
模型部署
一、概念
模型托管是为降低算力门槛与成本而设计的部署服务。支持将预置、开源或自主微调模型一键部署为专属推理服务,通过预付费、后付费灵活计费,并配合弹性伸缩与高可用能力,快速将模型能力转化为稳定可靠的在线API服务,让用户省去底层资源运维的烦恼。当前平台主要提供【在线部署】能力。
在线部署:无需编写脚本或配置环境,一键将模型部署为可调用API服务,提供专属资源隔离、弹性伸缩与高可用保障,分钟级模型上线
二、模型单元
2.1 定义
万擎将算力从一种复杂、不稳定、难以管理的基础设施,打包为一种简单、可靠、可按需采购的标准化商品(模型单元),提供独占、隔离的专属算力,为用户AI应用建设提供成本、性能、稳定性以及规模化落地的全面保障。
2.2 优势
- 专属算力:平台为模型单元配备独占的算力资源,确保您的服务延迟更低、并发更高,且性能不受其他用户业务波动影响,稳定性显著提升。
- 极简运维:平台承担全部底层基础设施(如服务器、网络、存储)的复杂运维工作。您只需关注业务逻辑与模型效果,从繁琐的资源管理工作中彻底解放。
- 优化成本:对于持续稳定的推理业务(尤其是利用率较高的规模化业务),采用模型单元能获得比按Token计费更显著的成本效益。
- 丰富模型:支持部署平台预置模型、微调后模型,以及您自行上传的模型,为您提供丰富的模型生态。
