
售前咨询
快手万擎(Vanchin)
批量推理
更新时间:2025-12-15 19:15:12
批量推理 (Batch Inference):模型在非实时、离线状态下,对累积的大量数据(如一天的用户日志、历史记录)集中、一次性进行预测计算,结果通常批量输出到数据库或文件。批量推理注重处理吞吐量和资源利用率,适用于报表生成、用户分群、历史数据分析等场景。
体验链接:批量推理
适用场景
- 请求数据已经以JSONL格式整理为文件。
- 处理超大规模数据,例如TB级日志。
- 多模态模型批量推理,需避免巨大的网络传输压力。
新建批量推理任务
- 权限申请:
- 主账号(即溪流湖账户)拥有账号下所有项目的访问/管理权限,无需权限申请;
- 子账号:可由主账号为名下子账号设置某项目的只读/管理权限。
- 若账户余额不足,请先充值。
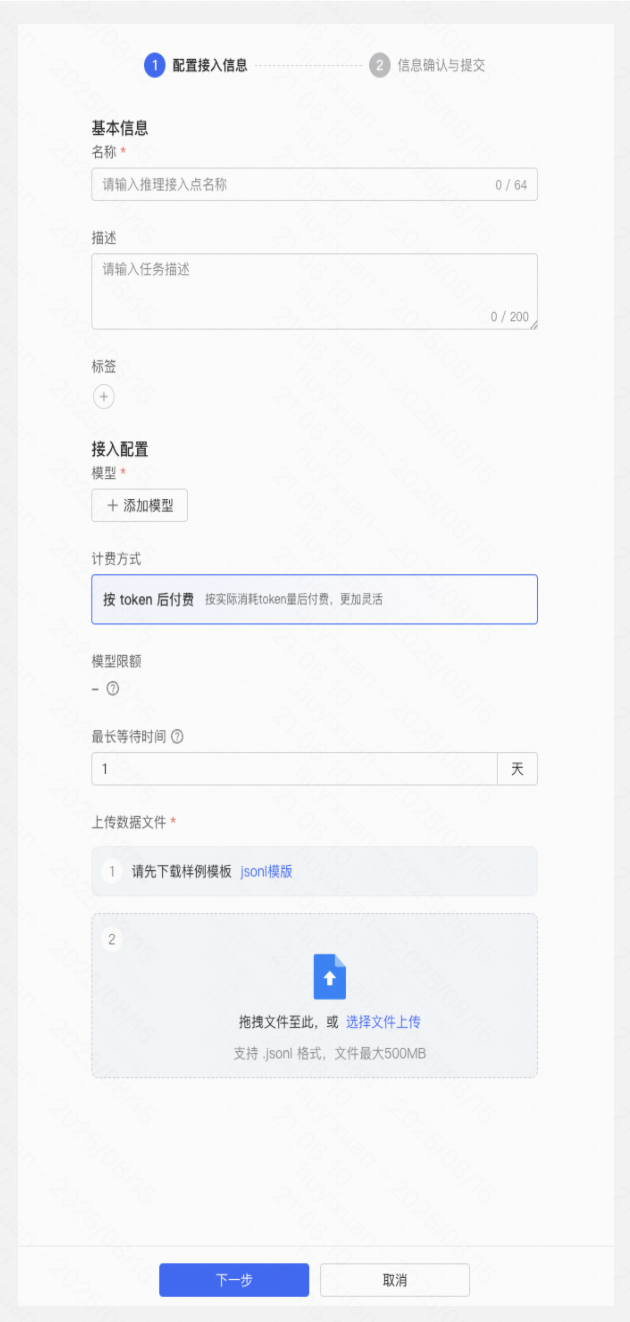
- 确认权限及余额无问题后,进入批量推理页面,点击「新建批量推理任务」,进入创建页面。
- 填写名称、应用描述、标签等基础信息;
- 配置最长等待时间:若任务在设置时间内未全部完成,平台将自动停止该任务,用户可查看已执行的结果文件;
- 上传JSONL格式数据文件。
查看与管理批量推理任务
用户可在任务列表或批量推理任务详情页,查看批量推理任务的信息,包括名称、标签、描述、任务开始时间、接入配置及任务进度信息(包含任务总数、成功及失败数量)。
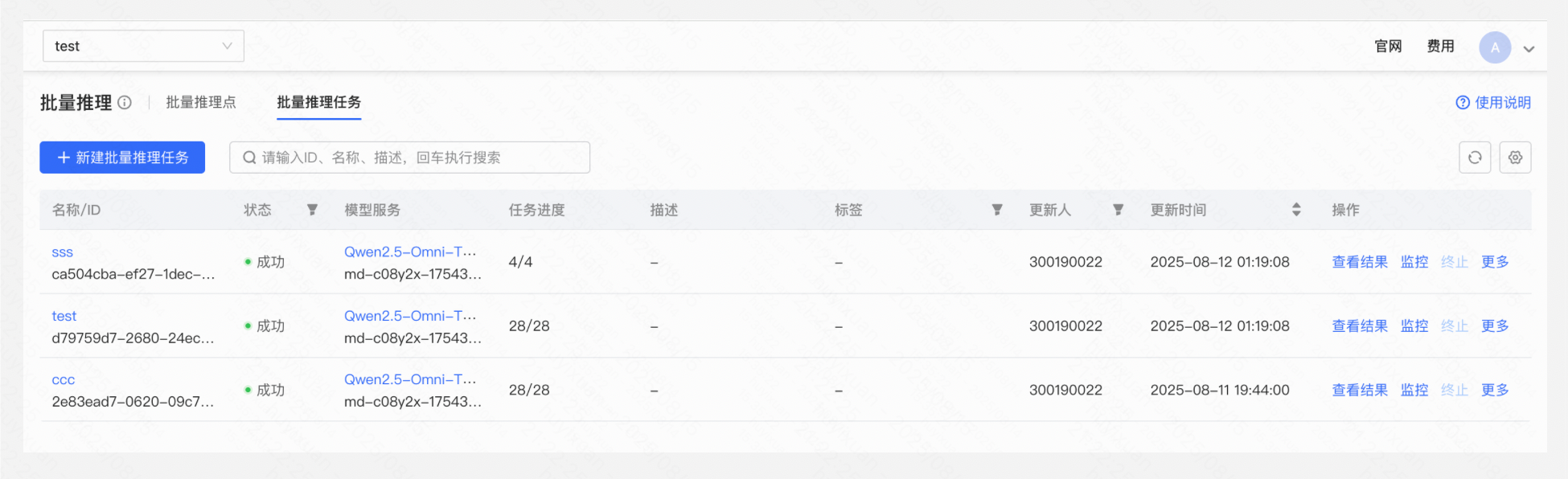
