
数据工作流
数据工作流功能以可视化、流程化的方式,整合数据清洗、数据增强、数据抽取等核心数据处理环节,为用户提供一站式、标准化的数据加工解决方案,提高对评测、训练等数据集的处理效率。用户可通过拖拽配置、编排的方式搭建专属数据处理流程,无需繁琐手动编码,即可高效完成数据集的优化加工,输出符合模型训练、业务分析需求的高质量数据。
适用场景
- 大批量数据高效处理
以工作流形式串联清洗、增强、抽取环节,支持多步骤一次性配置、批量执行,避免单环节重复操作与数据流转损耗。流程可视化编排清晰直观,可快速调整步骤顺序、修改算子参数,大幅缩短数据处理周期。
- 低门槛流程构建
内置丰富算子,用户无需掌握复杂编程技能,通过拖拽选择、参数配置即可实现对应数据处理需求,兼顾专业研发人员与新手用户的使用场景,实现“零代码/低代码”数据加工。
- 个性化数据处理
支持根据数据集特性、后续使用场景(如模型训练、数据评测),灵活组合清洗、增强、抽取算子,自定义流程逻辑与参数配置。同时支持流程保存与复用,针对同类数据处理需求可直接调用历史流程,提升复用效率。
- 标准化数据输出
通过统一的工作流框架与算子规则,避免手动处理带来的操作偏差与数据质量波动。各环节处理结果可追溯,确保输出数据集的准确性,为模型训练效果提供保障。
核心节点能力说明
数据清洗
用于净化数据集,通过配置标准化清洗算子,对数据样本进行噪声去除、无效样本过滤、格式标准化等处理,精准解决数据中的冗余、异常等低质问题。用户可借助该节点快速获得高质量、无干扰的干净数据集,为后续的数据增强等环节打下基础。当前该节点共内置15个常用清洗算子,满足用户多样化数据处理需求。