- 弹性伸缩:后付费模式的服务单元支持配置弹性伸缩策略,您可以根据使用情况进行扩缩容操作,调整实例数量。
- 无硬性限流:平台不设置统一的RPM/TPM上限。您的服务流量上限取决于所部署模型单元的实际承载力,让业务增长不受固定配额限制。
2.3 适用场景
- 需要部署自定义模型(包括微调后模型、用户上传模型)进行大规模、持续性的推理服务。
- 对服务的SLA(服务质量协议)有严格要求的生产环境,追求高并发、低延迟与可控的总体成本。
- 业务流量持续且稳定,能够充分利用预留资源,以实现最佳性价比。
场景建议:对于流量极低或间歇性、偶发性的推理需求,由于需要承载一个模型服务单元的起步资源,其成本优势可能不显著。
2.4 支持模型
具体模型以控制台实际为准:
模型单元 | A型模型单元 | B型模型单元 | C型模型单元 | D型模型单元 | L型模型单元 | M型模型单元 |
适用模型 | Qwen3-8B ... | Qwen2.5-8B Qwen2.5-14B ... | Qwen2.5-32B Qwen3-32B ... | DeepSeek-r1 DeepSeek-v3 Qwen3-235B-A22B-Thinking-2507 ... | Qwen3-4B ... | Qwen3-8B ... |
