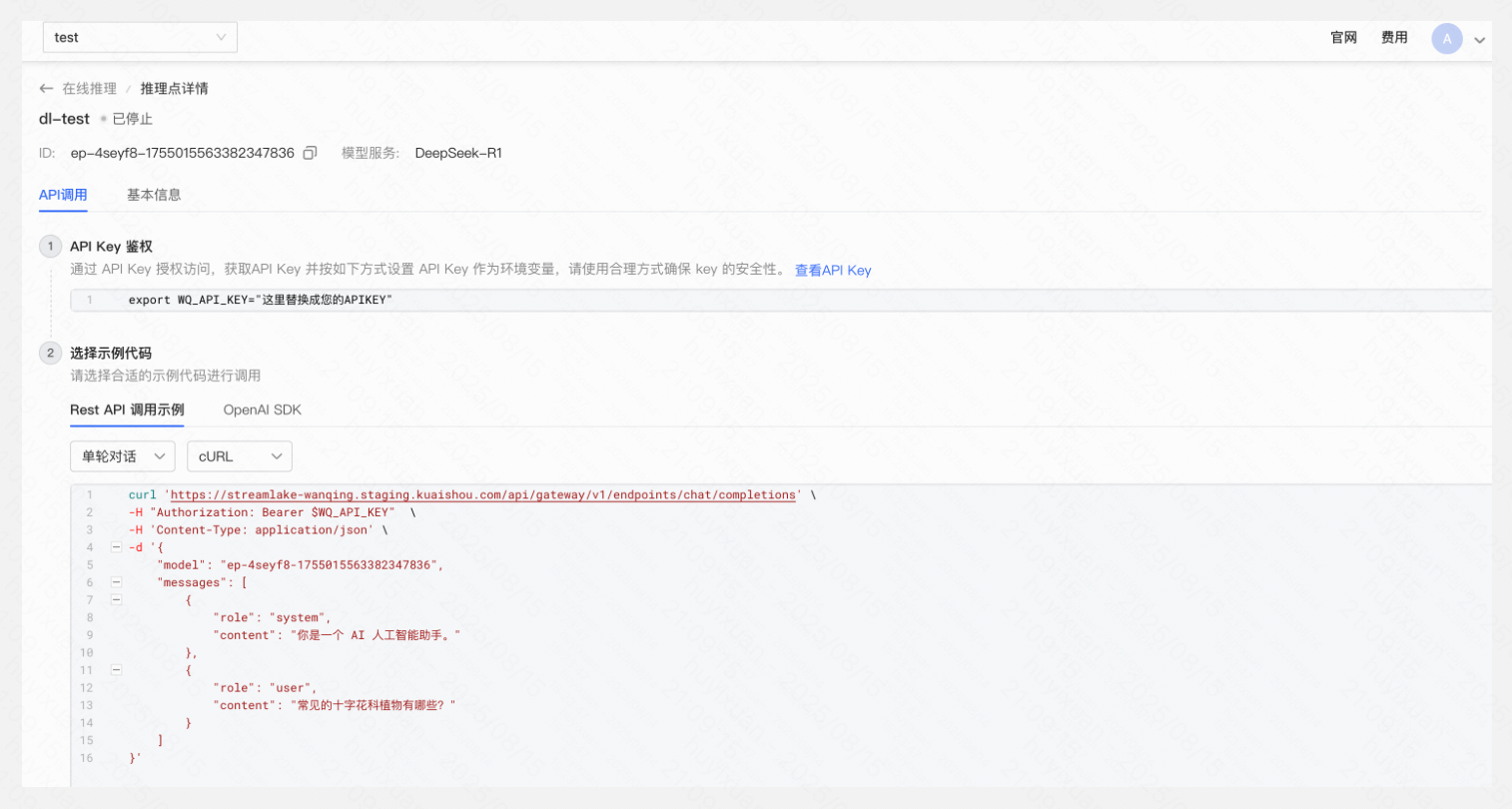
- 进入在线推理列表页/详情页,选择需调用的推理点(推理点状态需为“运行中”),复制推理点ID,如“ep-xxx-xxx”。
- API调用页面可以查看模型推理接入点的调用方法,点击「查看API Key」获取API Key,在环境变量中进行设置,参考API示例对模型推理接入点进行调用。API Key调用详细说明可查看在线推理点对话 API。
AIGC 模型多 LoRA 调用
在使用 AIGC 模型进行多次 SFT 精调后,每次精调任务都会产出一个独立的 LoRA 文件并保存至模型仓库。LoRA 可以理解为叠加在基础模型之上的"风格插件",例如针对同一个文生视频基础模型,可以分别训练出"产品展示风格"、"电影质感风格"、"品牌视觉风格"等不同的 LoRA。