批量推理任务状态
- 初始化:批量推理任务创建中;
- 排队中:由于并发任务数达到上限等原因需排队等候资源调度;
- 运行中:任务处于运行状态中;
- 已完成:任务中所有请求已执行完毕,用户可查看结果文件;
- 终止中:由于超过等待时间或用户手动终止,任务当前处于终止中状态;
- 已终止:任务已被终止;
- 异常:输入文件校验失败或其他原因导致任务失败,用户将鼠标悬浮至异常状态图标处可查看具体的失败原因。
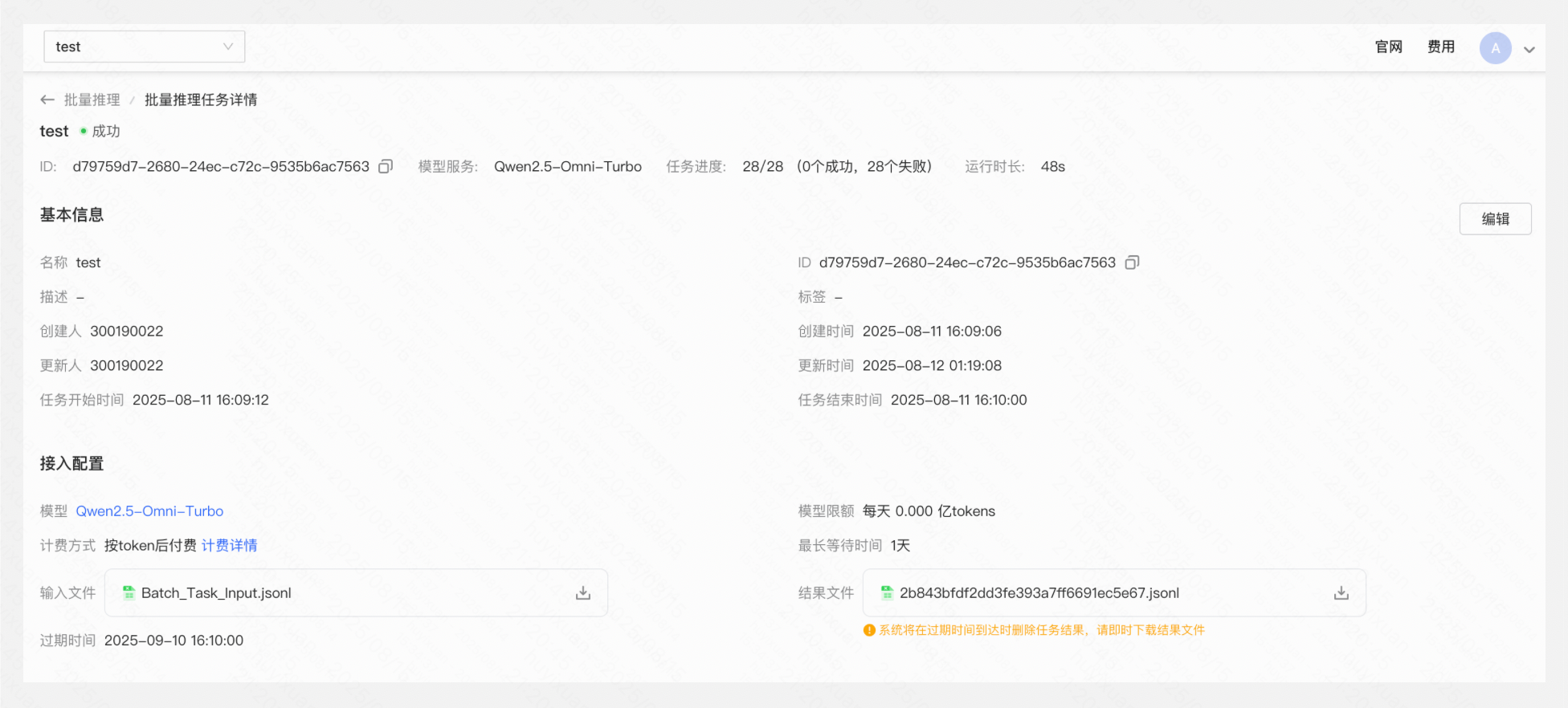
查看结果文件
在推理任务完成后,溪流湖将以短信形式通知,您可点击「查看结果」或在任务详情查看并下载JSONL格式的结果文件。
【⚠️结果文件将在过期后被系统删除,请用户及时下载结果文件】