数据增强
通过内置增强算子对清洗后的数据集进行样本扩充、特征强化,提升数据集的多样性与覆盖度,用户可通过该节点弥补样本数量不足、分布不均衡的短板。数据增强环节当前仅包含一个核心算子——泛化列数据,该算子专门对指定列数据进行泛化处理,增加训练数据的多样性和均衡性,进而提升模型泛化能力,减少模型训练过程中的过拟合风险,为后续模型训练提供更适配的样本数据。
数据抽取
聚焦数据的精准筛选与精简,支持用户按自定义规则划定数据抽取范围,实现数据集的按需精简。用户可通过该节点灵活调整数据的规模与维度,快速筛选出适配自身模型训练、数据分析等不同场景需求的数据,提升数据使用效率,避免冗余数据占用资源。
LLM
依托平台内置模型的智能化能力,实现数据样本的个性化加工。用户可通过自定义Prompt模板,灵活适配各类定制化数据处理需求,无需复杂操作即可完成智能化的数据加工,高效满足不同业务场景下的数据处理诉求。
创建数据工作流指引
本段落将指导用户在控制台搭建一个自定义数据工作流,以说明数据处理过程。该数据工作流的功能是对网页爬取的文本数据集进行处理,主要包括:
- 清洗:去除网页爬取带来的冗余信息,如URL、网页标签、编码混乱等;
- 大模型处理(LLM节点):提取每条文本的核心关键词用于辅助模型训练;
- 增强:对文本内容列进行泛化,提升样本多样性;