多调用 LoRA 的核心优势在于:一个推理点可以绑定多个 LoRA,调用时按需指定,无需为每种风格单独部署一套服务,大幅降低资源成本,同时灵活满足多样化的生成需求。
适用范围
该功能仅适用于针对以下四个基础模型进行 SFT 精调的场景:
- Qwen-Image 文生图
- Qwen-Image-Edit 图像编辑
- Wan2.2-I2V-A14B 图生视频
- Wan2.2-T2V-A14B 文生视频
使用流程
精调产出 LoRA → 部署对应基础模型 → 新建推理点时绑定 LoRA → API 调用
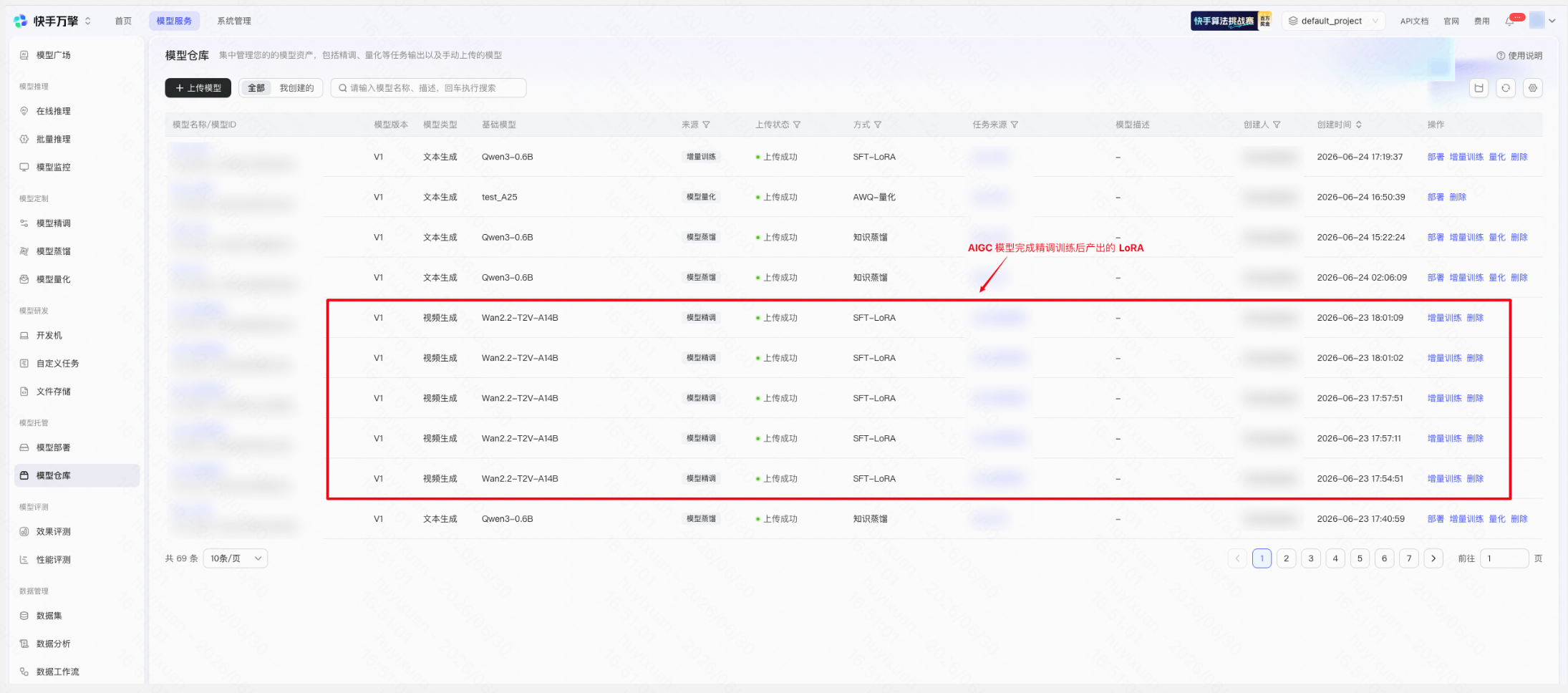
Step 1:确认模型仓库中已有 LoRA
完成 SFT 精调任务后,产出的 LoRA 会自动保存至模型仓库。进入模型仓库,可查看该 LoRA 的名称、基础模型及来源等信息。
在新建推理点时,可选择的 LoRA 范围即来源于此。