查看调用监控
您在推理列表或调用监控页面可查看推理的监控记录,平台当前支持用户按天/小时/分钟选择聚合维度,支持自定义查询周期,调用监控最长保留一年,最大查询时间跨度为31天。
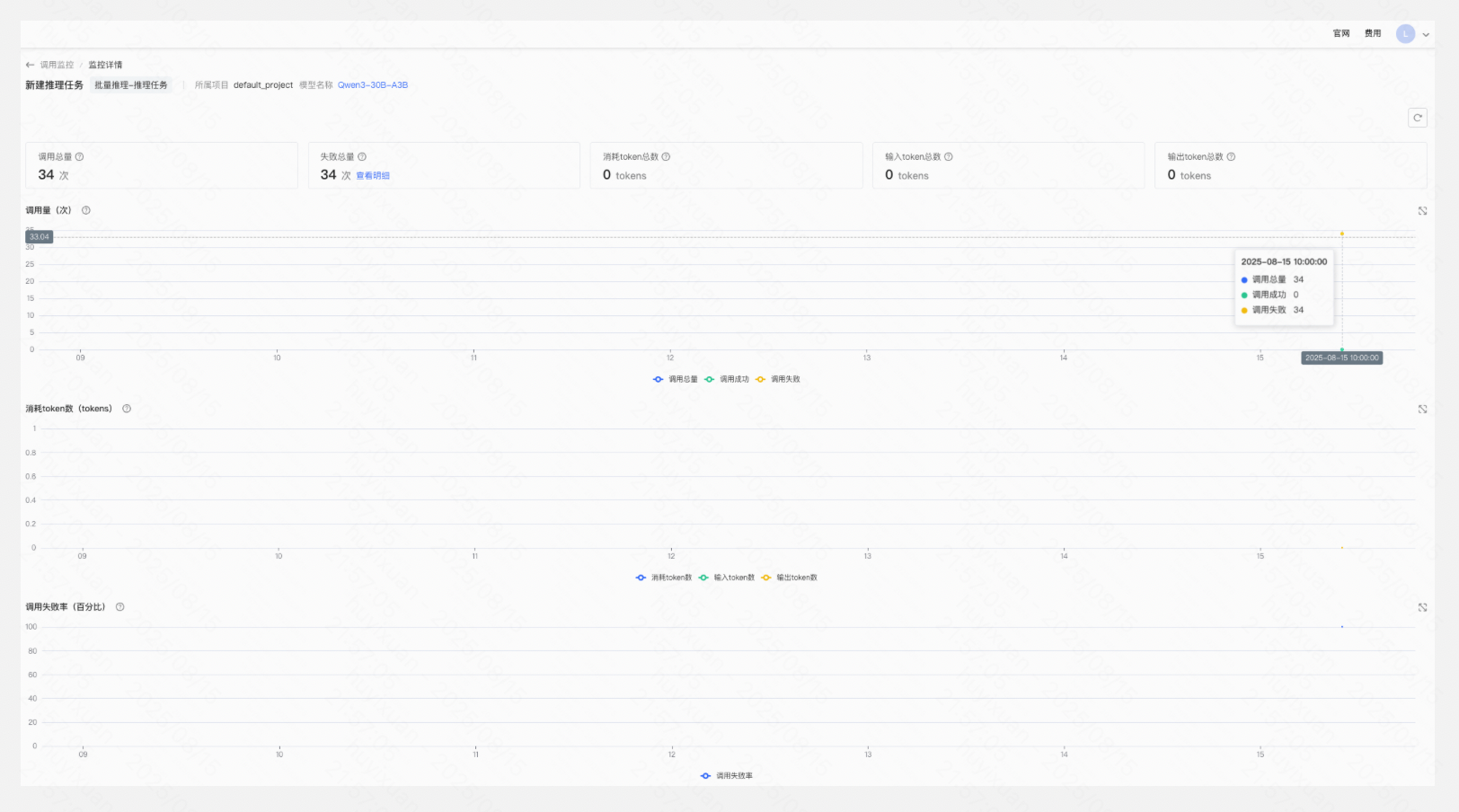
各指标说明
- 调用总量:筛选条件下,发送请求的总数;
- 失败总量:筛选条件下,发送请求失败的总数;
- 消耗token总数:筛选条件下,所有调用输入/输出消耗token的总数;
- 输入token总数:筛选条件下,所有调用输入消耗token的总数;
- 输出token总数:筛选条件下,所有调用输出消耗token的总数;
- 调用失败率(百分比):按聚合维度展示筛选条件下调用失败率(调用失败/调用总量)。