- 抽取:保留核心列,最终输出适配训练的精简数据集。
步骤:
1.登录万擎平台,在左侧导航栏中「数据管理」下方点击「数据工作流」进入产品页面。点击「+新建数据工作流」进入创建页面,在开始节点新增列表头变量。列表头变量指数据集某个版本的该列所有数据。执行时节点之间将对整个数据表进行传递。
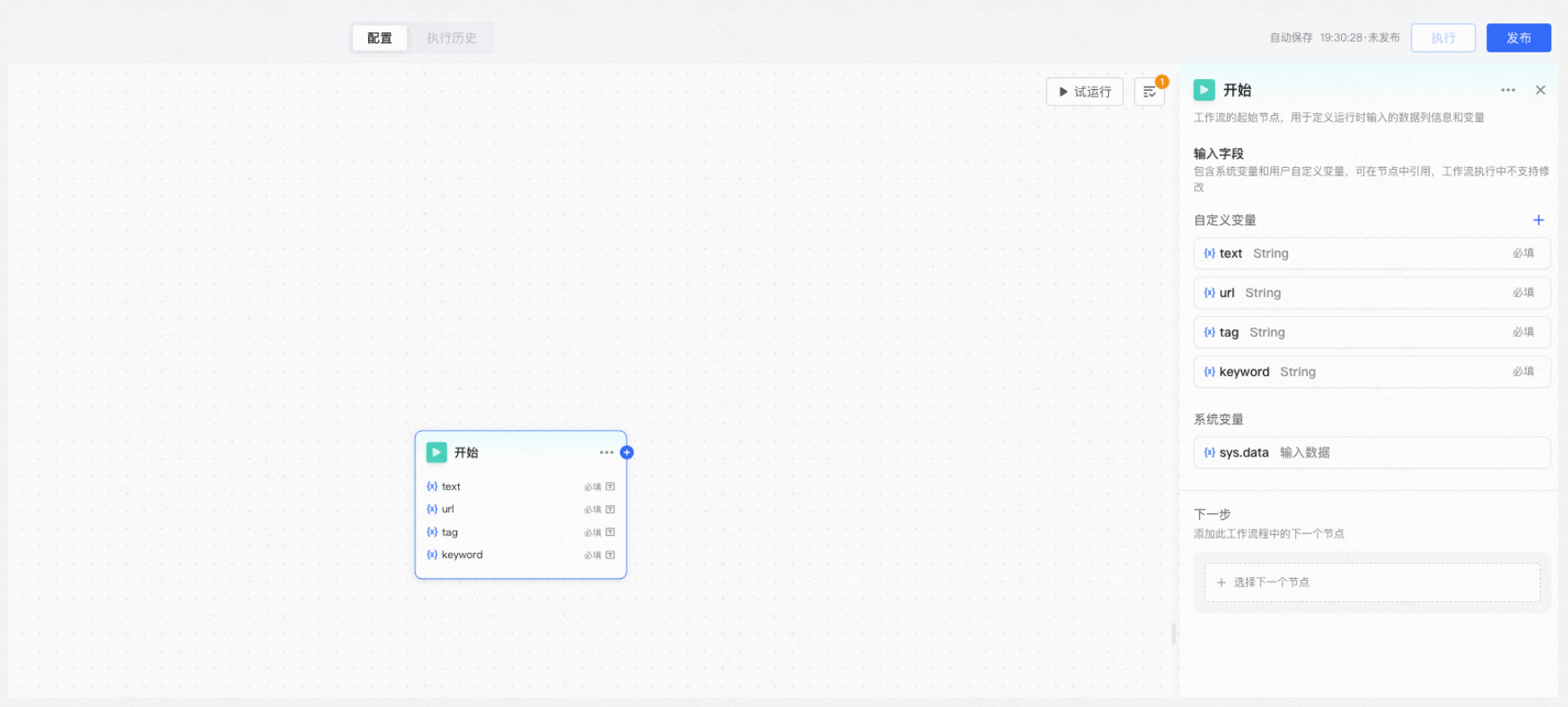
2.新增数据清洗节点,根据需要选择移除URL链接、去除网页标识符、过滤特殊字符、Unicode 文本标准化四个清洗算子,通过列表头变量配置清洗的数据样本列范围。
平台当前共包含15清洗算子,在该节点中支持用户多选算子并调整执行顺序,算子可自定义参数(如过滤特殊字符的比例、长度过滤长度范围选择等),执行后可实时预览处理效果:
算子名称 | 算子类型 | 算子配置 | 描述 | 效果(清洗前) | 效果(清洗后) |
过滤特殊字符 | 异常清洗 | 调整比例最大值 范围:[0.00,1.00] | 根据特殊字符占比移除数据。仅保留特殊字符个数占文本总长度比例不高于阈值的样本。特殊字符包括标点符号,数字,空格符号,emoji表情包等,超过设定比例的数据样本将被过滤。 | ‿∞➤~πه۩☛₨➩☻๑٪♥ıॽ | -- |
移除 URL 链接 | 异常清洗 | - | 根据配置移除指定字符,例如文本中的url等。 | 主动适应形势新变化提高政法机关服务大局的能力ftp://user:password@ftp.example.com:21 | 主动适应形势新变化提高政法机关服务大局的能力 |