注意:推荐用户通过模型压测方式选择所需模型单元类型及数量。
三、场景示例
前置准备
1.权限申请:
- 主账号(即溪流湖账户)拥有账号下所有项目的访问/管理权限,无需权限申请,主账号可对所有任务进行修改、删除;
- 子账号:可由主账号为名下子账号设置某项目的只读/管理权限,子账号不支持删除主账号新建的任务;
2.若账户余额不足,请先充值;
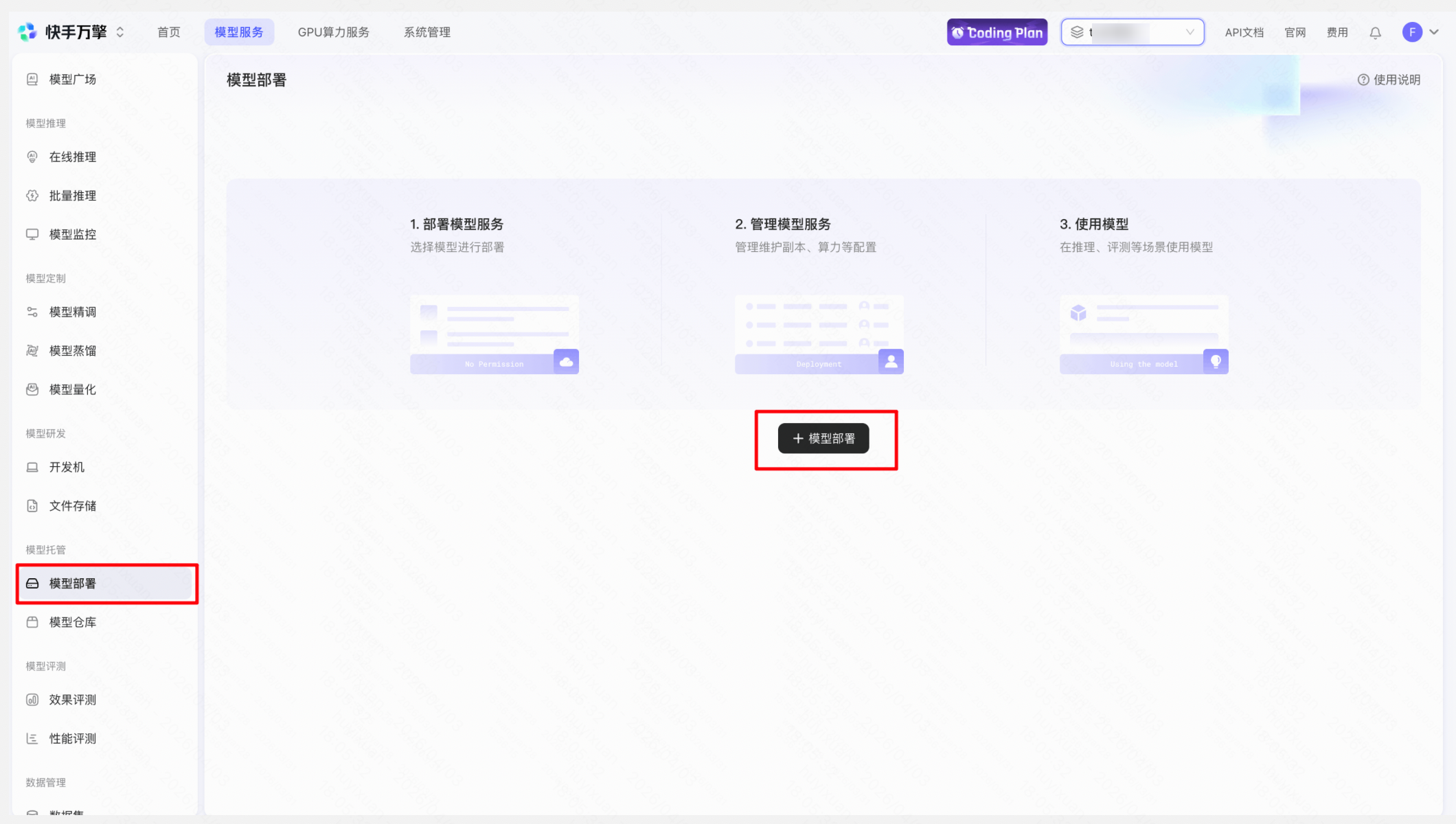
3.确认权限及余额无问题后,在左侧导航栏中「模型托管」下方点击「模型部署」进入产品页面,点击「+模型部署」进入创建页面。
💰 账户额度提示
1. 欠费状态限制:
a. 余额➕信用额度无法覆盖本次任务1小时使用时长所需费用时,将无法正常新建任务
b. 欠费状态下运行中的任务不会中断,当账户状态由欠费变为冻结时,平台将自动释放资源,服务将缩容为0
2. 冻结后使用平台能力:
a. 冻结状态下用户无法新建,请先充值,使账号状态恢复正常
b. 在完成充值后,因冻结被中止的任务【需用户手动操作扩容后】再继续使用,当账户余额➕信用额度可覆盖任务1小时使用时长所需费用时,任务才能恢复运行
3.1 场景一
万擎预置模型部署:用万擎提供的开源模型 → 部署 → 评测 → 创建推理点 → API调用
