性能评测能力支持用户对平台已经部署好的模型实例发起性能评估,测试模型服务在各种压力下的稳定性、效率和资源消耗,确保其可用、可靠、可扩展,最终生成压测报告,用户可基于报告指标调整部署方案。
创建性能评估任务
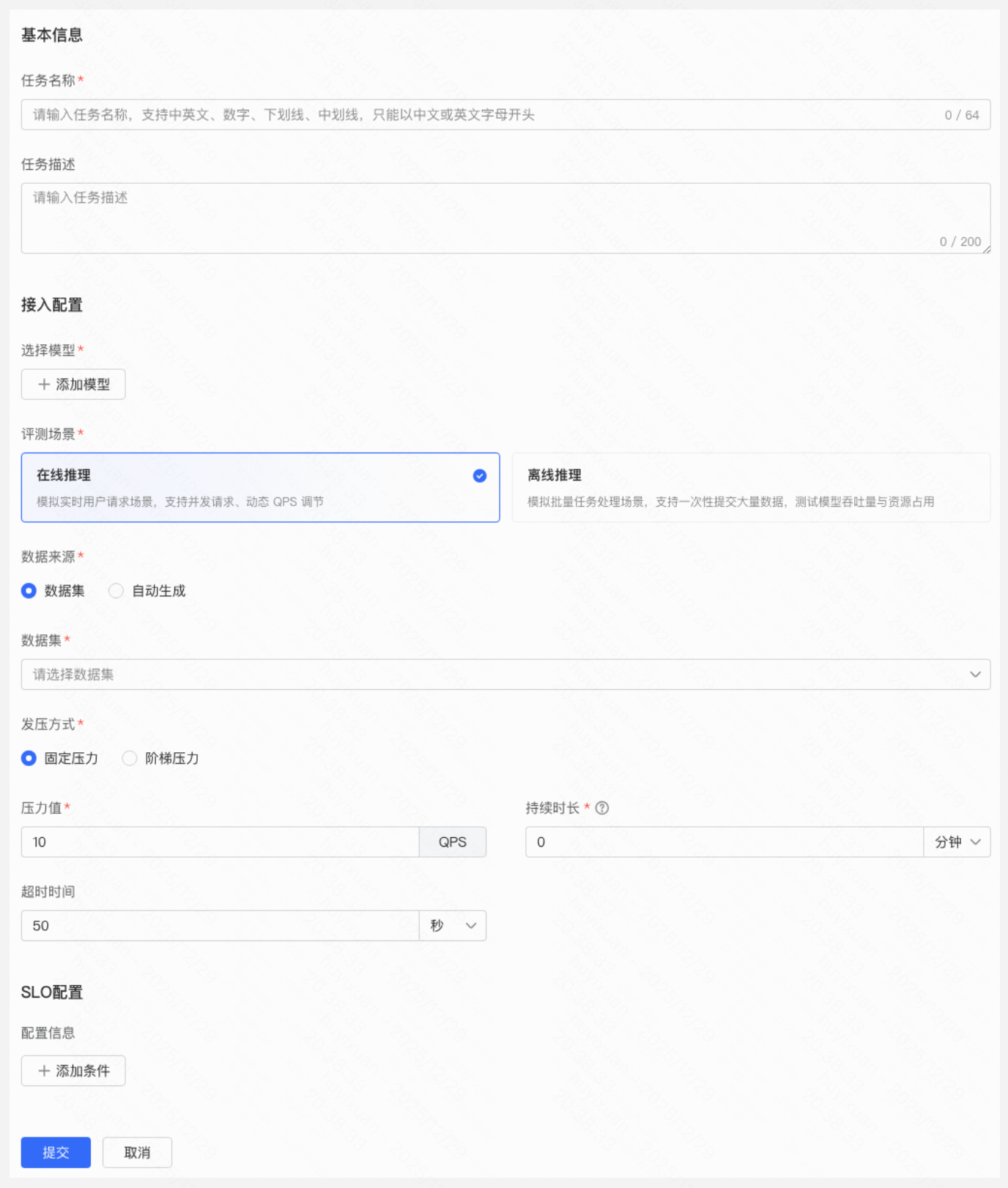
任务所需配置
配置项 | 说明 |
模型 | 当前暂不支持预置模型评测,仅可选择用户已部署的模型(含用户上传的模型) |
场景 | 支持 在线场景/离线场景 - 在线:模拟实时用户请求场景,支持并发请求、动态 QPS 调节(QPS受模型性能和并发影响,可能会低于设置的QPS)。
- 离线:模拟批量任务处理场景,支持一次性提交大量数据,测试模型吞吐量与资源占用。
|
数据来源 | 支持 评测集/自动生成 数据集:进入左侧导航栏->数据集->创建数据集(选择评测集,下载模版按格式) 自动生成: - 允许设置数据数量和输出token长度(尽量避免超长token,否则会影响模型的性能);
- 支持不同类型的分词器,一般选择和模型同名的分词器。
|
发压方式 | 离线推理: - 并发进程数:每个进程独立处理一部分推理任务,多个进程可以并行执行,充分利用系统资源。
