
自定义任务 ms-swift 最佳实践
本文介绍如何通过用ms-swift对Qwen2.5-0.5B-Instruct小模型进行LoRA微调,目的是训练模型学会"自我认知"以及基本的对话能力。
准备训练模型、数据集
1.默认:万擎平台使用modelscope作为模型与数据仓库。默认支持的模型与数据集如下:支持的模型与数据集。
2.自定义模型与数据:可在训练前将源模型,数据集及其他相关文件上传至ModelScope后,在后续填写模型时,填写ModelScope地址,教程可查看:ModelScope模型上传 | ModelScope数据集上传。
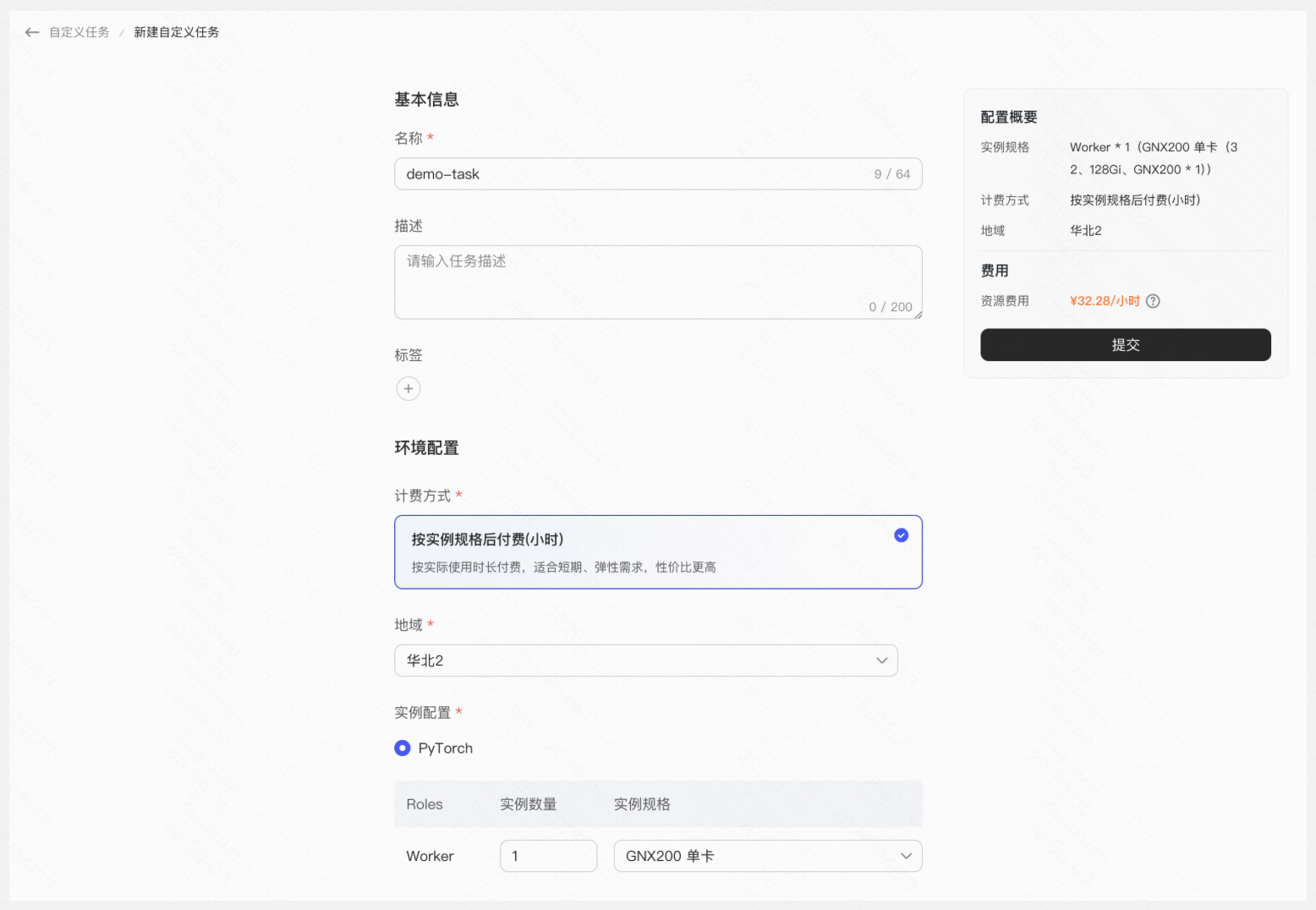
设置基础配置
选项 | 含义 |
地域 | 选择计算资源所处位置 |
实例配置 | 选择训练方法,当前仅支持PyTorch选项 |
Roles | 选择规格。目前实例规格仅支持GNX200,worker数量=多机训练数量,实例规格数量=单机训练卡数量 实际卡数=worker数量*规格数量 |
镜像 | 当前仅支持ms-swift框架训练 |
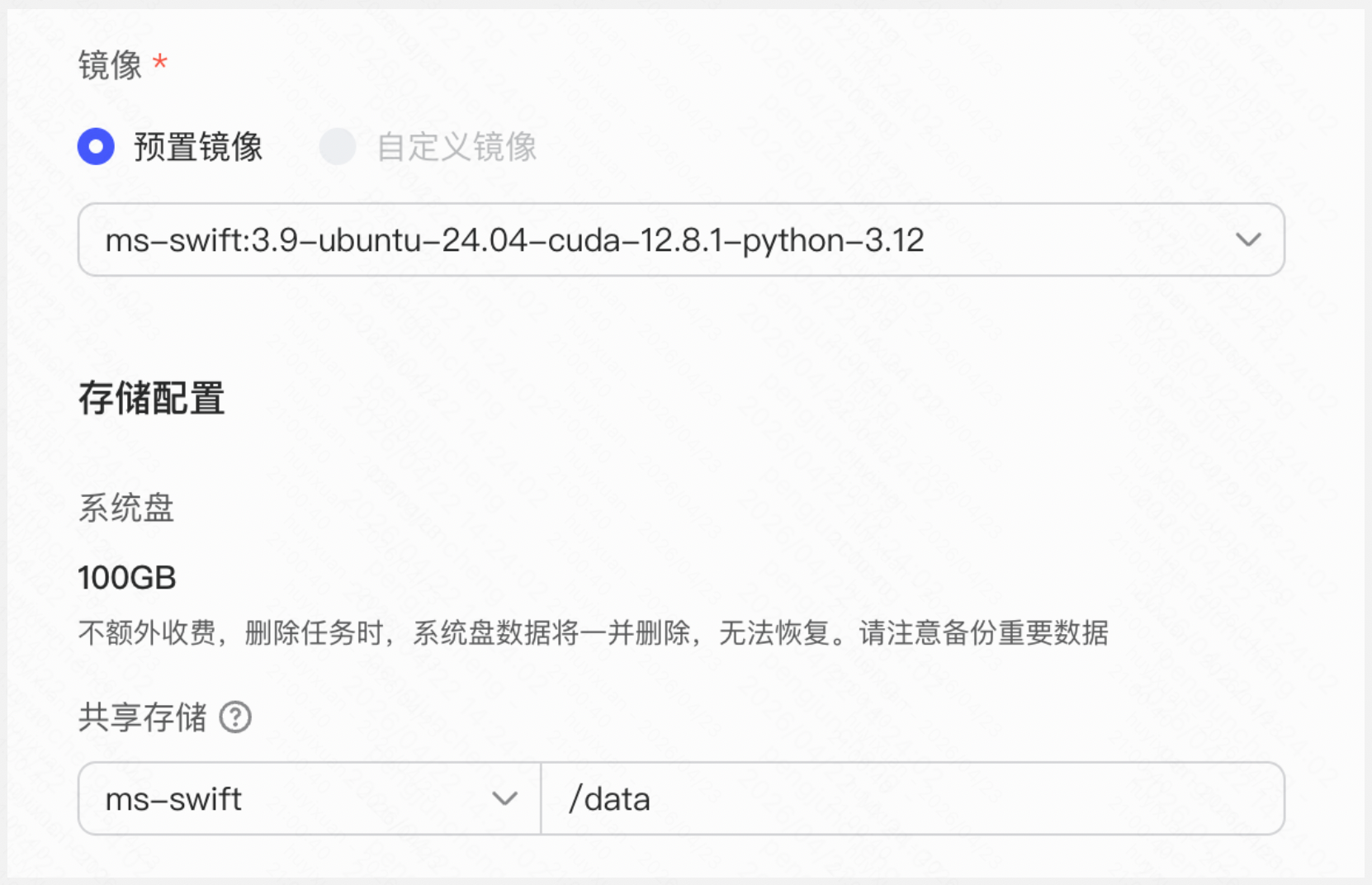
共享存储 | 可用于保存训练完成的模型参数,可选择除/kfs目录外(多机训练共享目录)的任意目录挂载,挂载后会以普通文件夹形式存在,当任务完成后,仅共享存储内的文件不会销毁。 建议挂载存储,否则无法保存训练后数据! |
配置如下所示:
swift命令设置
启动命令如下:
swift sft --model Qwen/Qwen2.5-0.5B-Instruct --train_type lora --dataset AI-ModelScope/alpaca-gpt4-data-zh#50 AI-ModelScope/alpaca-gpt4-data-en#50 swift/self-cognition#50 --torch_dtype bfloat16 --num_train_epochs 1 --per_device_train_batch_size 1 --per_device_eval_batch_size 1 --learning_rate 1e-4 --lora_rank 8 --lora_alpha 32 --target_modules all-linear --gradient_accumulation_steps 16 --eval_steps 5 --save_steps 50 --save_total_limit 2 --logging_steps 5 --max_length 2048 --output_dir "/kfs/trainedModels" --system "You are a helpful assistant." --warmup_ratio 0.05 --dataloader_num_workers 4 --model_name Qwen --model_author Alibaba --logging_dir "$TENSORBOARD_OUTPUT_PATH"
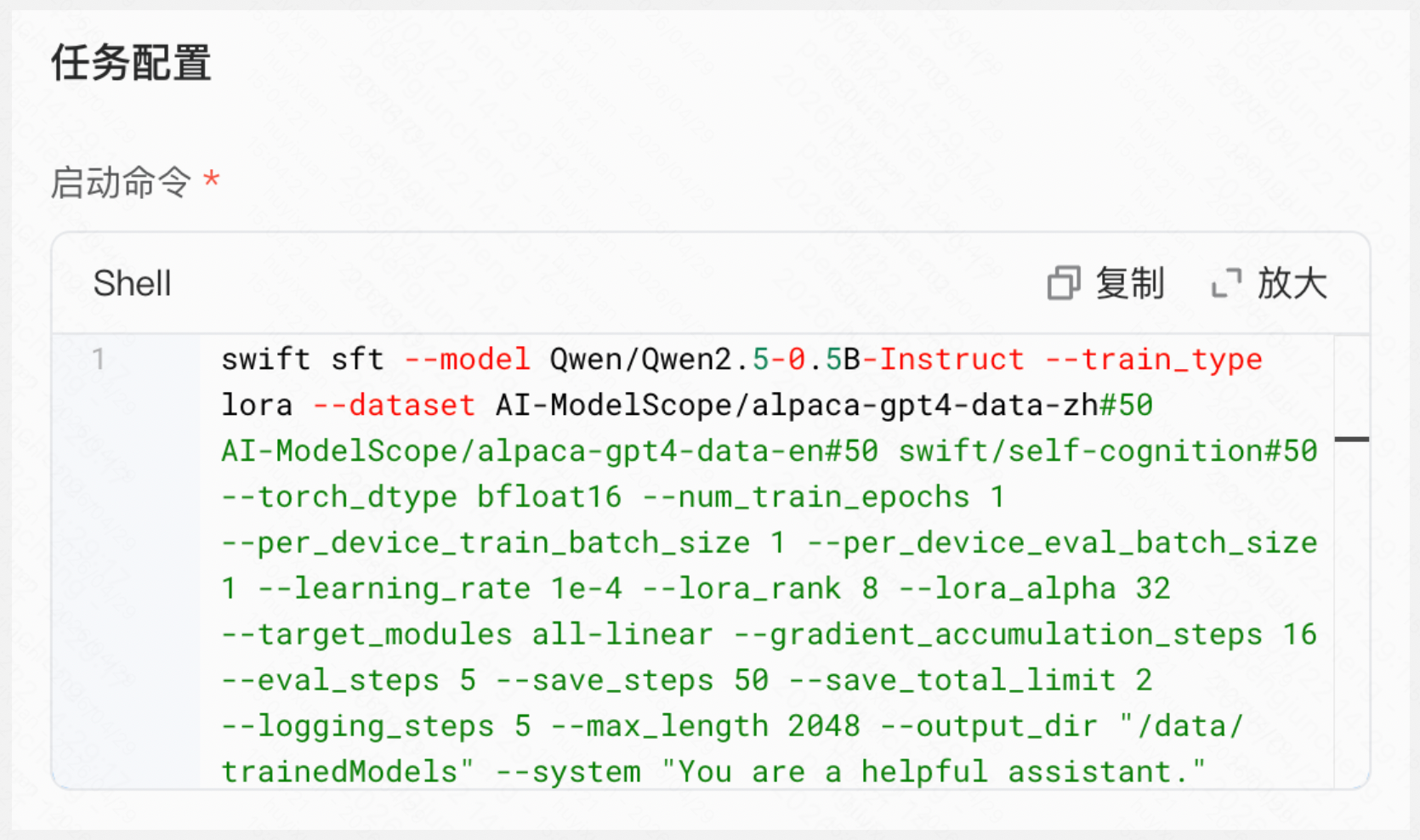
自定义任务支持ms-swift全量参数配置,部分参数解析如下:
参数 | 含义 | 备注 |
sft | 监督微调训练 | |
model | 模型名称,此处训练Qwen2.5-0.5B-Instruct | 支持的模型列表:支持的模型仅支持modelscope下载 |
train_type | 训练方式,此处使用LoRA微调 | |
dataset | 数据集名称 | 默认数据集:支持的数据集 仅支持modelscope下载 |
torch_dtype | 训练精度 | 支持:bfloat16 ,float16,float32,None(默认,框架自动判断) |
num_train_epochs | 整个数据集训练轮数,此处作为示例,仅跑1轮 | |
per_device_train_batch_size | 每张 GPU 每次处理的数据条数,此处为每卡batch=1 | |
per_device_eval_batch_size | 评估时每张 GPU 每次处理的数据条数,此处为每卡batch=1 | |
learning_rate | 学习率,控制每次参数更新的幅度,此处为1e-4,即0.0001 | |
lora_rank | LoRA 的秩,越大参数越多效果越好,显存也越多,此处作为示例仅为8 | 一般为8~64 |
lora_alpha | LoRA 缩放系数,此处为32,alpha/rank=4是常见比例 | 实际缩放比例 = lora_alpha/lora_rank |