- 背景:某互联网公司的推荐业务需要长期高频调用大语言模型进行实时内容生成,日均请求量达百万级。此前使用某公有模型API,每月费用高昂且受限于API的并发上限,业务高峰期经常出现限流,影响用户体验。
- 目标:基于平台将预置的开源模型,独立部署为专属推理服务,通过按量付费或包年包月方式控制成本,并利用弹性伸缩能力应对业务波峰。
Step 1:选择开源模型部署为模型服务
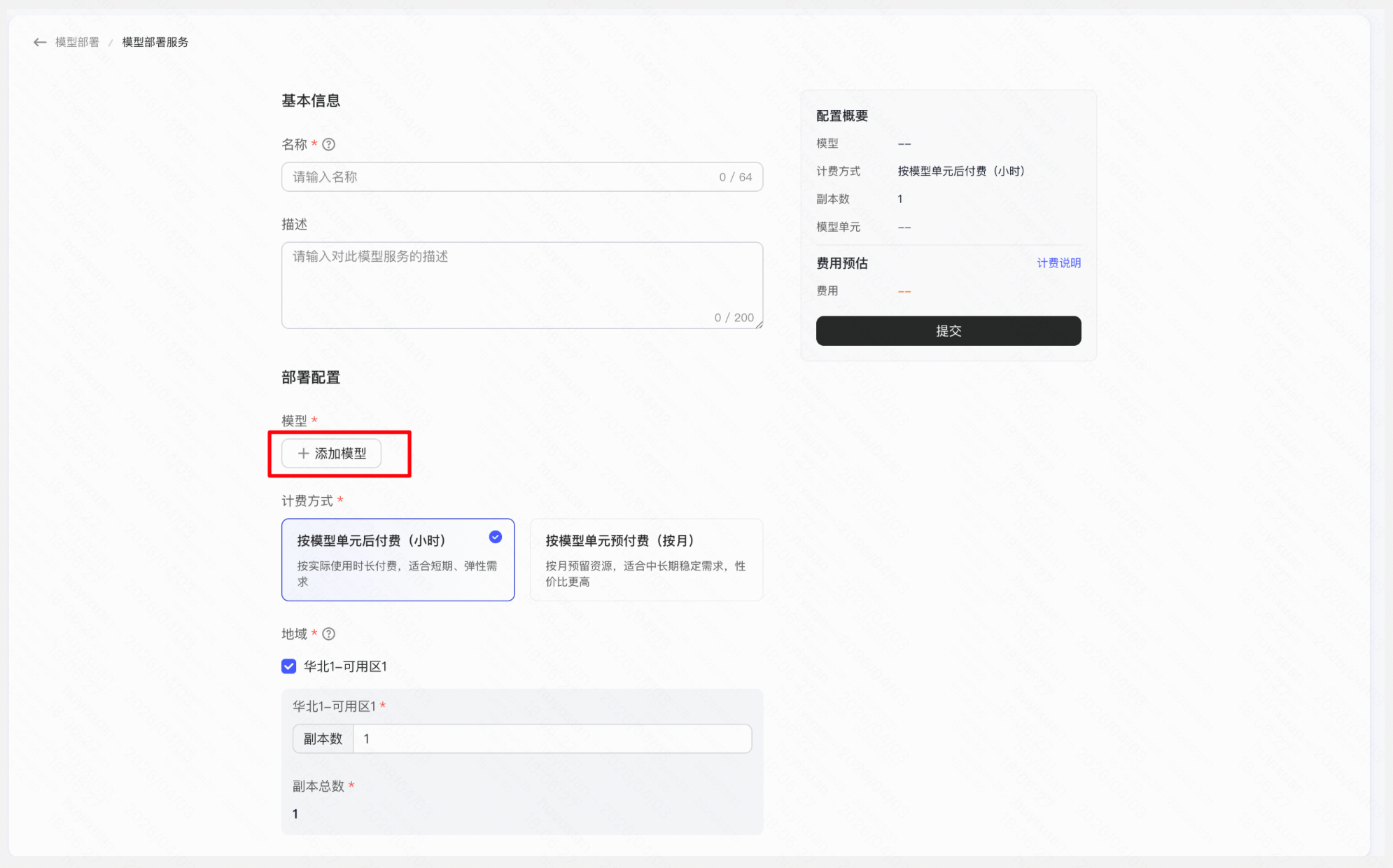
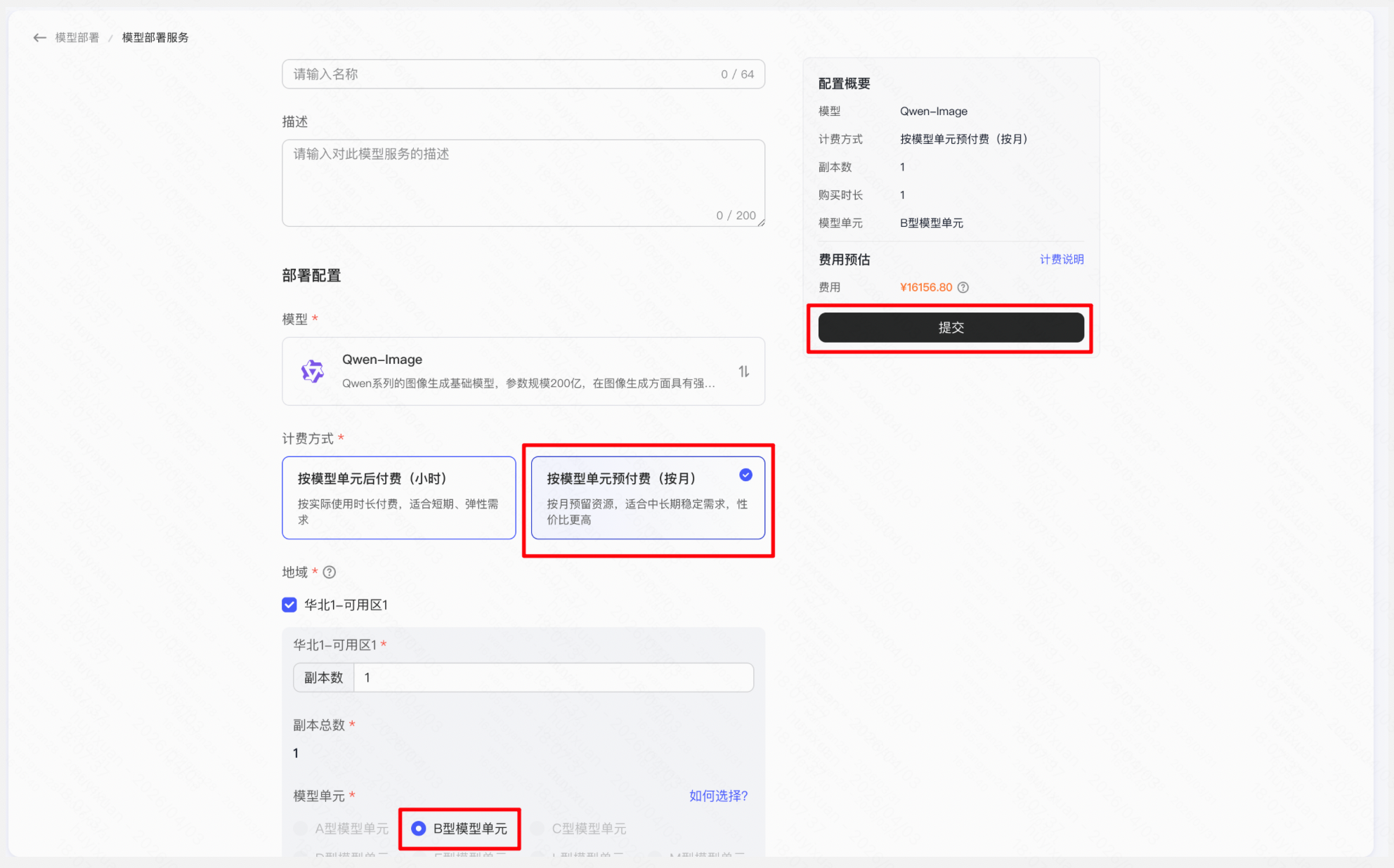
操作「模型部署」 → 「新建模型部署」 → 「添加模型」选择目标开源模型 → 选择资源规格与计费方式(按量/包年包月) → 提交
Step 2:模型评测
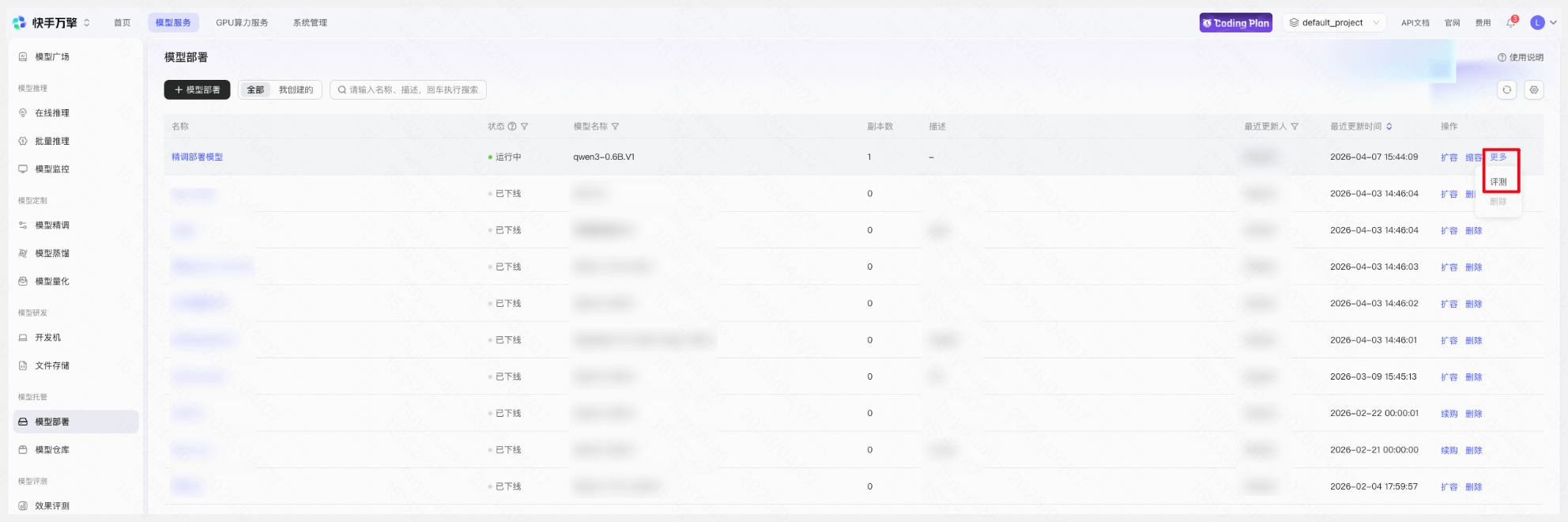
已部署的模型可通过点击评测进入效果评测流程,支持人工评测和自动评测,自动评测可大幅提升评测效率,评测完成后可通过评测详情和评测结果对比模型表现。
操作:「模型部署列表」→「更多-评测」→ 选择评测方式、数据集等配置 → 提交
您也可以创建性能评测任务检验模型在不同压力条件下的推理性能表现,包括延迟、吞吐量、成功率等关键指标,可基于此制定合理的调用策略和限流配置。