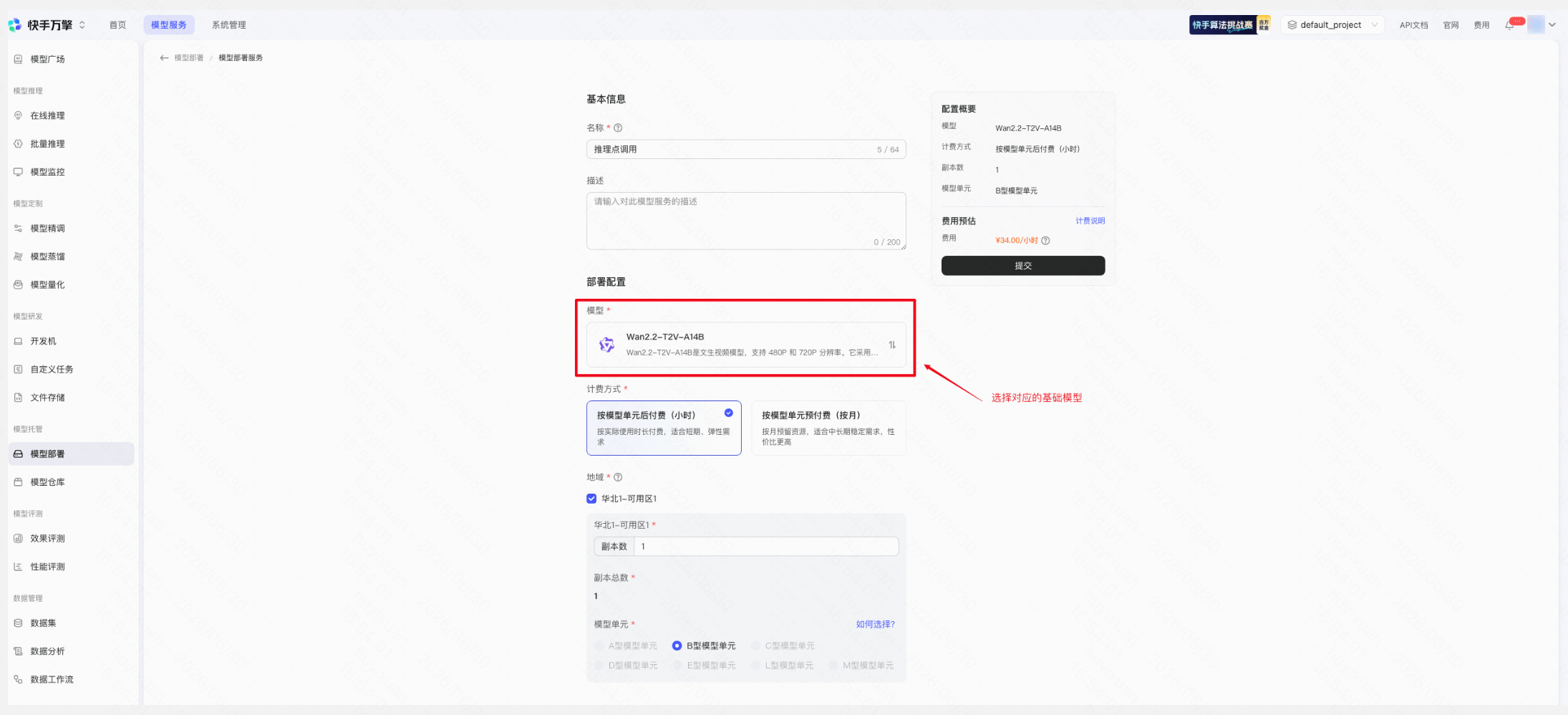
Step 2:部署基础模型
前往模型部署,选择上述支持 LoRA 的 AIGC 基础模型,完成部署配置并提交。
Step 3:新建推理点并绑定 LoRA
- 进入在线推理,点击「新建推理点」
- 填写名称、描述、标签等基本信息
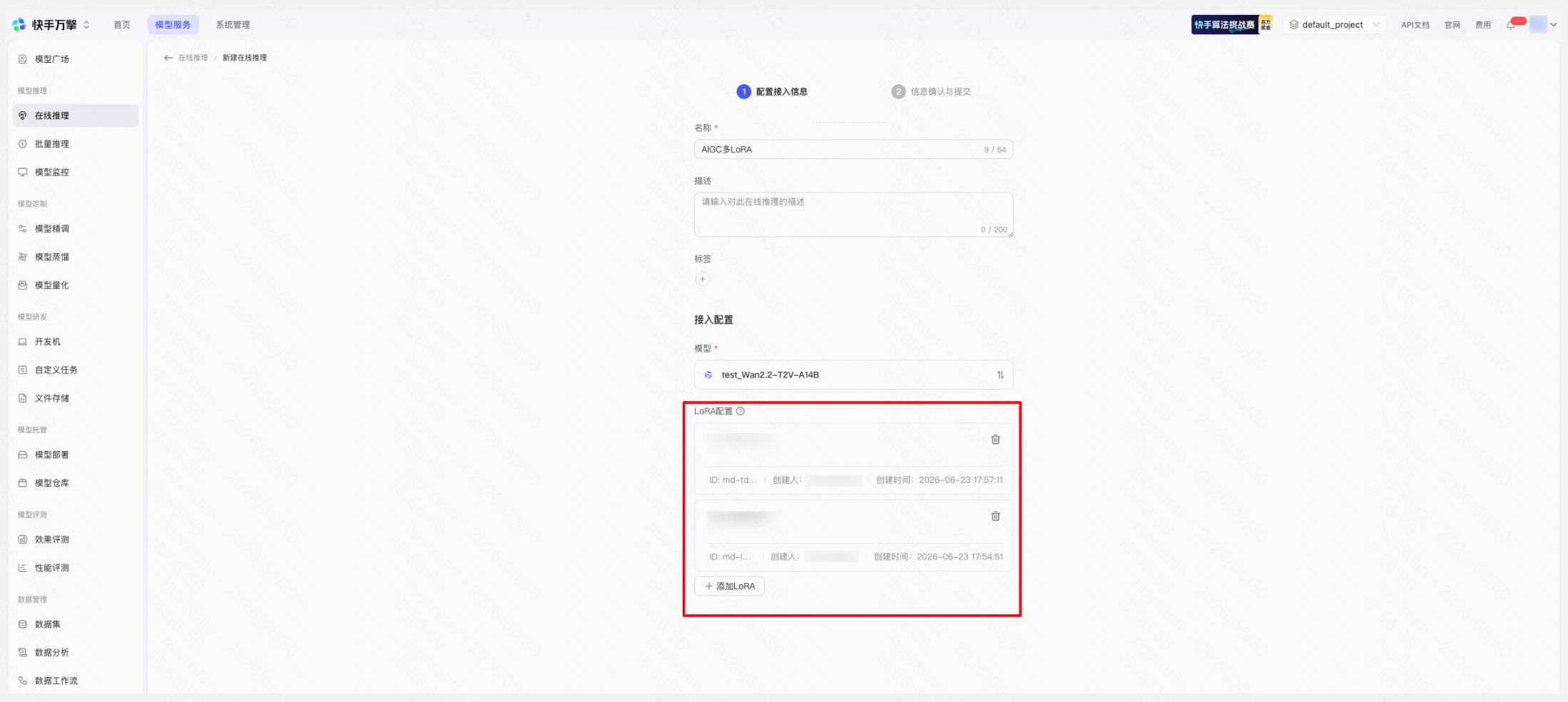
- 选择已部署的 AIGC 基础模型,页面将自动展示 LoRA 配置区域
- 点击「+ 添加 LoRA」,从模型仓库中选择与该基础模型关联的 LoRA,最多选择 5 个
提示:此处绑定的 LoRA 是该推理点可调用的 LoRA 范围。每次实际 API 请求时,可从已绑定的 LoRA 中按需选择,也可以不使用任何 LoRA。
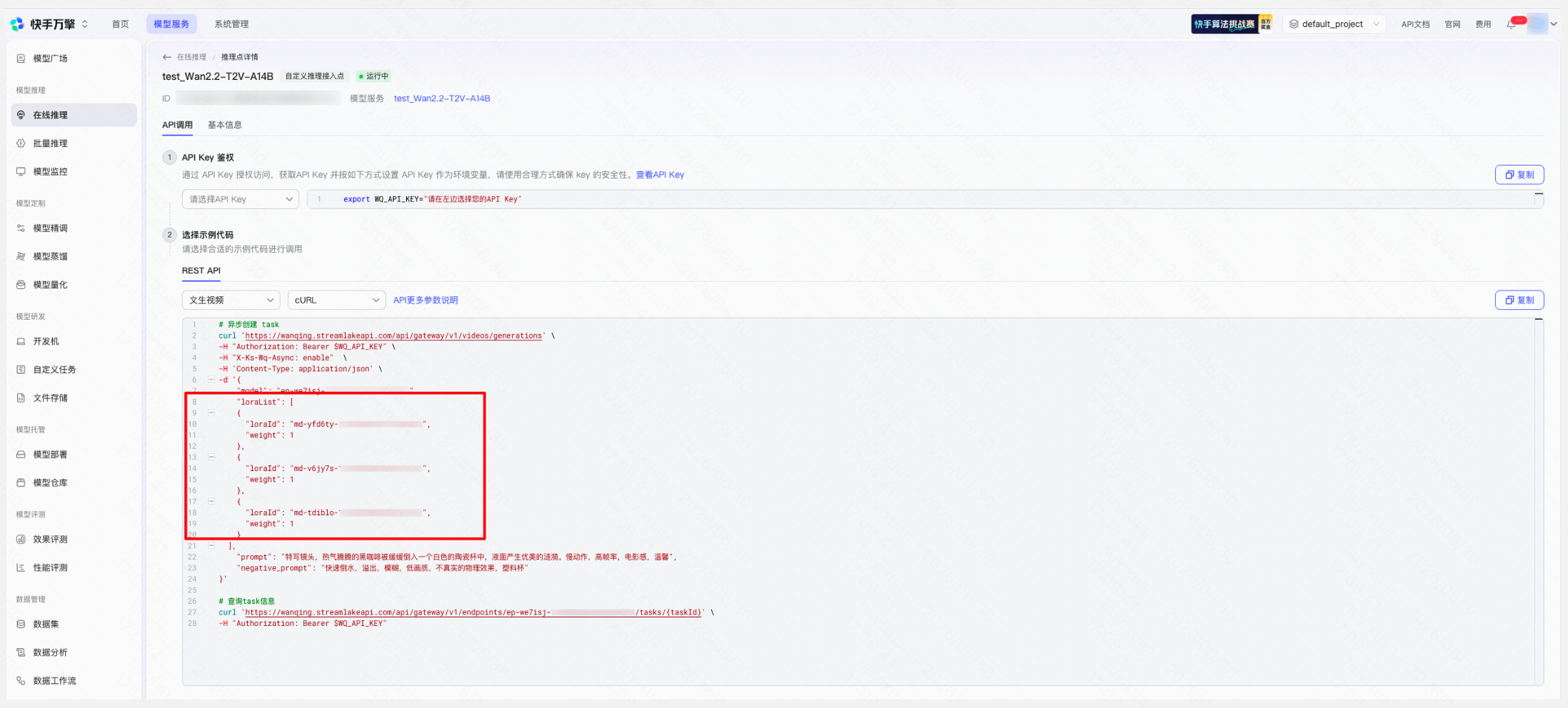