- 持续时长:默认压测时长为0,即不限制最大压测时长,任务将在数据集请求完成后自动停止。若设置了压测时长,任务会按照指定时长持续运行,若在此期间数据集已请求完毕,则会循环重复请求。
- 超时时间: 单条请求的超时时间,超时后则改请求失败,影响最终的成功率。
在线推理: - 固定压力:以恒定压力请求模型。压力值为请求的QPS;持续时长、超时时间同上。
- 阶梯压力:以递增压力请求模型。初始压力为最低请求的QPS;峰值压力为最高请求QPS;每步增加为步长,即每一步增加的QPS;每步时长为每一步压测的持续时间,定义同上述持续时长。
|
SLO配置 | 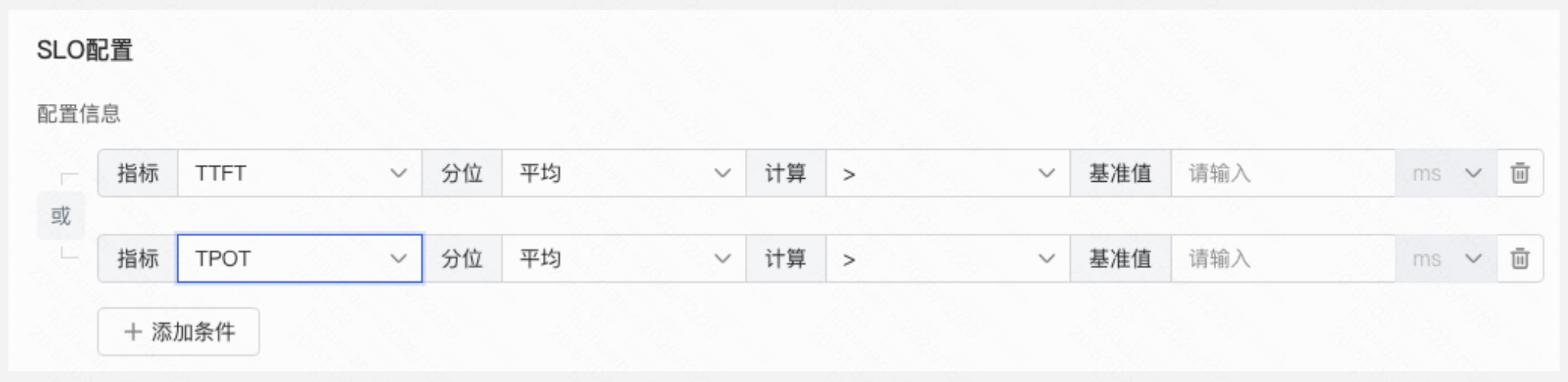
- TTFT相关:首token时延。表示从发送请求到收到第一个包的时间。一个包中包含1个或1个以上token。单位ms
- TPOT相关:由于一个包中包含1个或1个以上token,这里主要描述包间时延,表示返回包之间的时间间隔。单位ms
若配置了SLO, 当性能满足配置条件时,任务会退出并透露失败原因。 |
查看评测执行详情
评测结果
压测完成后会自动生成指标报告
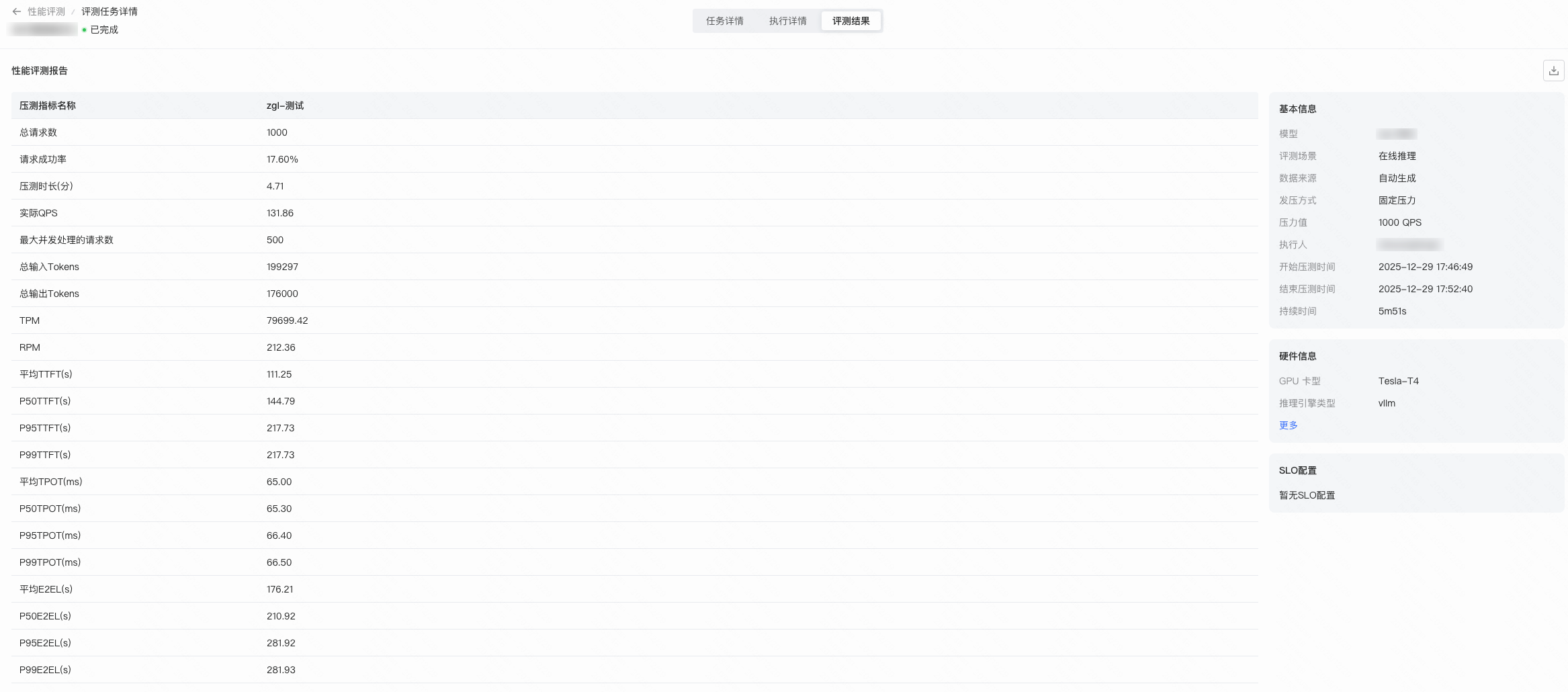
指标名 | 指标说明 |
TPM | Token Per Minute,每分钟总吞吐token(输入token+输出token) |
RPM | Requests Per Minute,每分钟可处理请求数 |
TTFT | - 平均TTFT:平均请求的首token时延
- P50 TTFT:50%请求的首token时延
- P90 TTFT:90%请求的首token时延
- P95 TTFT:95%请求的首token时延
- P99 TTFT:99%请求的首token时延
|
TPOT | - 平均TPOT:平均请求的token生成时间
- P50 TPOT:50%请求的token生成时间
- P90 TPOT:90%请求的token生成时间
- P95 TPOT:95%请求的token生成时间
- P99 TPOT:99%请求的token生成时间
|
E2EL | - 平均E2EL:请求平均端到端的全链路时延
- P50 E2EL:50%请求平均端到端的全链路时延
- P90 E2EL:90%请求平均端到端的全链路时延
- P95 E2EL:95%请求平均端到端的全链路时延
- P99 E2EL:99%请求平均端到端的全链路时延
|