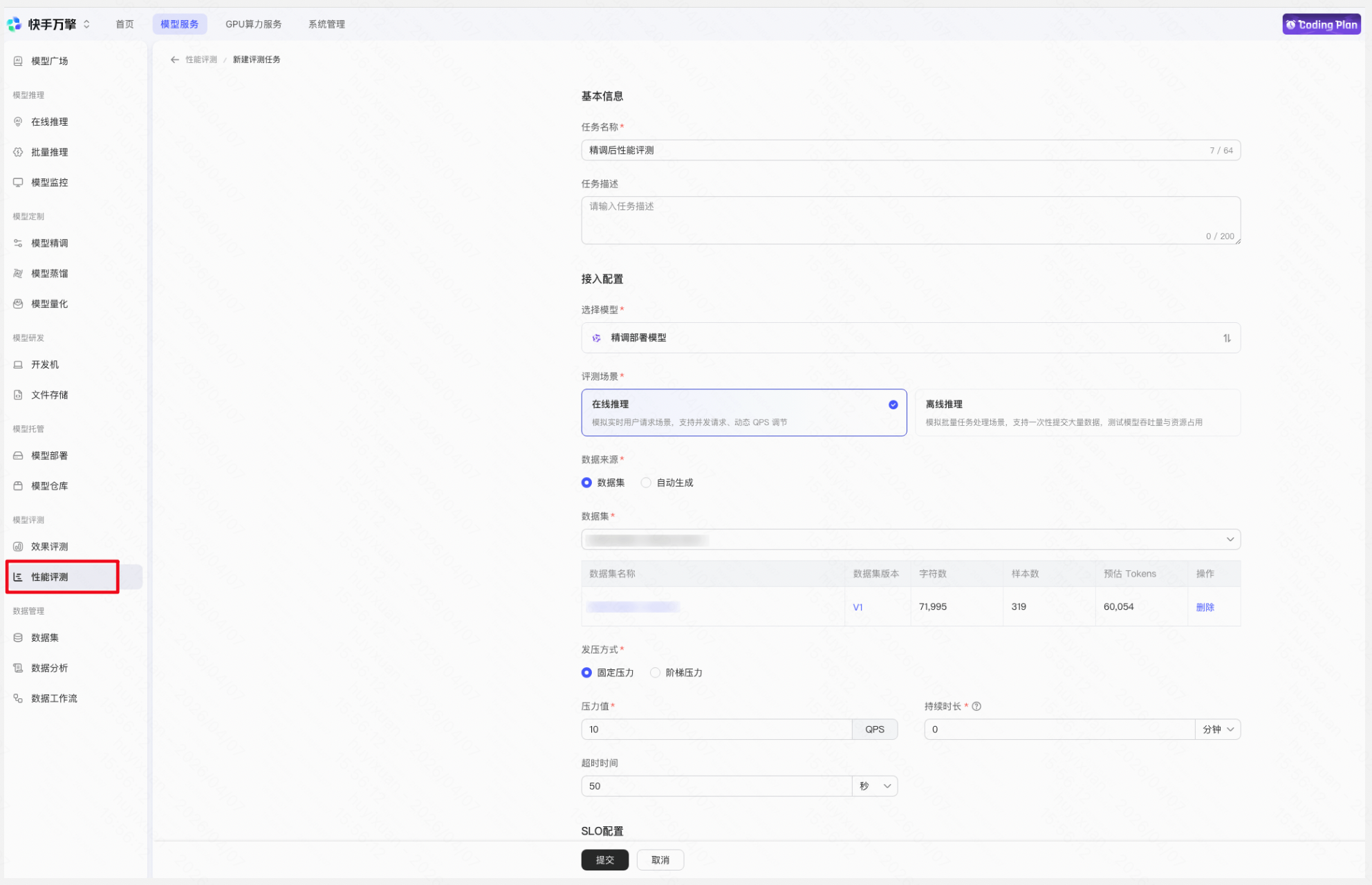
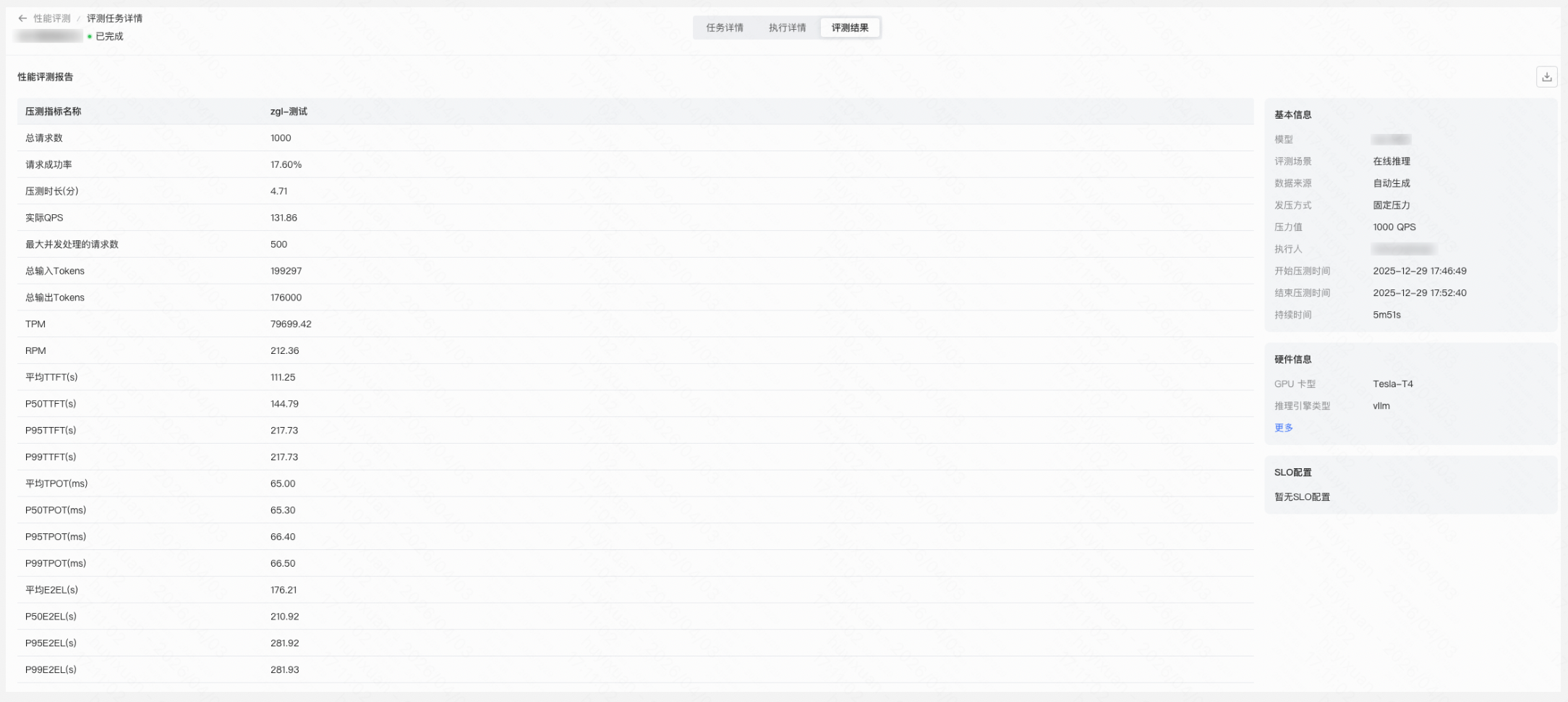
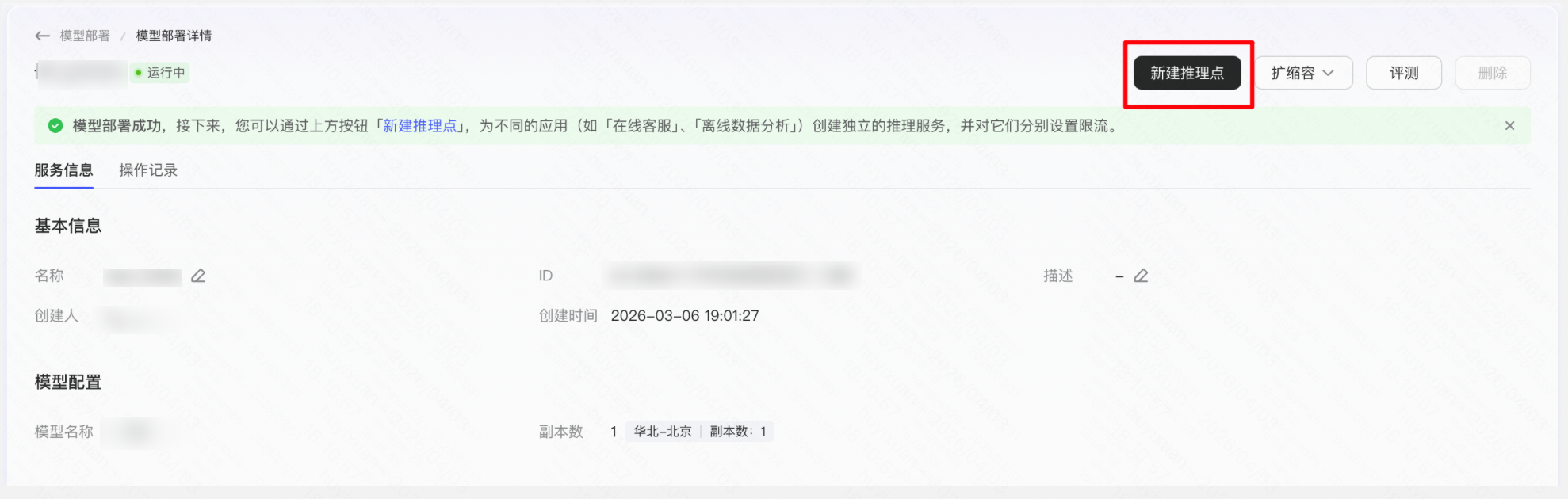
Step 3:部署成功后创建推理点
操作「新建推理点」 → 「设置名称描述等信息」 → 提交
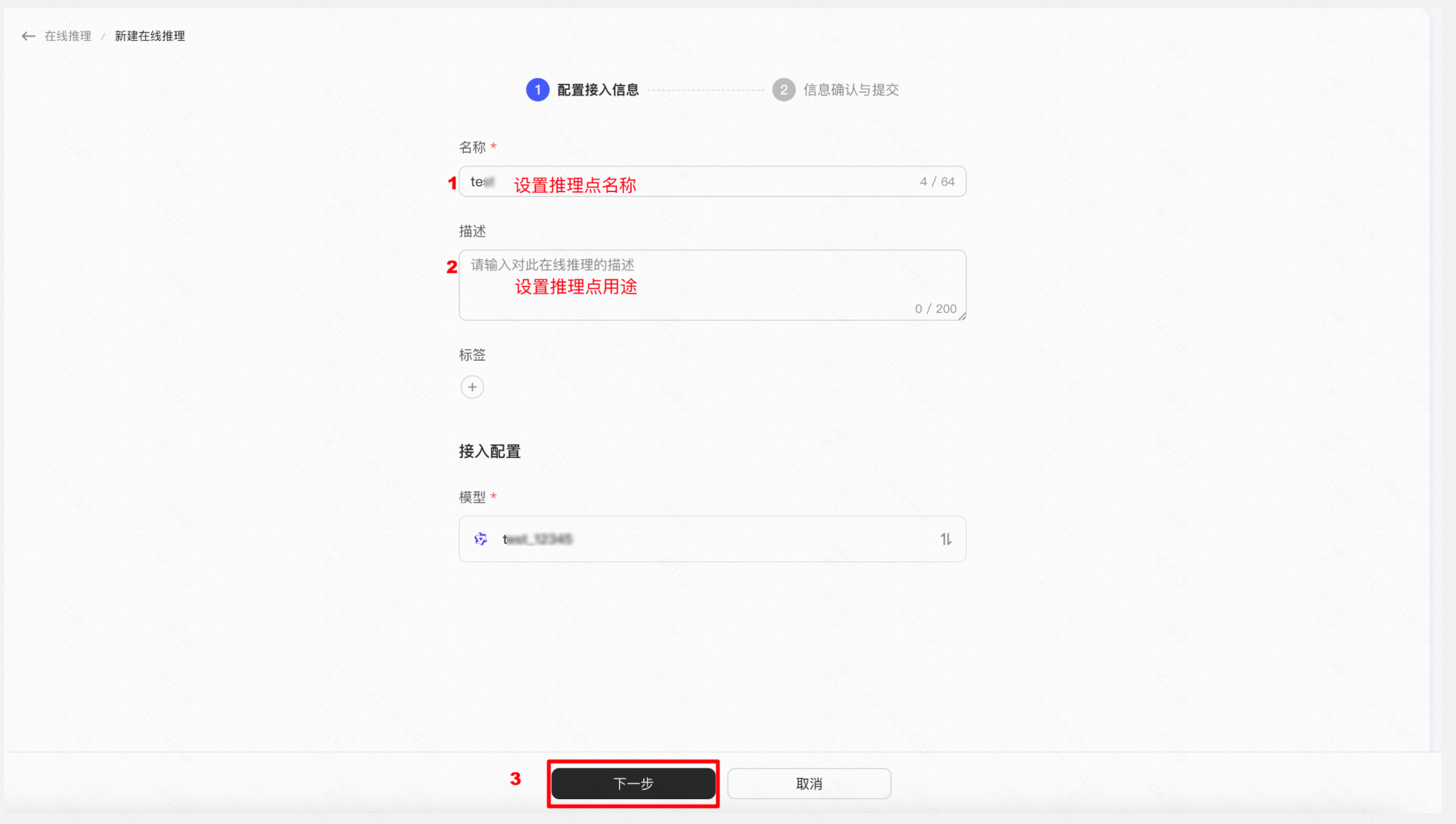
Step 4:API 调用推理点
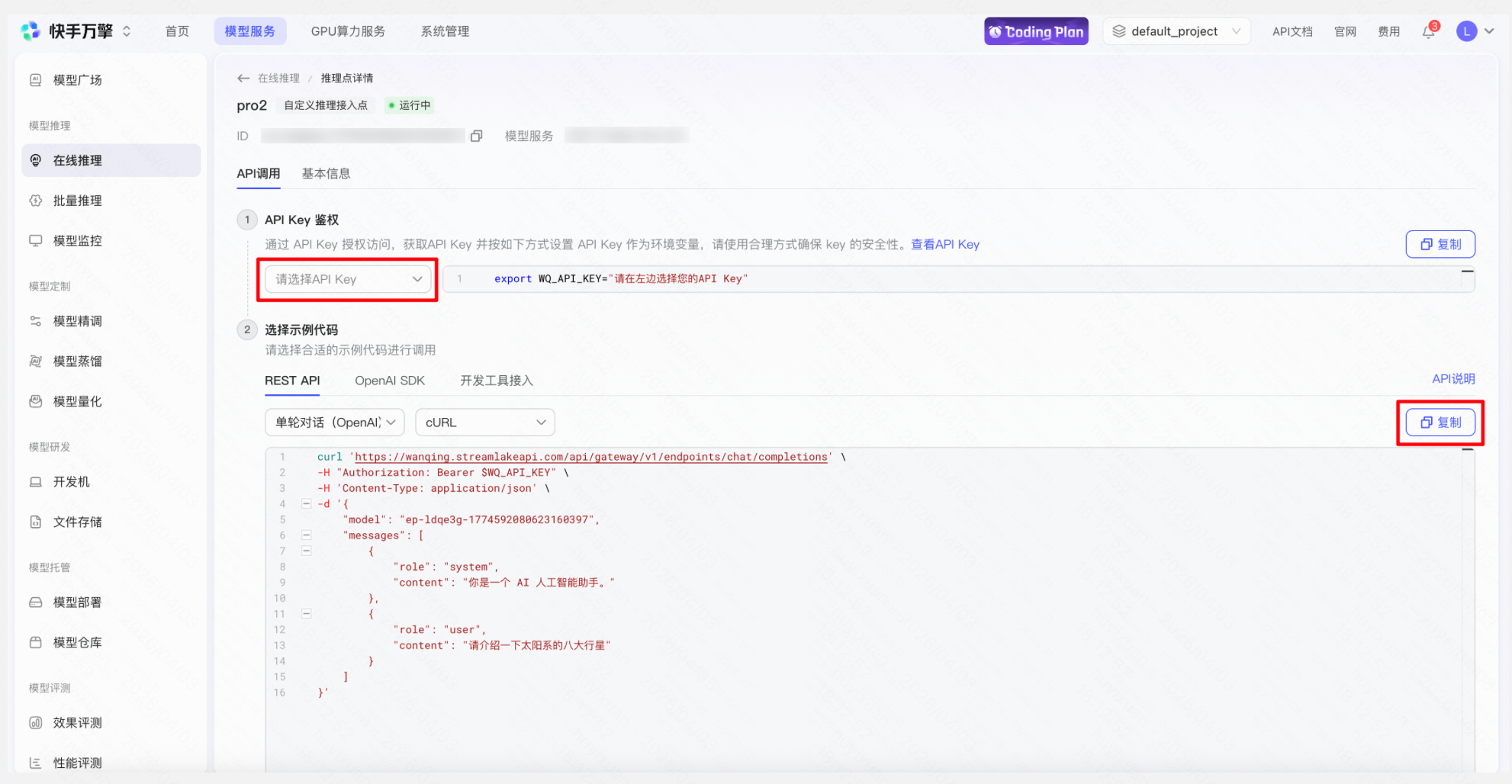
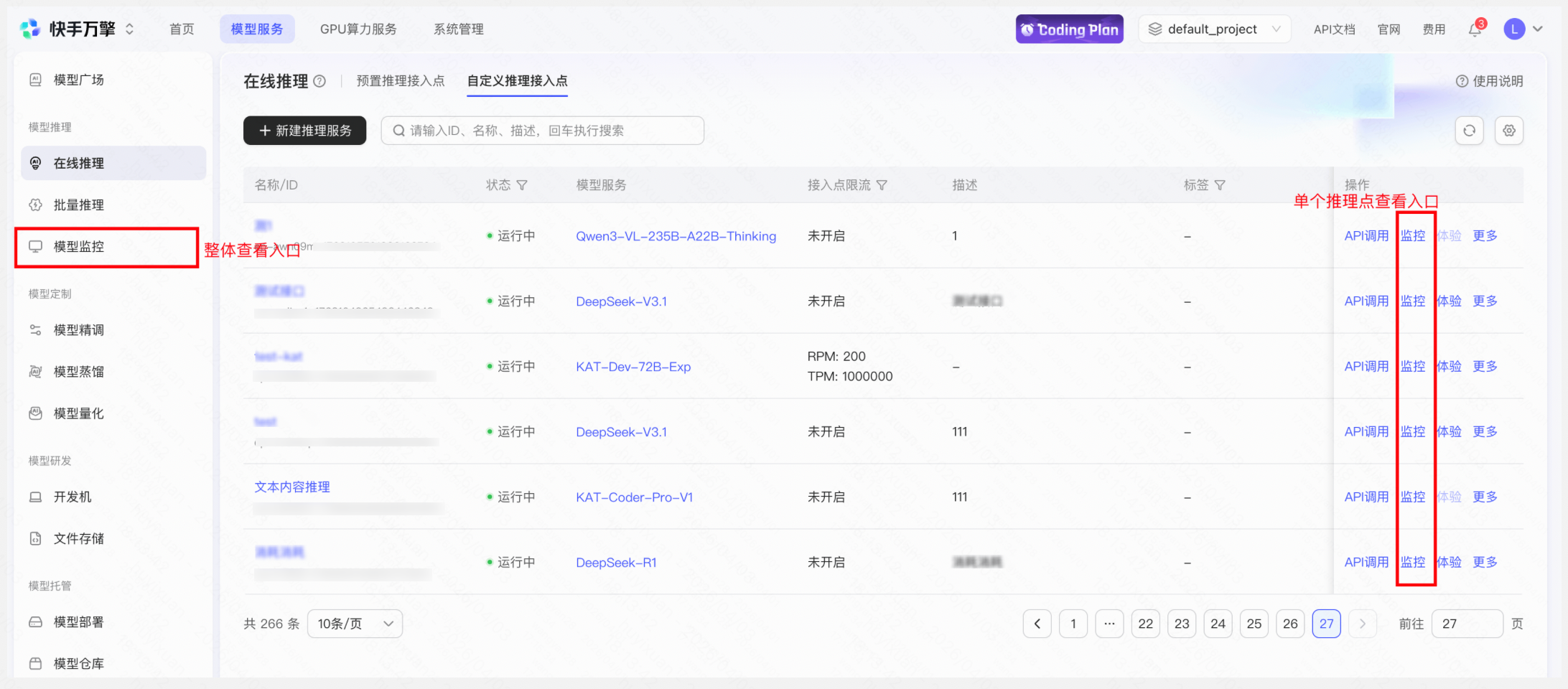
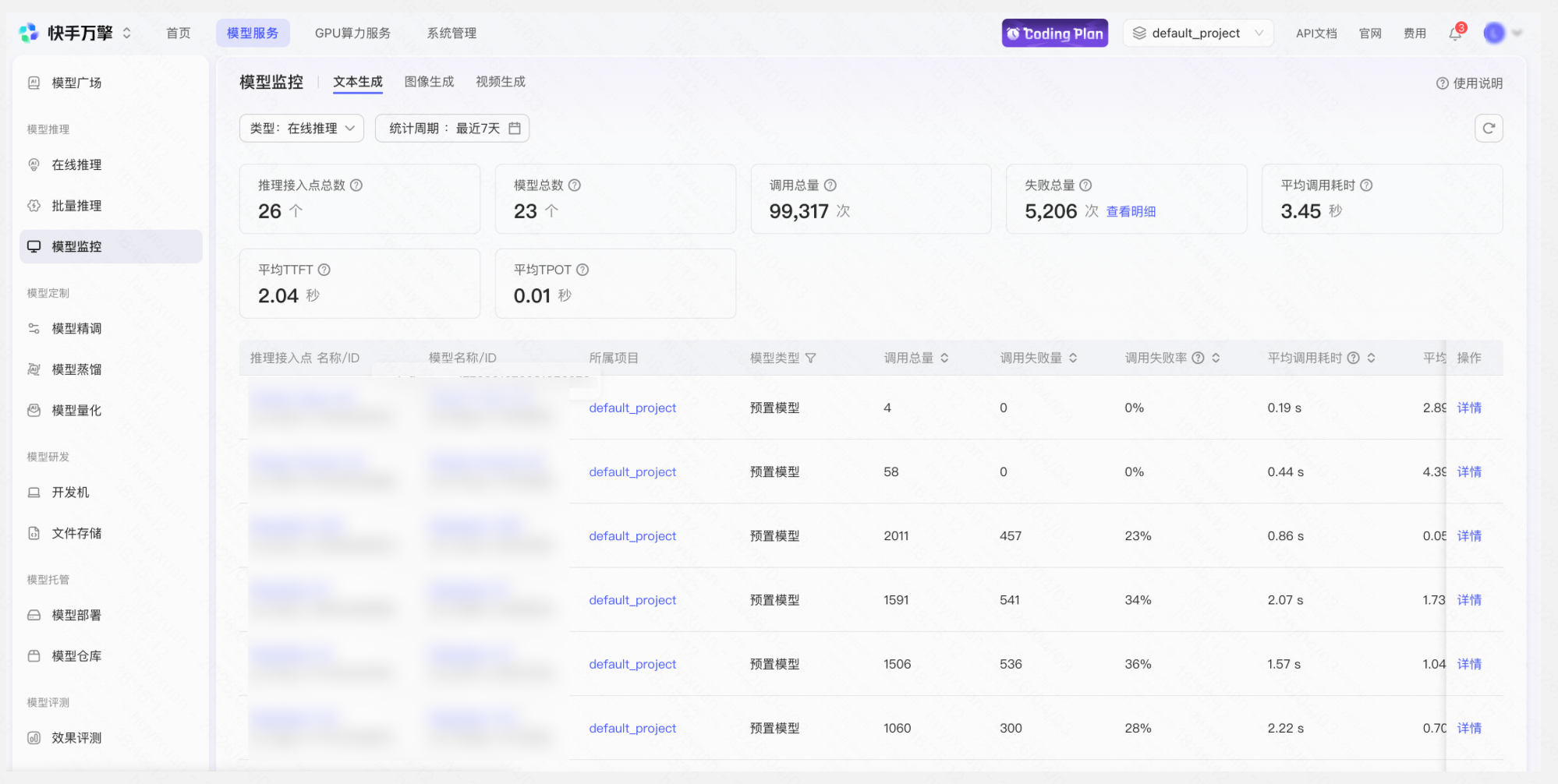
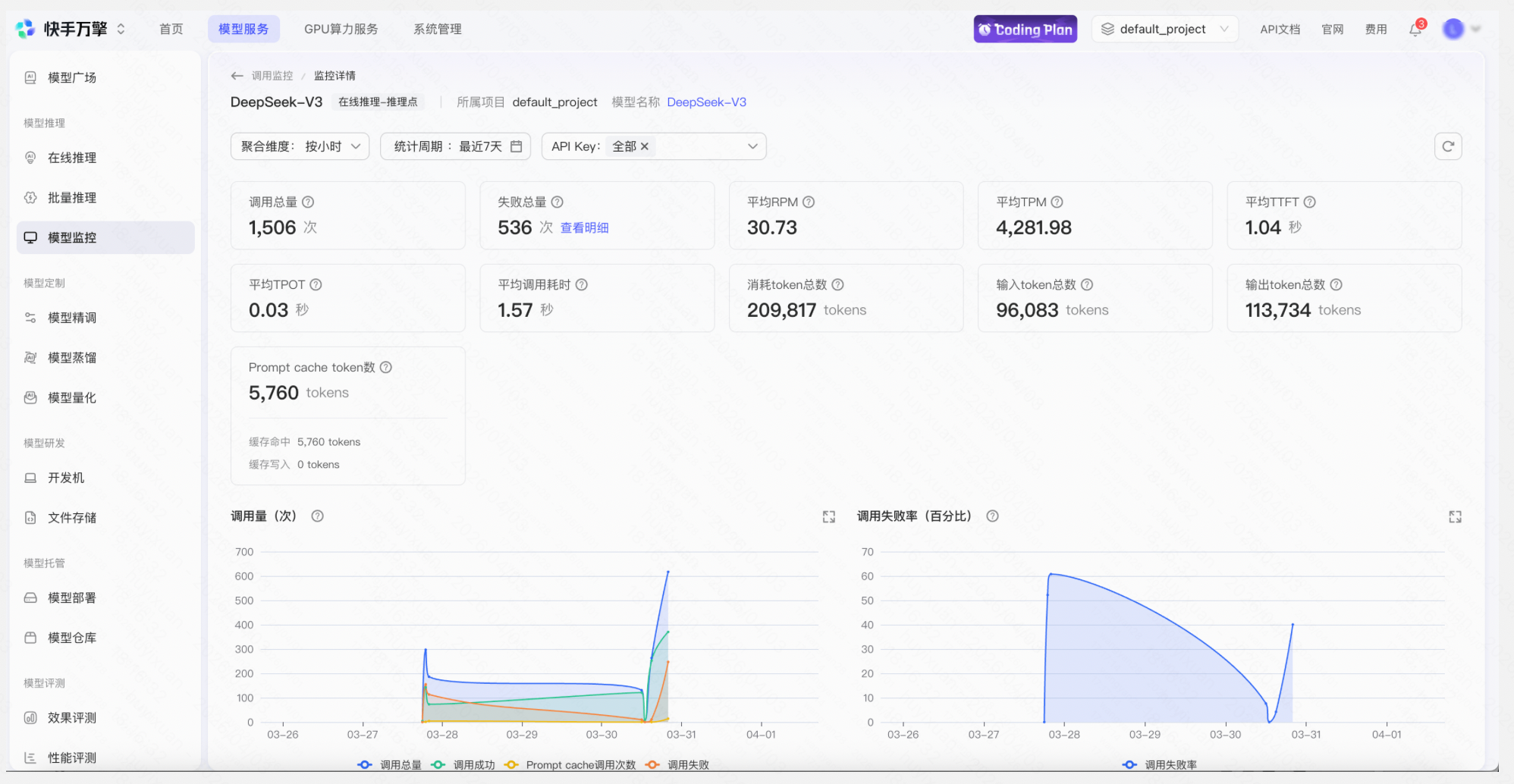
操作「推理点详情」 → 「API调用」Tab → 选择已有API Key 或新建一个API Key → 复制示例代码测试调用→ 查看监控 → 查看用量
3.2 场景二
自主微调后部署:用户自主微调模型上传到平台 → 部署 → 评测 → 创建推理点 → API调用。