Step 4:API 调用
推理点创建成功后,可通过 loras 字段在请求体中动态指定本次需要使用的 LoRA 及其权重:
查看推理服务
- 预置推理接入点页面展示平台针对KAT系列模型预置的推理接入点,您可修改接入点限流,其余信息不支持修改;
- 自定义推理接入点列表展示该项目下的所有用户创建的推理点信息,您可修改推理点名称、描述、标签及限流信息。

查看调用监控
您在推理列表或调用监控页面可查看推理的监控记录,平台当前支持用户按天/小时/分钟选择聚合维度,支持自定义查询周期,调用监控最长保留一年,最大查询时间跨度为31天。
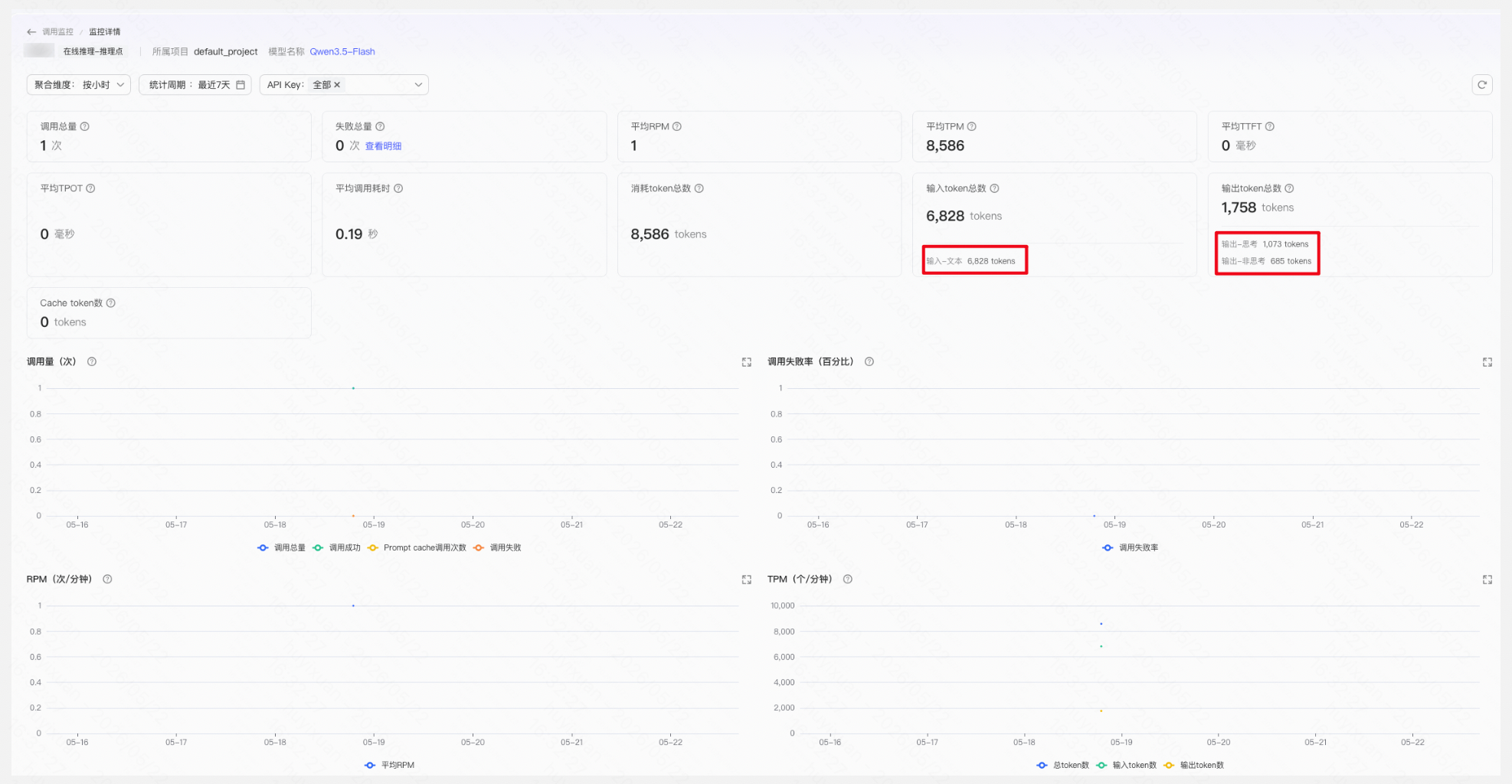
曲线图各指标说明
- 调用量(次):按聚合维度展示统计周期内的各项指标数据:调用总量、调用成功次数、调用失败次数、Prompt cache次数;