去除网页标识符 | 异常清洗 | - | 根据配置移除指定字符,例如文本中的html格式字符等。 | 诉讼未终结涉案财物不得上缴国库<div class='article-content'><div> | 诉讼未终结涉案财物不得上缴国库 |
移除不可见字符 | 异常清洗 | - | 根据配置移除指定字符,例如文本中的不可见字符等。 | 文本中包含零宽字符 | 文本中包含零宽字符 |
过滤非语言文本 | 异常清洗 | 文本语言概率 范围:[0.00, 1.00] | 检查文本属于中文语言规范的概率。设置阈值后,低于阈值的数据样本将被过滤。 | a=1bc=1+2+3+5d=6 | -- |
过滤困惑文本 | 异常清洗 | 文本困惑度范围:[1,5000] | 检查文本困惑度。设置阈值后,高于阈值的数据样本将被过滤 | a v s e c s f e f g a qkc | -- |
文章相似度去重 | 分布清洗 | 分词单元选择:空格或字符范围: 窗口长度:[2,5]汉明距离:[4,6] | 使用SimHash算法计算文本间的相似度,相似度超过阈值的数据样本将被过滤。 | StreamLake数据分析与处理是基于快手自研技术提供的企业专属大模型数据处理和分析工具链。SteamLake数据分析与处理是基于快手自研技术提供的企业专属大模型数据处理和分析工具链。 | StreamLake数据分析与处理是基于快手自研技术提供的企业专属大模型数据处理和分析工具链。 |