- 背景:某电商公司需要对商品评论进行情感分析,基于平台预置的开源模型,使用内部标注的评论数据在平台内进行微调,以获得适配电商场景的情感分类模型。
- 目标:在平台内完成模型微调,将微调后产生的模型直接部署为API服务,并创建推理点供业务系统调用。
Step 1:在平台内微调模型
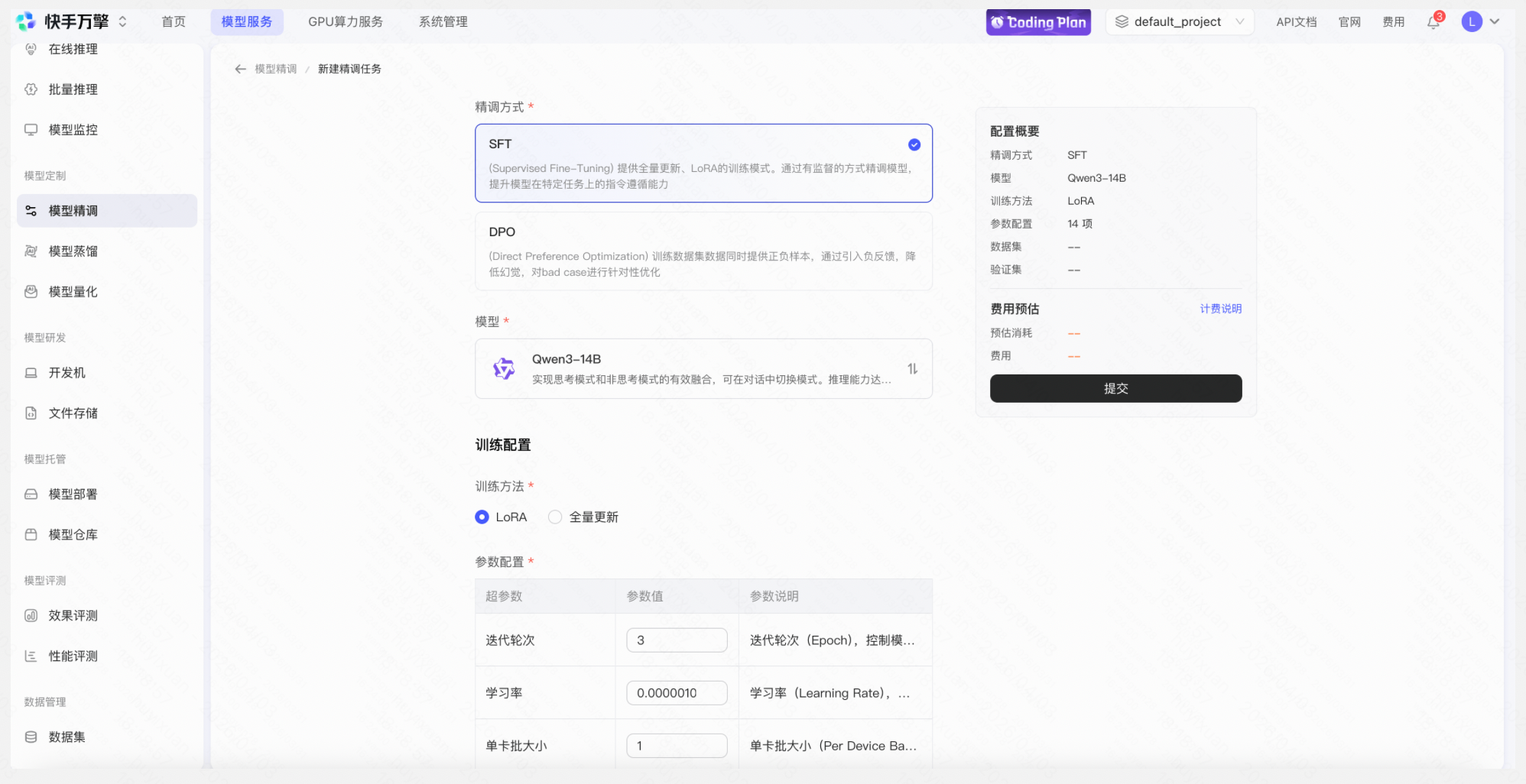
操作: 点击「新建模型精调」→ SFT--LoRA- → 选择预置开源模型→ 上传训练数据并选择→ 配置微调参数(学习率、训练轮数等)→ 提交微调任务 → 等待任务完成,平台自动生成微调后的模型
提交微调任务
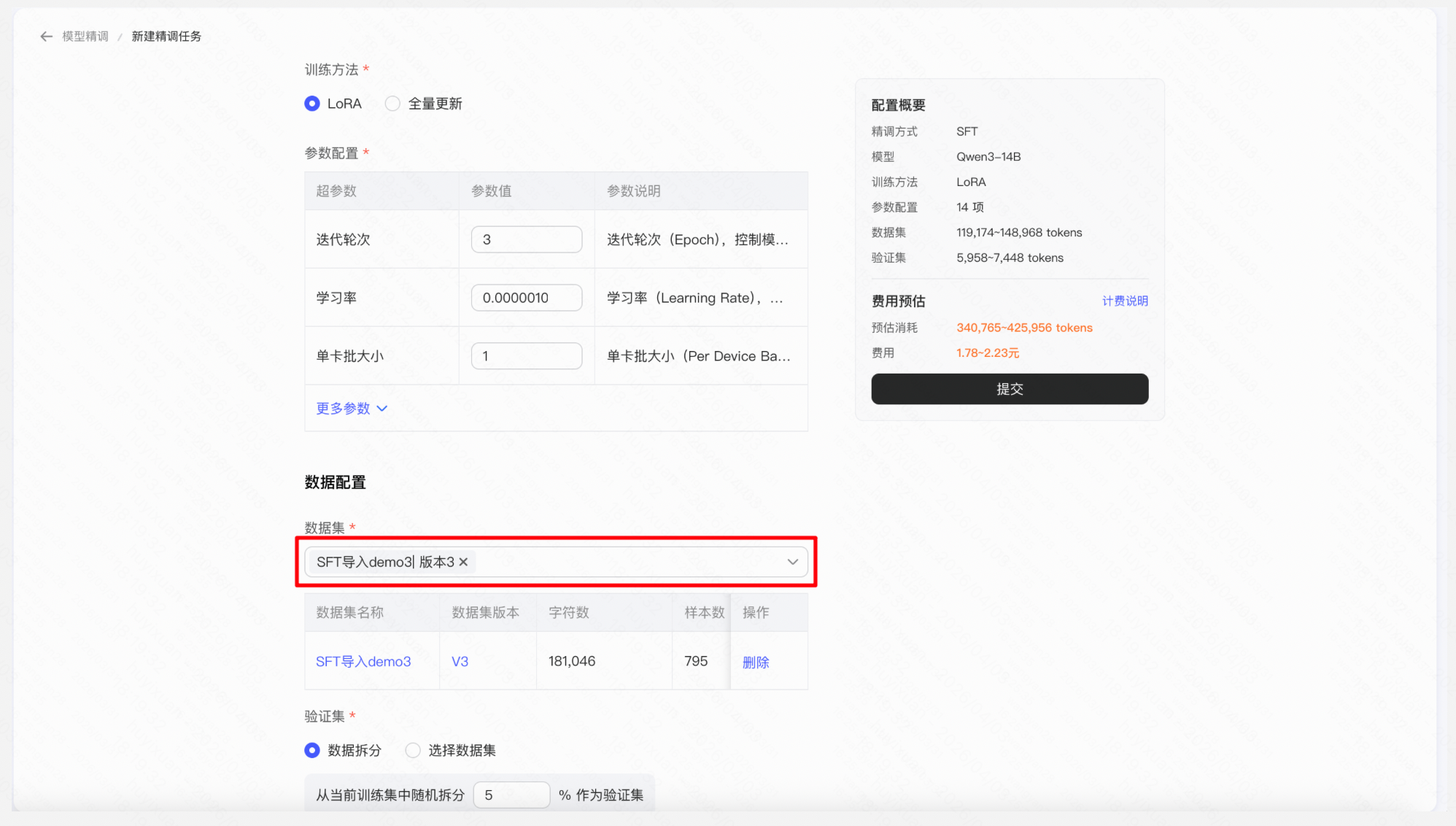
数据集上传
Step 2:部署微调后的模型
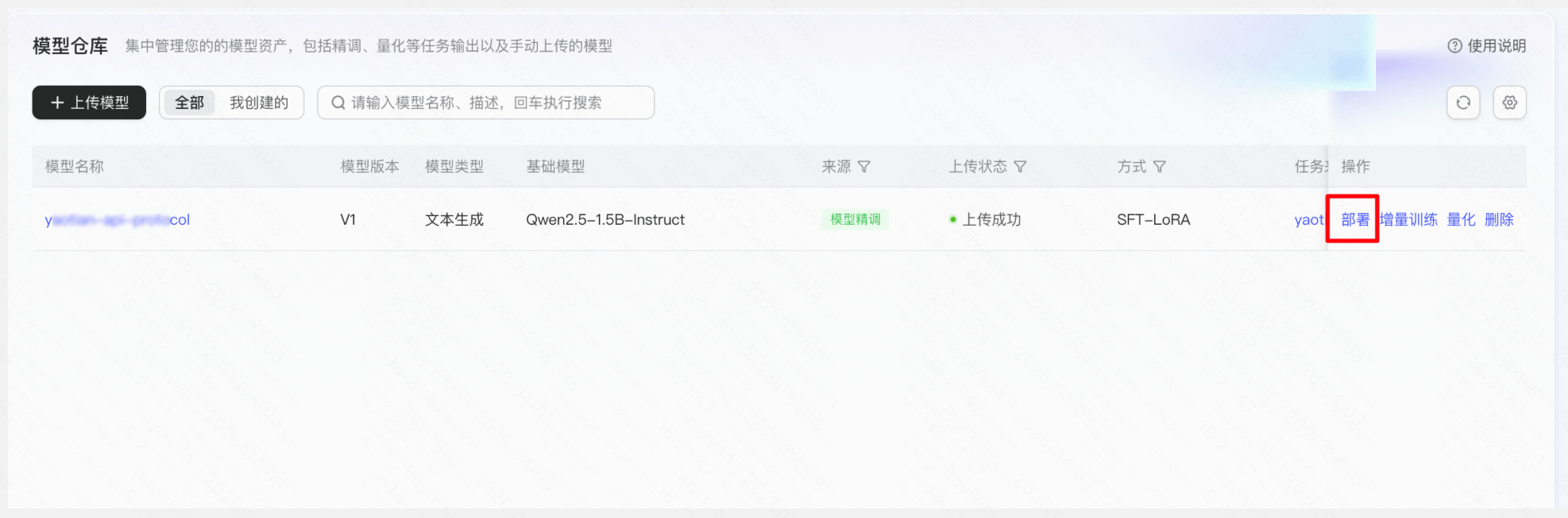
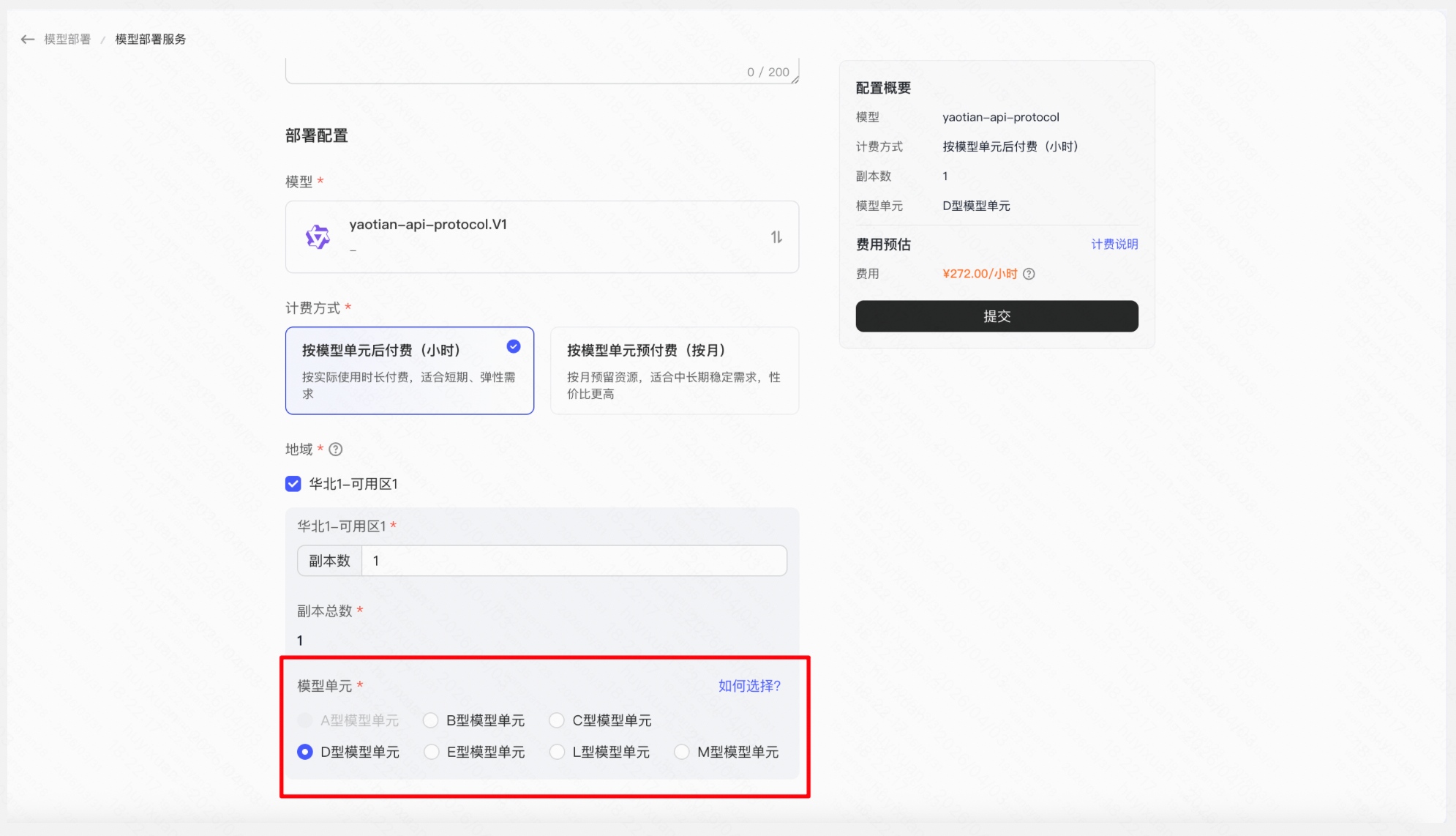
操作:「模型仓库」→ 找到微调生成的模型版本 → 点击「部署」→ 选择资源规格与计费方式 → 提交
Step 3:模型评测
已部署的模型可通过点击评测进入效果评测流程,支持人工评测和自动评测,自动评测可大幅提升评测效率,评测完成后可通过评测详情和评测结果对比模型表现。