- 消耗token数(tokens):按聚合维度展示筛选条件下的各项指标数据,:token总数、输入token数、输出token数、Prompt cache token数;
- 模型调用耗时(秒):按聚合维度展示筛选条件下调用耗时的平均值;
- 首次响应耗时(秒):按聚合维度展示筛选条件下调用首包时长的平均值;
- Token输出速度(个/秒)按聚合维度展示筛选条件下调用平均输出token的速度;
- 调用失败率(百分比):按聚合维度展示筛选条件下调用失败率(调用失败/调用总量);
- 输入输出token卡片展示影响因子子项数据,您可及时感知各维度消耗情况。
批量推理
批量推理 (Batch Inference):模型在非实时、离线状态下,对累积的大量数据(如一天的用户日志、历史记录)集中、一次性进行预测计算,结果通常批量输出到数据库或文件。批量推理注重处理吞吐量和资源利用率,适用于报表生成、用户分群、历史数据分析等场景。
体验链接:批量推理
适用场景
- 请求数据已经以JSONL格式整理为文件。
- 处理超大规模数据,例如TB级日志。
- 多模态模型批量推理,需避免巨大的网络传输压力。
新建批量推理任务
- 权限申请:
- 主账号(即溪流湖账户)拥有账号下所有项目的访问/管理权限,无需权限申请;
- 子账号:可由主账号为名下子账号设置某项目的只读/管理权限。
- 若账户余额不足,请先充值。
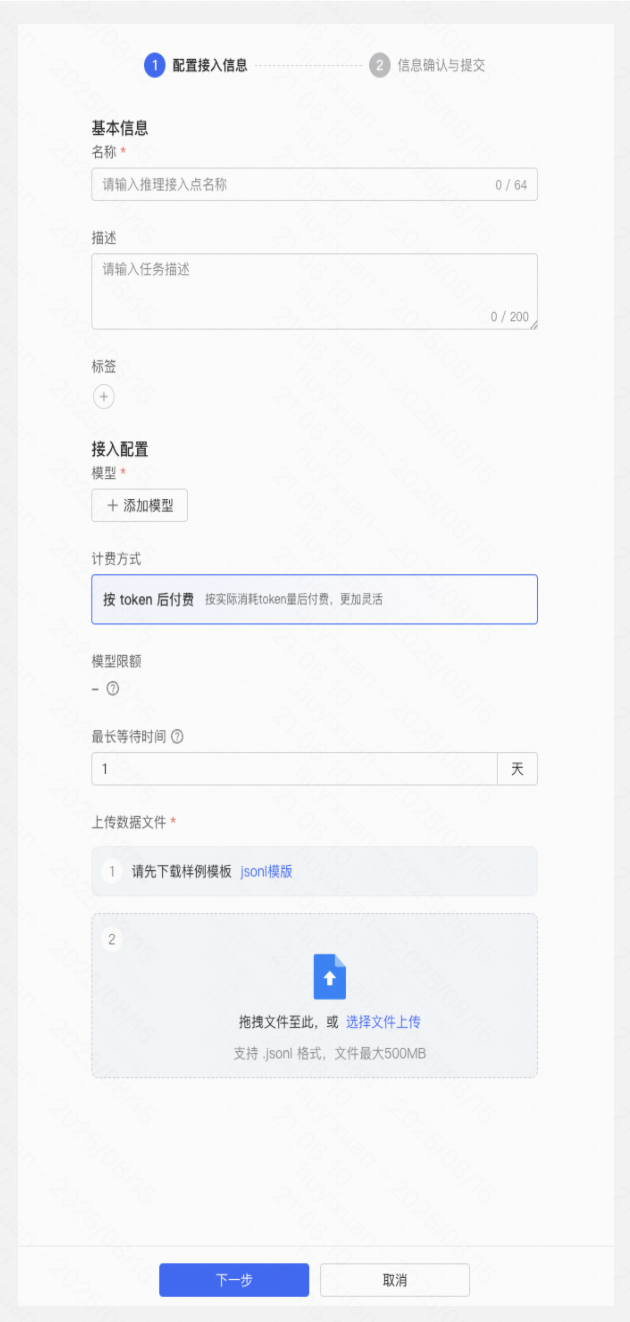
- 确认权限及余额无问题后,进入批量推理页面,点击「新建批量推理任务」,进入创建页面。
- 填写名称、应用描述、标签等基础信息;
- 配置最长等待时间:若任务在设置时间内未全部完成,平台将自动停止该任务,用户可查看已执行的结果文件;
- 上传JSONL格式数据文件。