长度过滤 | 分布清洗 | 长度最小值 范围:[1,10000]长度最大值 范围:[1,10000] | 根据文本长度过滤数据。超过配置范围的数据样本将被过滤。 | 你是一个专业的新闻摘要撰写助手,擅长使用简洁明了的语言来提炼核心信息 | -- |
字重复率过滤 | 分布清洗 | 字重复概率概率:[0.00,1.00] | 根据文本重复率过滤数据。超过配置范围的数据样本将被过滤。 | 你是是是是是是是是是是是是是是是是是是是是是是是是是是是是是是一个专业的新闻摘要撰写助手 | -- |
N-Gram 重复率过滤 | 分布清洗 | 长度范围:[2,5]比率最大值范围:[0.00, 1.00] | 根据N-Gram重复率过滤数据。超过配置范围的数据样本将被过滤。 | 如何缴费缴费缴费缴费缴费缴费缴费缴费缴费缴费缴费缴费缴费缴费缴费缴费缴费缴费缴费缴费、怎么扣缴、如何变更档次、怎么查询信息等流程,你都造吗 | -- |
MD5 去重 | 分布清洗 | - | 根据文本生成的MD5值对比去重,MD5校验一致的数据样本将被过滤。 | 你是一个专业的新闻摘要撰写助手,擅长使用简洁明了的语言来提炼核心信息你是一个专业的新闻摘要撰写助手,擅长使用简洁明了的语言来提炼核心信息 | 你是一个专业的新闻摘要撰写助手,擅长使用简洁明了的语言来提炼核心信息 |