操作:「模型部署列表」→「更多-评测」→ 选择评测方式、数据集等配置 → 提交
您也可以创建性能评测任务检验模型在不同压力条件下的推理性能表现,包括延迟、吞吐量、成功率等关键指标,可基于此制定合理的调用策略和限流配置。
Step 4:创建推理点
操作「新建推理点」 → 「设置名称描述等信息」 → 提交
Step 5:API调用推理点
操作「推理点详情」 → 「API调用」Tab → 选择已有API Key 或新建一个API Key → 复制示例代码测试调用→ 查看监控 → 查看用量
3.3 场景三
开源模型部署:用户将开源社区模型上传到平台 → 部署 → 评测 → 创建推理点 → API调用。
- 背景:某法律科技公司基于开源基座模型,使用内部法律文书数据进行了全参数微调,得到一个专业的法律问答模型。模型文件(含配置、权重)约30GB,需要部署为内部系统可调用的API服务,并支持多部门调用和流量控制。
- 目标:将自主微调后的模型上传至平台,部署为专属推理服务,并通过推理点实现部门级限流与调用管理。
Step 1:将模型以非公开方式上传到ModelScope 或 HuggingFace
可参考对应平台帮助文档:ModelScope|HuggingFace
Step 2:上传微调后的模型到平台