查看与管理批量推理任务
用户可在任务列表或批量推理任务详情页,查看批量推理任务的信息,包括名称、标签、描述、任务开始时间、接入配置及任务进度信息(包含任务总数、成功及失败数量)。
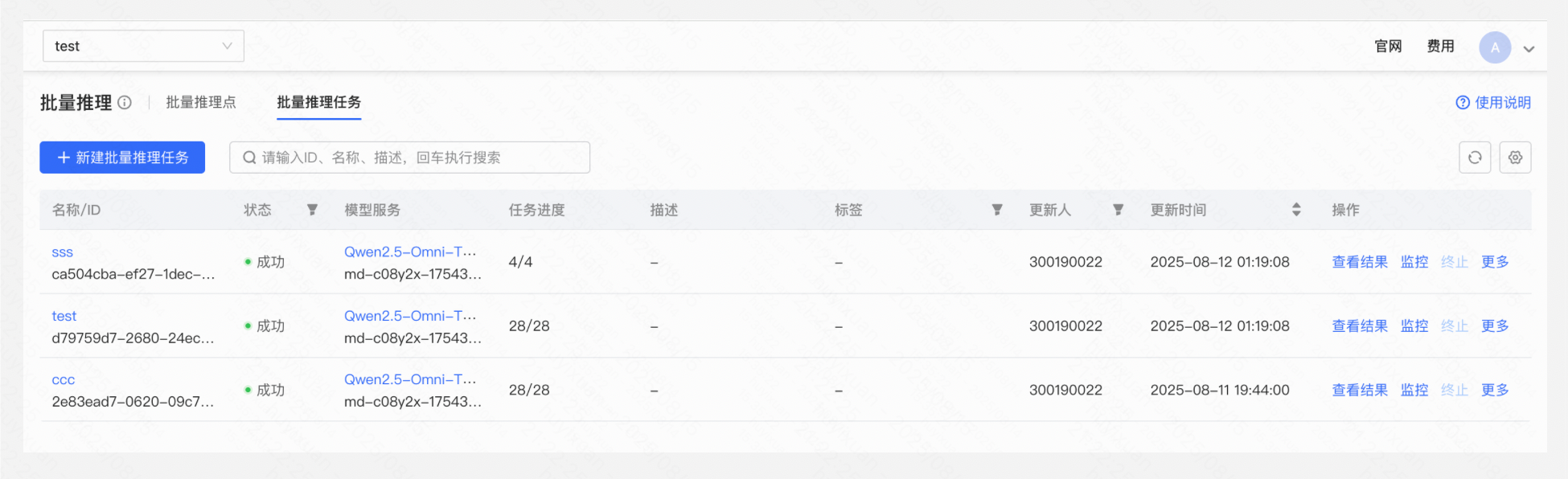
批量推理任务状态
- 初始化:批量推理任务创建中;
- 排队中:由于并发任务数达到上限等原因需排队等候资源调度;
- 运行中:任务处于运行状态中;
- 已完成:任务中所有请求已执行完毕,用户可查看结果文件;
- 终止中:由于超过等待时间或用户手动终止,任务当前处于终止中状态;
- 已终止:任务已被终止;
- 异常:输入文件校验失败或其他原因导致任务失败,用户将鼠标悬浮至异常状态图标处可查看具体的失败原因。
查看结果文件
在推理任务完成后,溪流湖将以短信形式通知,您可点击「查看结果」或在任务详情查看并下载JSONL格式的结果文件。