繁体转简体 | 格式清洗 | - | 将文本内的中文繁体转换为中文简体。 | 你是一個專業的新聞摘要撰寫助手,擅長使用簡潔明瞭的語言來提煉核心信息 | 你是一个专业的新闻摘要撰写助手,擅长使用简洁明了的语言来提炼核心信息 |
Unicode 文本标准化 | 格式清洗 | - | 可对文本进行Unicode标准化处理。 | 文本包含é́异常编码 | 文本包含é异常编码 |
去除 Email 地址 | 安全清洗 | - | 去除文本中包含的Email地址。 | 擅长使用简洁明了的语言来提炼核心信息1234567@gmail.com | 擅长使用简洁明了的语言来提炼核心信息KWAI_EMAIL |
去除 IP 地址 | 安全清洗 | - | 去除IPv4或者IPv6地址。 | 这个随机安排的小学生聚会,12.12.12.12俨然成了“吐槽大会” | 这个随机安排的小学生聚会,KWAI_IP俨然成了“吐槽大会” |
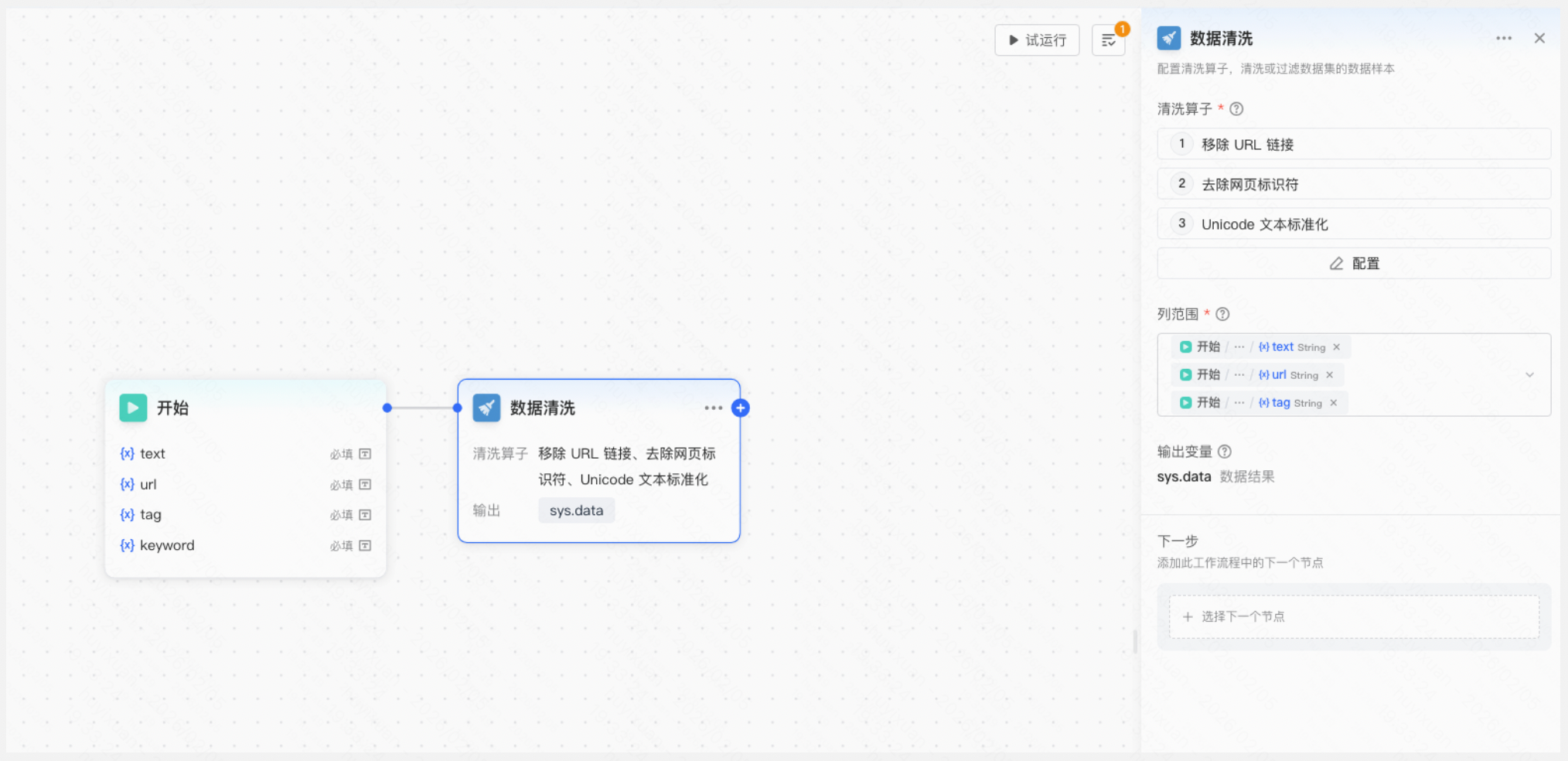
3.新增LLM大模型节点,选择推理点,输入Prompt,让大模型提取每条文本的核心关键词并输出至指定列。
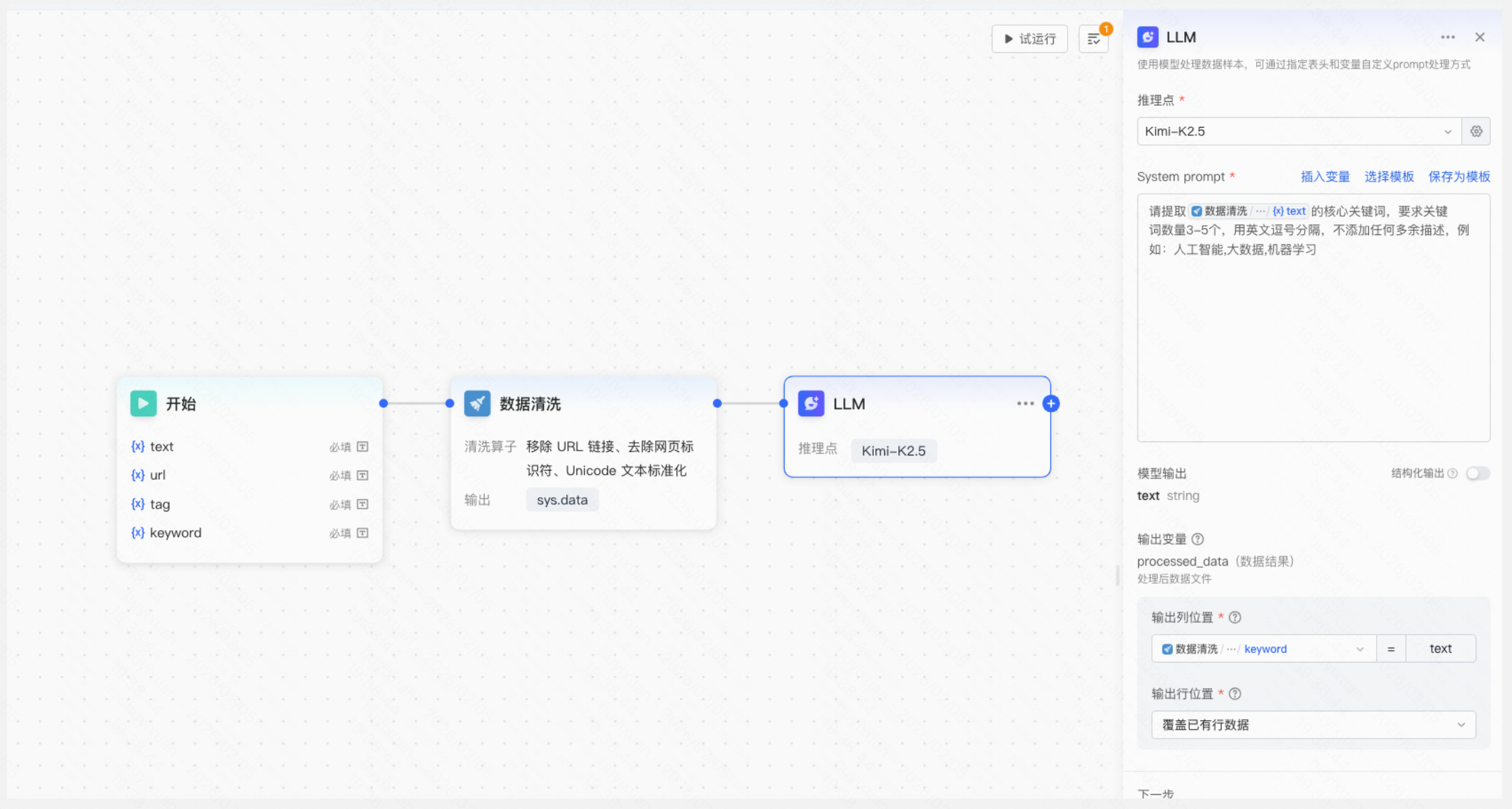
配置内容:
- 推理点:用户可选择平台预置推理点或自定义推理点。
- 模型Prompt配置:输入可插入的变量包括当前数据集所有表头、列表头变量、前序节点定义/输出变量。列表头变量引用后将会对整个数据表的某列做相同计算处理。用户可选择过往保存的Prompt模板直接使用,也可将当前内容保存至Prompt模板。