target_modules | 对模型线性层添加LoRA | 支持以下参数: 1.所有线性层都加 LoRA(覆盖最全面):all-linear 2.所有 Embedding 层(新增专有词汇时使用):all-embedding 3.注意力层:q_proj, k_proj, v_proj, o_proj 4.MLP 层:gate_proj, up_proj, down_proj |
gradient_accumulation_steps | 累积n步更新一次参数,此处为累积16步才更新,等效batch=16 | batch_size等效于:gradient_accumulation_steps*per_device_train_batch_size |
eval_steps | 每 n 步做一次验证集评估,此处为每5步评估 | |
save_steps | 每 n 步保存一次checkpoint,此处为每50步保存 | |
save_total_limit | 最多保留 x 个 checkpoint,旧的自动删除(省磁盘),此处为只保留最新2个checkpoint | |
logging_steps | 每 n 步打印一次 loss 等训练指标,此处为每5步记录日志 | |
max_length | 每条数据最大 token 长度,超出截断(影响显存),此处最大序列长度为2048 | |
output_dir | 模型输出文件夹 | 注意:建议输出选择在共享存储挂载目录,以保存训练结果 |
system | 自动添加的系统提示词 | |
warmup_ratio | 前 n% 步数学习率从 0 线性预热到目标值,防止训练初期不稳定,此处为5%步数做warmup | |
dataloader_num_workers | 数据加载的并行进程数,加快数据读取,此处为数据加载时用4个子进程并行读取和预处理数据 | |
model_name | 模型名称 | |
model_author | 模型作者 | |
logging_dir | tensorboard保存位置 | 建议使用本示例$TENSORBOARD_OUTPUT_PATH位置,否则无法在首页使用tensorboard可视化界面! |
点击提交后,即可开始训练。
训练完成后,训练数据保存至output_dir参数目录下。
运行结果查看
1.可通过tensorboard查看训练效果
2.可使用开发机挂载共享存储,即可使用训练后模型
Tensorboard与Log日志查看
可在自定义任务列表中查看日志与tensorboard:

tensorboard数据:
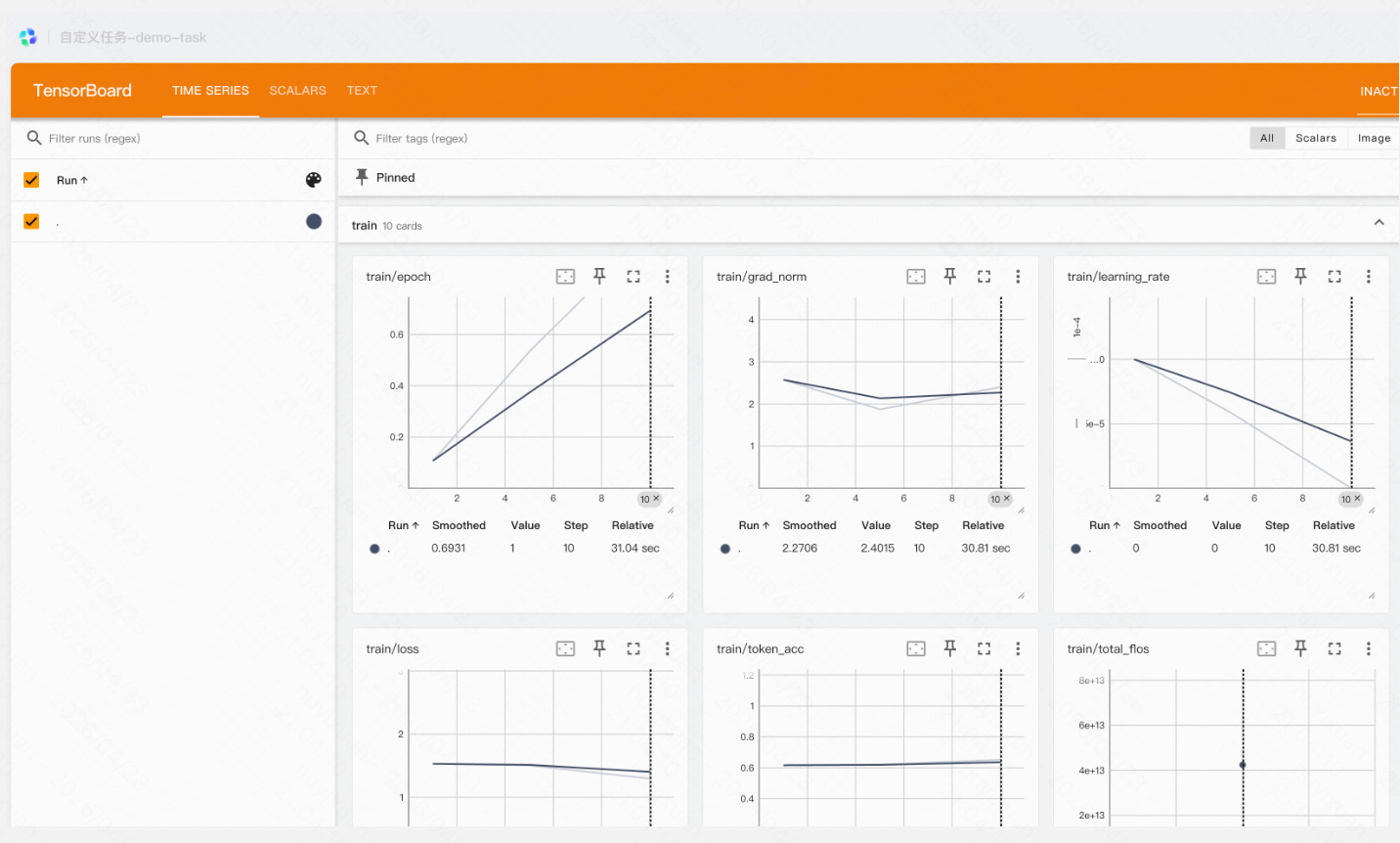
若tensorboard无数据:查看log日志检查是否进入training阶段,tensorboard文件在training阶段时产生。
log日志数据:
若log日志无数据:确保自定义任务状态为运行中
短信发送
自定义任务完成后平台会发送短信通知用户,点击后即可查看自定义任务结果。