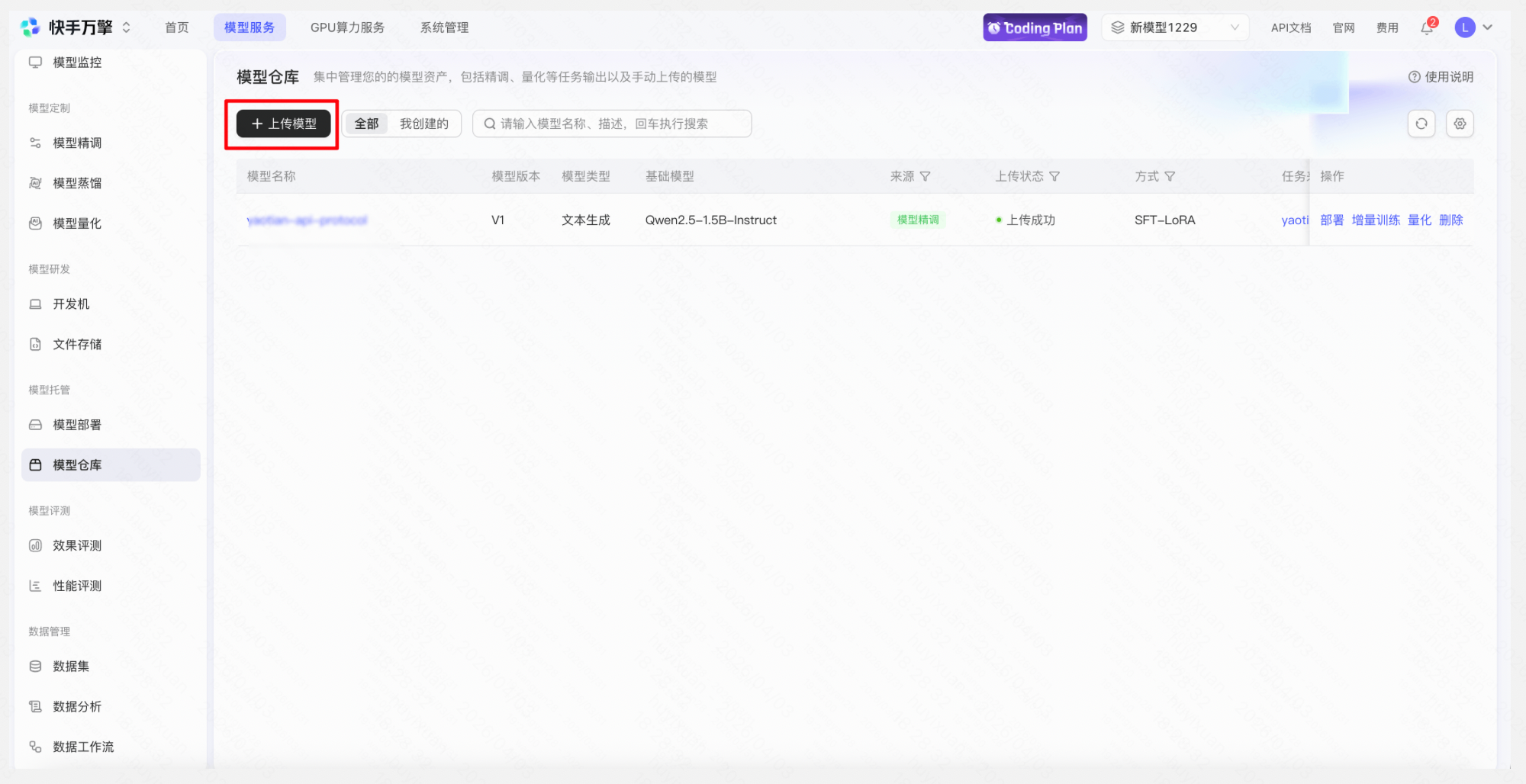
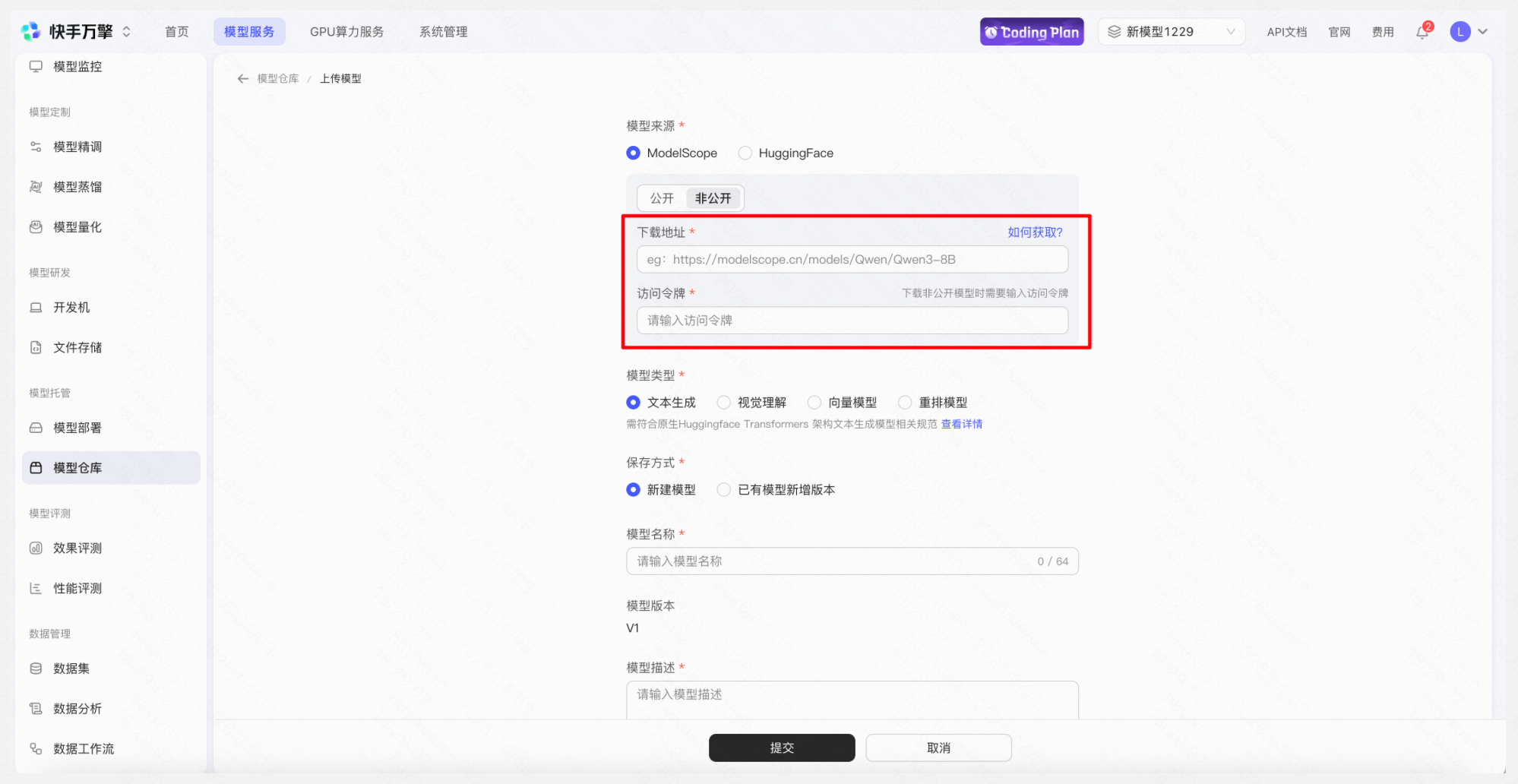
操作:「模型仓库」→「上传模型」→ 填写刚上传的模型地址、访问令牌 → 设置对应的模型类型、保存方式等信息 → 提交
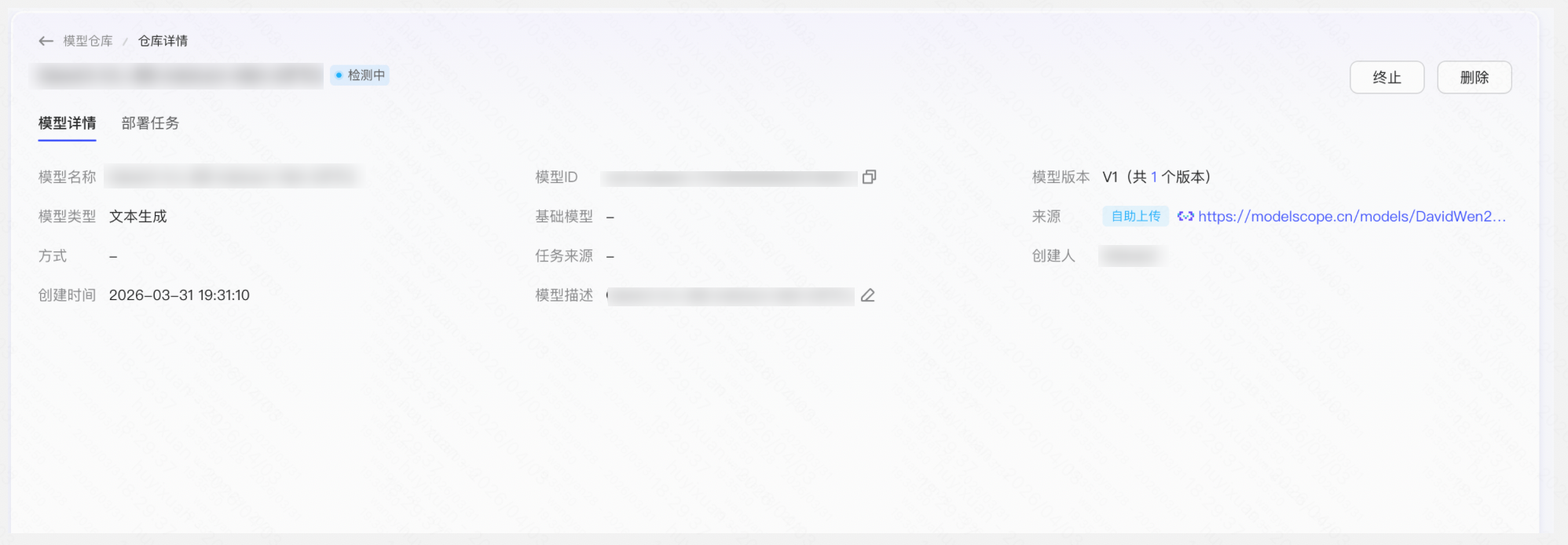
Step 3:部署模型为服务
操作:「模型仓库」→ 找到刚上传的模型 → 点击「部署」→ 选择资源规格与计费方式(按量/包年包月)→ 提交
Step 4:模型评测
已部署的模型可通过点击评测进入效果评测流程,支持人工评测和自动评测,自动评测可大幅提升评测效率,评测完成后可通过评测详情和评测结果对比模型表现。
操作:「模型部署列表」→「更多-评测」→ 选择评测方式、数据集等配置 → 提交
您也可以创建性能评测任务检验模型在不同压力条件下的推理性能表现,包括延迟、吞吐量、成功率等关键指标,可基于此制定合理的调用策略和限流配置。
Step 5:创建推理点
操作「新建推理点」 → 「设置名称描述等信息」 → 提交
Step 6:API调用推理点
操作「推理点详情」 → 「API调用」Tab → 选择已有API Key 或新建一个API Key → 复制示例代码测试调用→ 查看监控 → 查看用量