- 输出变量:用户可指定模型输出所在数据表的行列位置。
- 结构化输出:支持可视化配置和JSON导入。
4.新增数据增强节点,选择推理点,可使用平台提供的默认系统提示词模板或自定义提示词,通过模型生成增强样本并输出至指定行列位置。
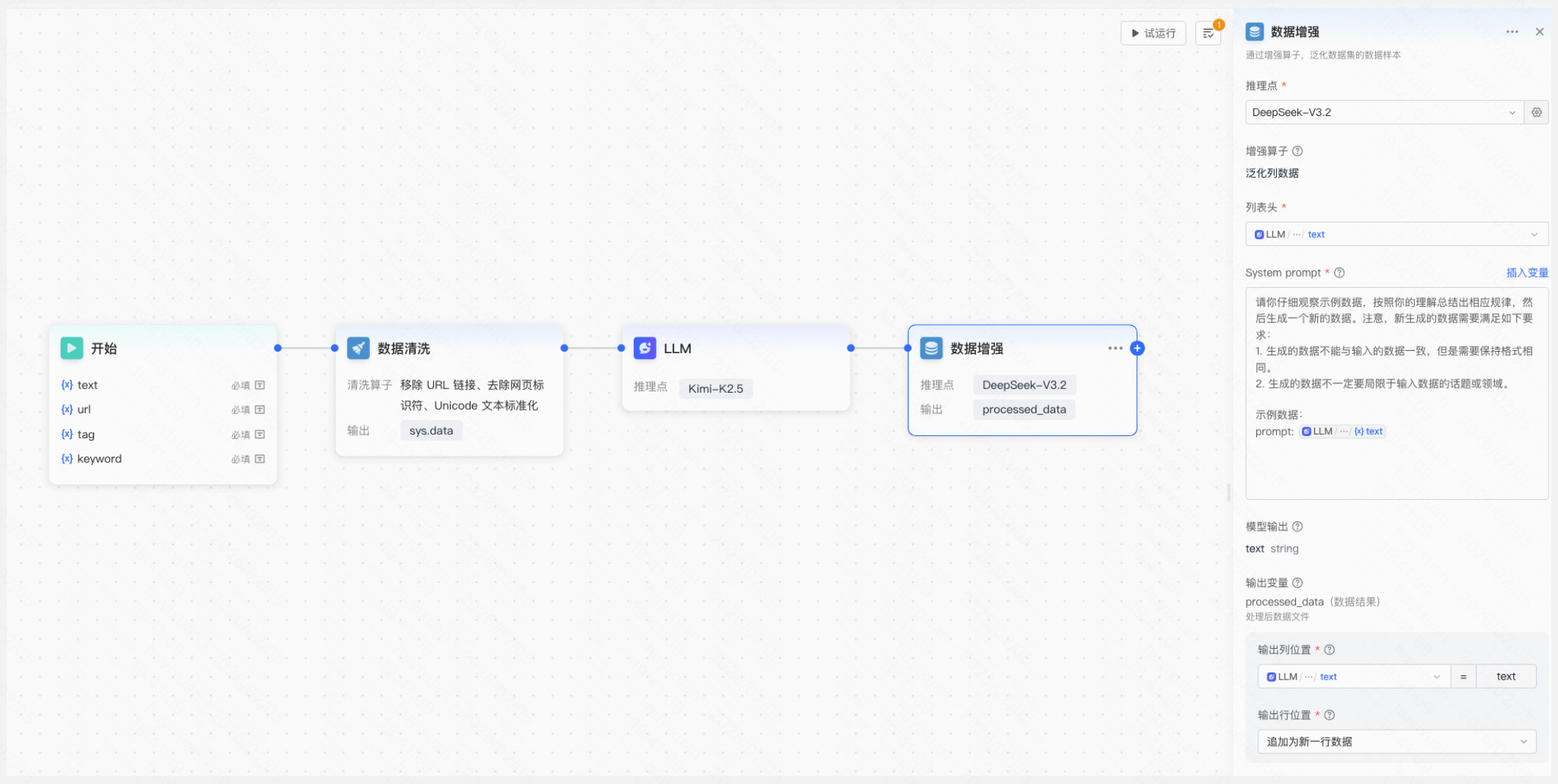
配置内容:
- 推理点:用户可选择平台预置推理点或自定义推理点。
- 列表头:选择需要泛化增强的列表头变量。
- 系统提示词:可使用平台提供的默认系统提示词模板或自定义提示词。
- 输出变量:用户可指定模型输出所在的行列位置,若选择追加新一行,将包含原样本行数据的其他列数据。
5.新增数据抽取节点,数据抽取支持按行/列抽取,用户可根据需要选择合适的抽取方式,并通过列表头变量配置抽取的数据样本列范围。
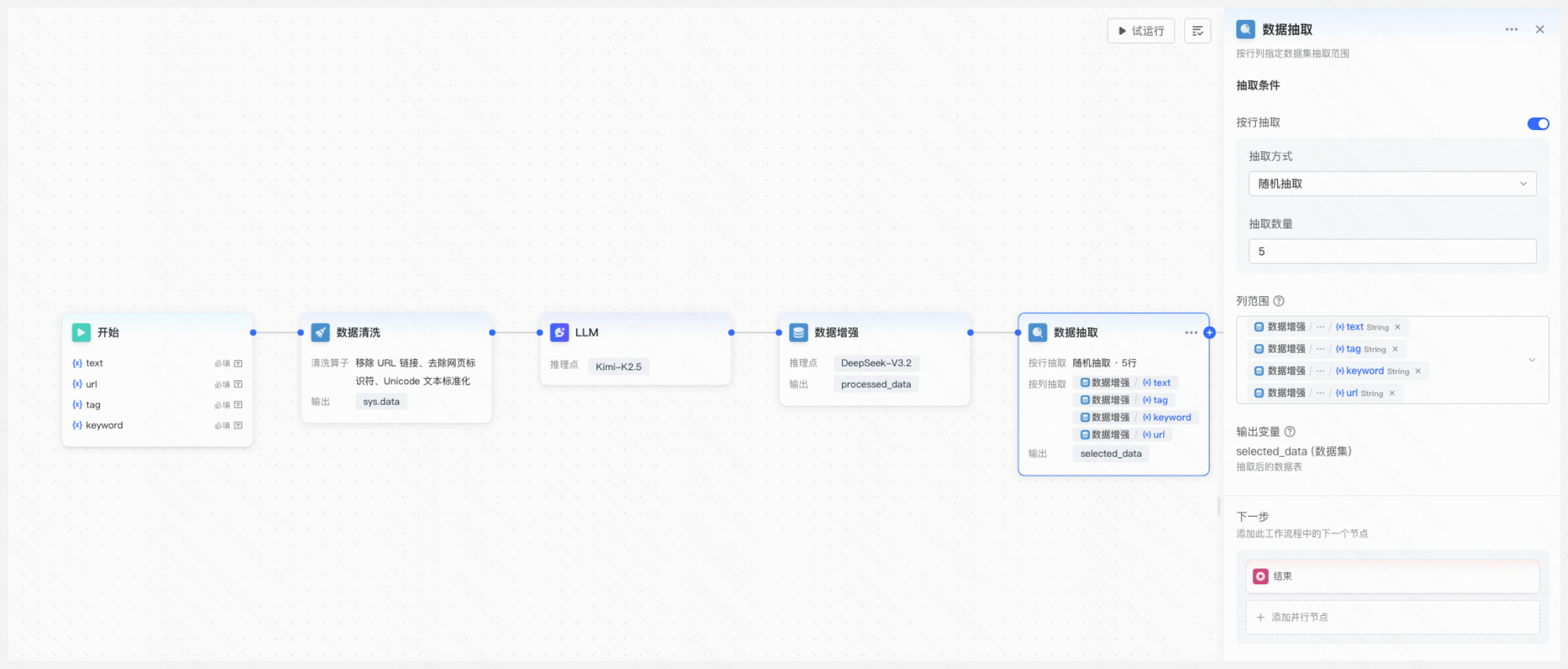
配置内容:
- 按行抽取:抽取方式包括顺序抽取和随机抽取两种。
- 顺序抽取:用户可自定义抽取的起始行和结束行,起始行最小值为2;
- 随机抽取:用户可自定义抽取的数量,最小值为2。
- 按列抽取:通过列表头变量,配置抽取的数据样本列范围。
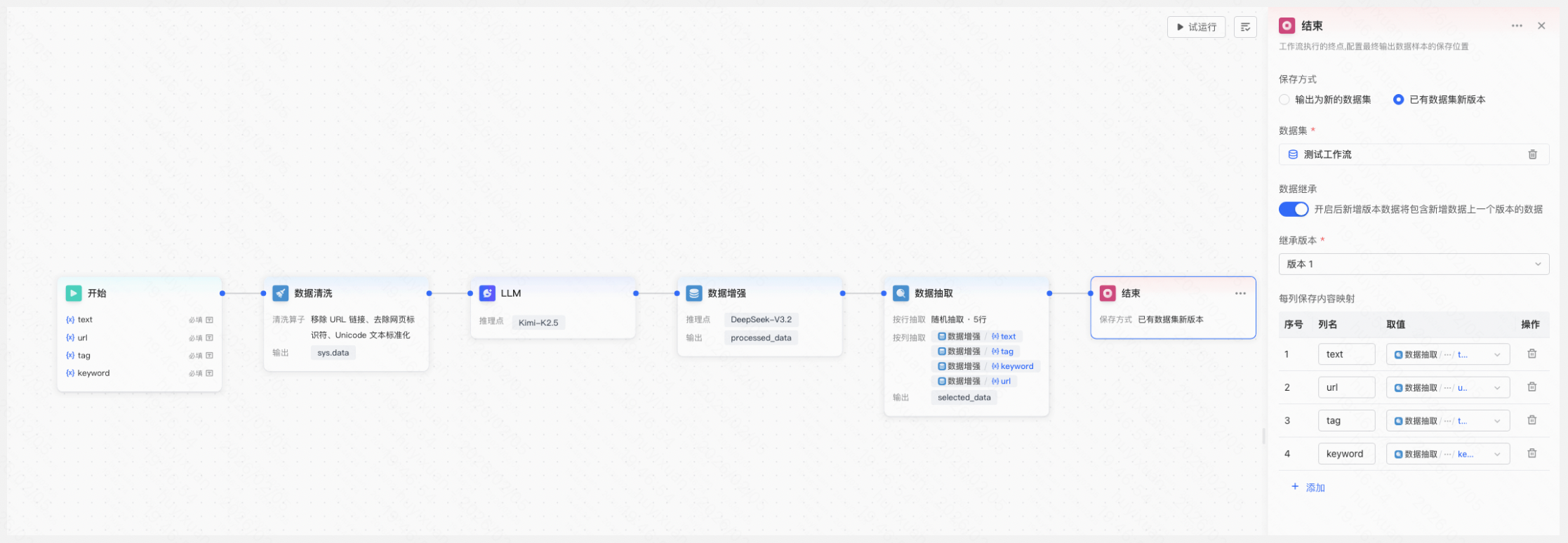
6.新增结束节点,用户可自定义输出数据样本的保存方式及内容,平台支持输出为新数据集及保存至已有数据集新版本两种方式。列映射是指将工作流中处理的变量数据保存至数据集中的具体某列。