【⚠️结果文件将在过期后被系统删除,请用户及时下载结果文件】
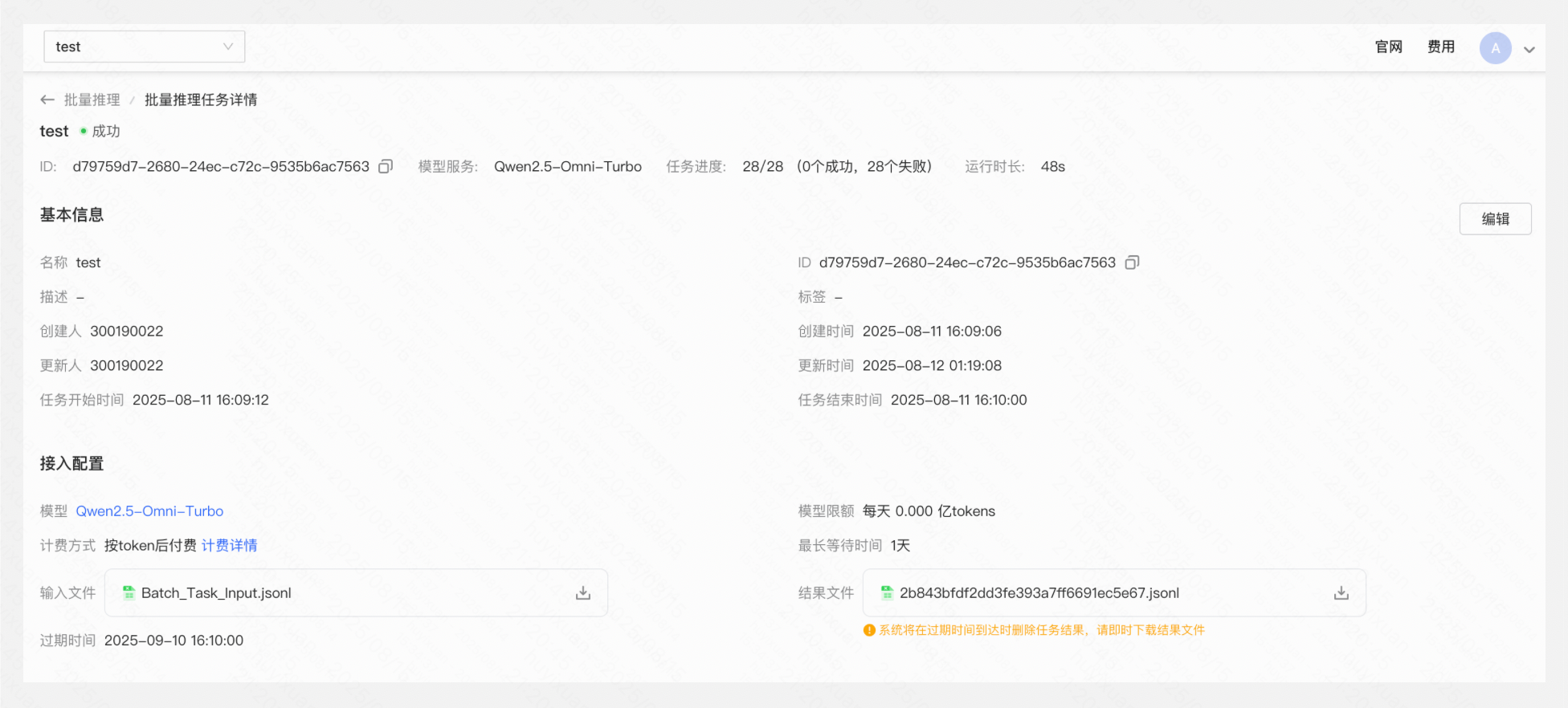
查看调用监控
您在推理列表或调用监控页面可查看推理的监控记录:
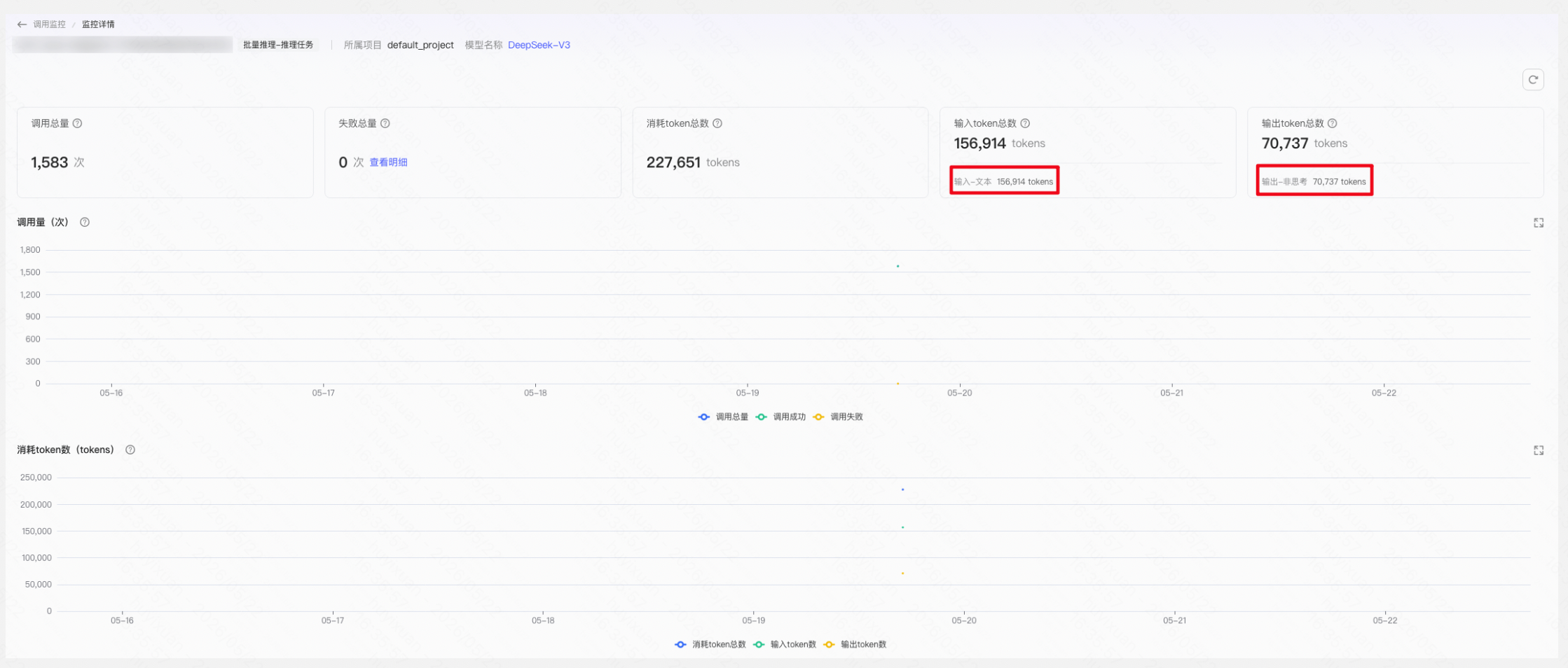
各指标说明
- 调用总量:筛选条件下,发送请求的总数;
- 失败总量:筛选条件下,发送请求失败的总数;
- 消耗token总数:筛选条件下,所有调用输入/输出消耗token的总数;
- 输入token总数:筛选条件下,所有调用输入消耗token的总数;
- 输出token总数:筛选条件下,所有调用输出消耗token的总数;
- 调用失败率(百分比):按聚合维度展示筛选条件下调用失败率(调用失败/调用总量);
- 输入输出token卡片展示影响因子子项数据,您可及时感知各维度消耗情况。