执行数据工作流
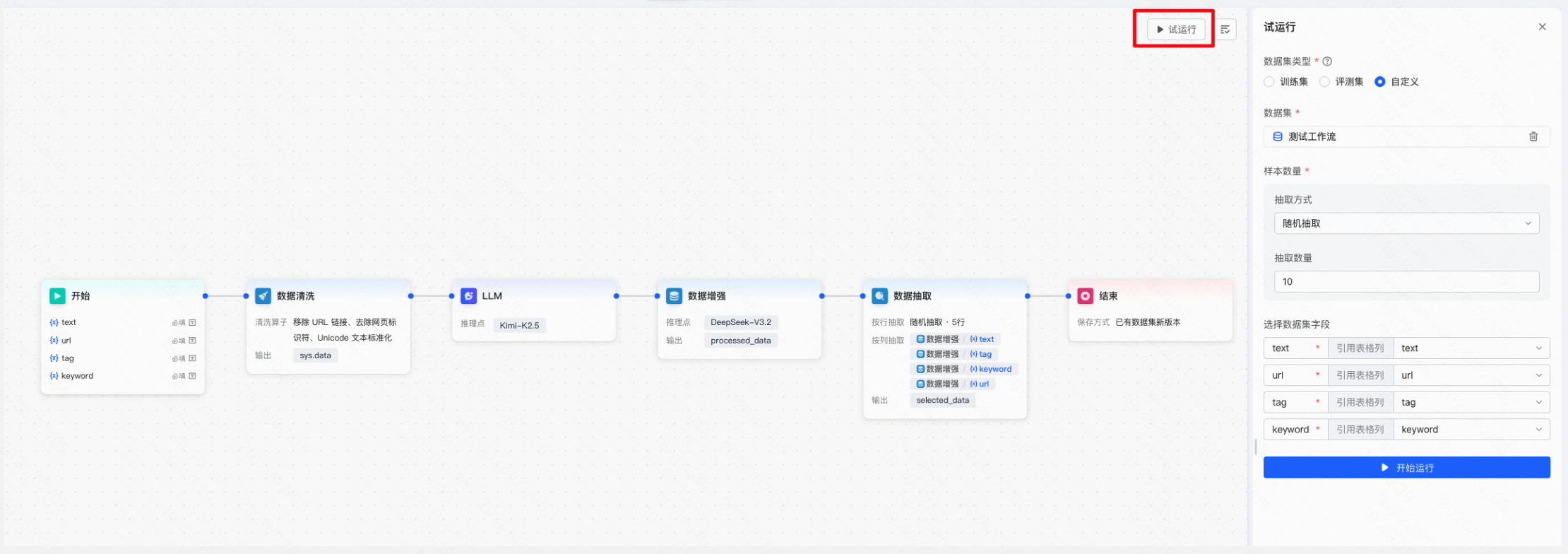
用户可在画布内试运行工作流,试运行最多仅支持抽取10行样本。试运行中会引入开始节点中用户输入的变量,用户需将开始节点的变量与试运行选择的数据集表格列一一映射。
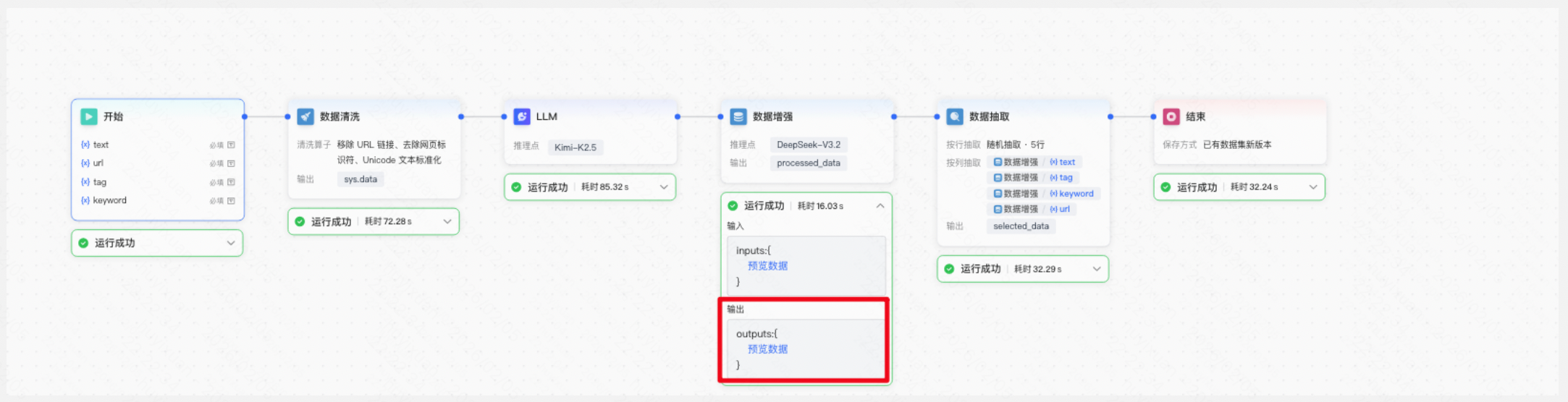
发布成功后,可执行该数据工作流,执行过程支持实时查看。任务完成后,系统将根据用户选择的保存方式生成新数据样本,请您在使用时注意区分。

执行成功节点数据支持预览,预览数据支持以jsonl格式导出。
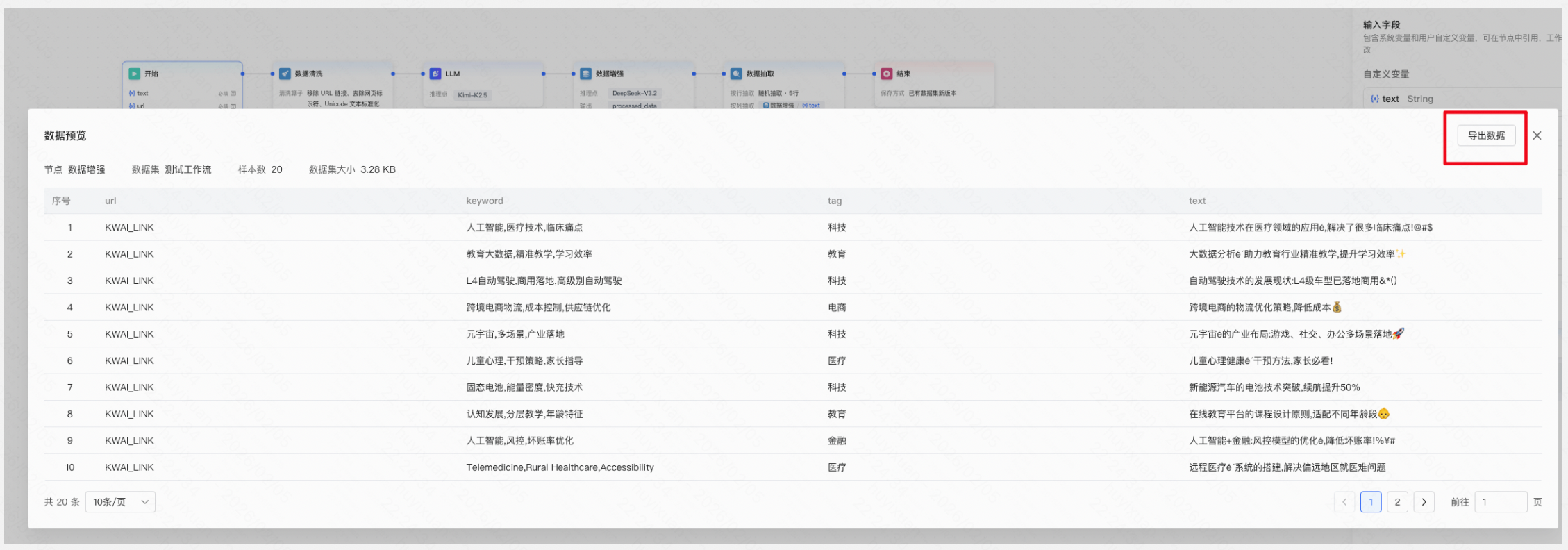
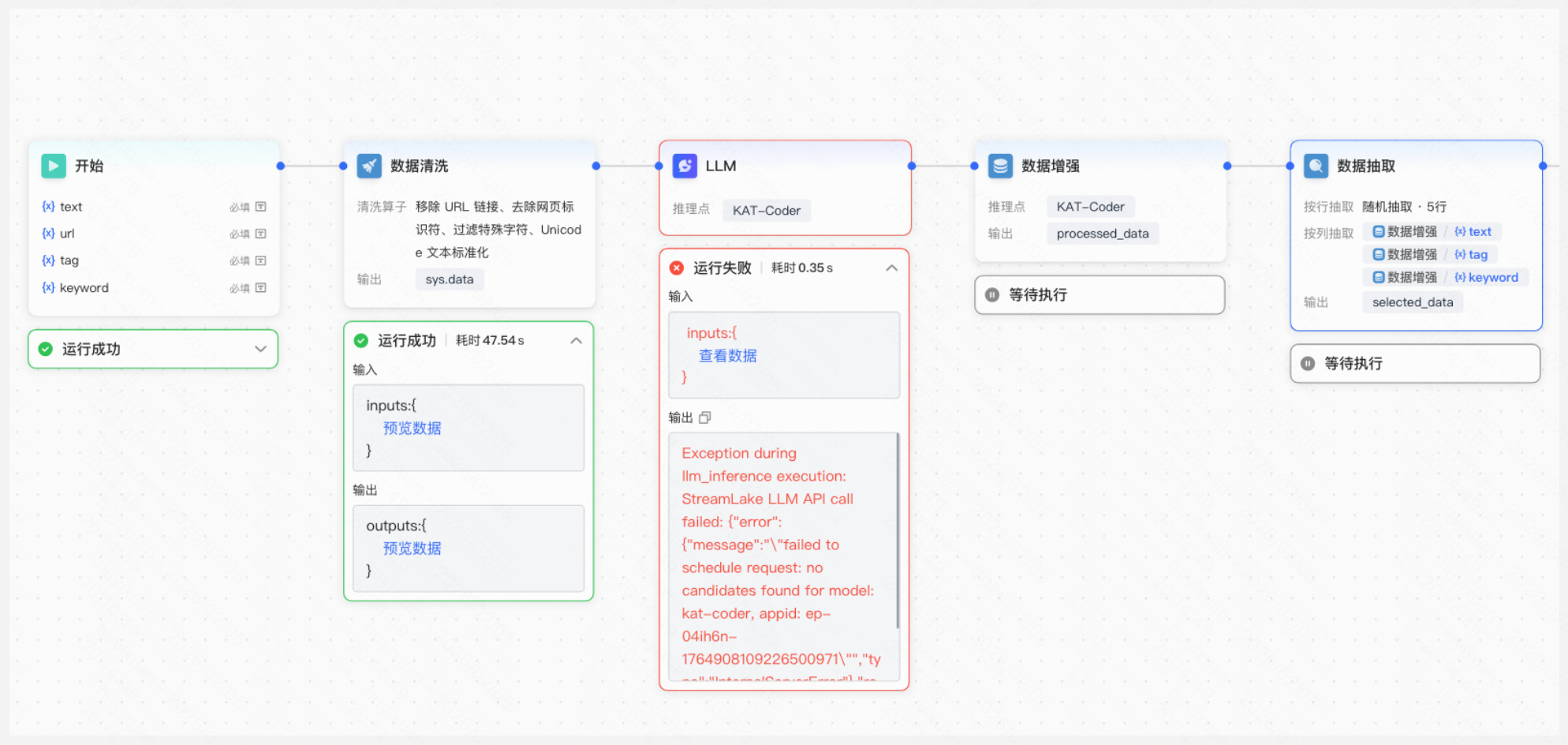
若执行失败,可点击「执行详情」,平台为用户提供失败的详细原因,您可据此对数据工作流进行调整。
管理数据工作流
当项目下存在数据工作流时,用户可在该页面查看项目下完整的数据工作流任务列表及基本信息,包括执行次数、最近执行任务等,已发布的工作流支持执行。

- 查看全部历史记录:在数据工作流页面右侧点击「执行历史」,可查看该项目下所有工作流的历史记录,包括执行时长、状态、各阶段执行状况等。

- 查看某个工作流历史记录:
- 入口一:列表页点击某个工作流的总执行次数可查看该工作流的所有历史任务情况;
- 入口二:进入某个工作流,在画布上方切换为「执行历史」。
