
开发机 ms-swift 最佳实践
一、开发机使用教程
1.1 创建开发机
- 点击 模型研发 → 开发机 → 新建开发机
- 在「预制镜像」处选择 ms-swift
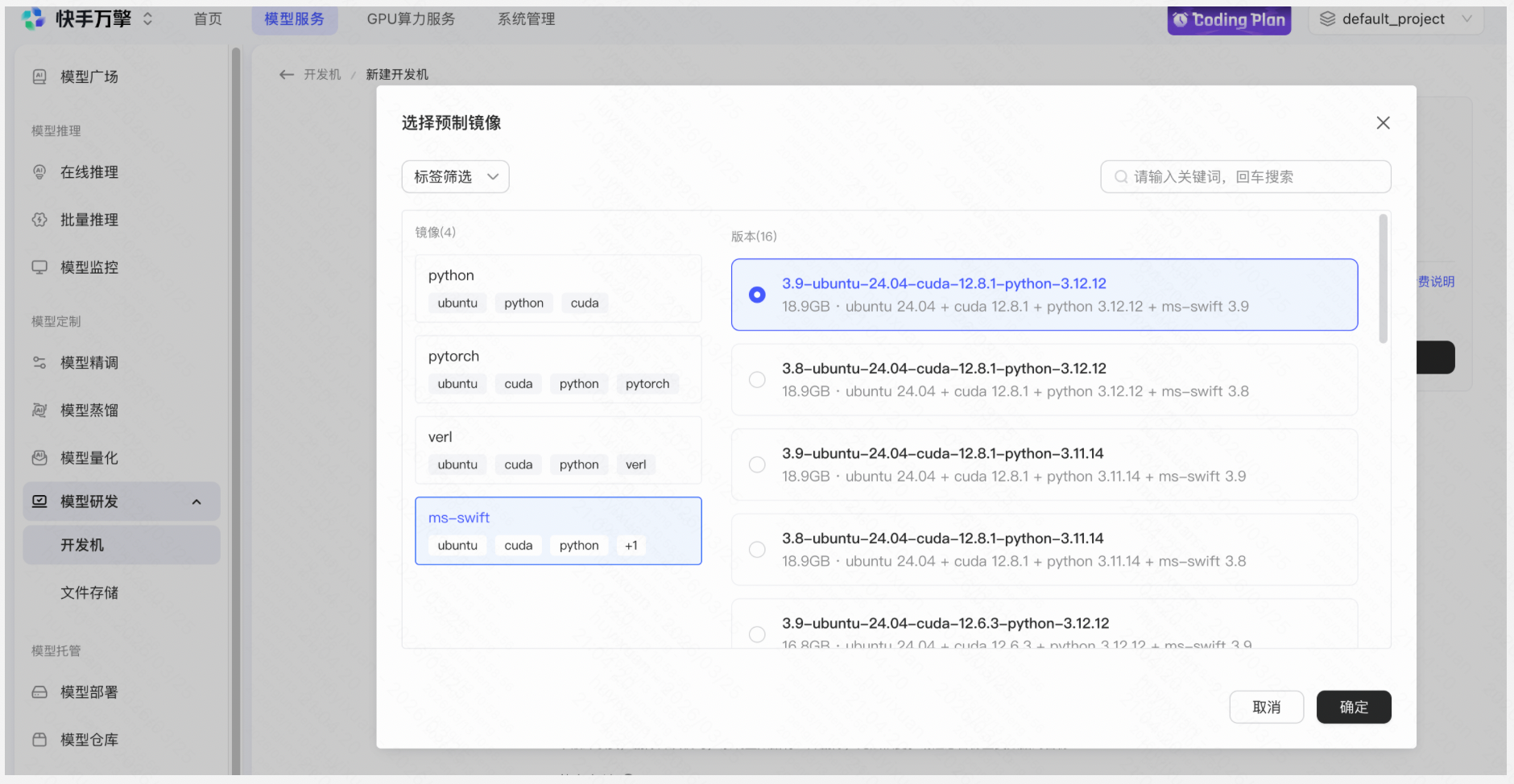
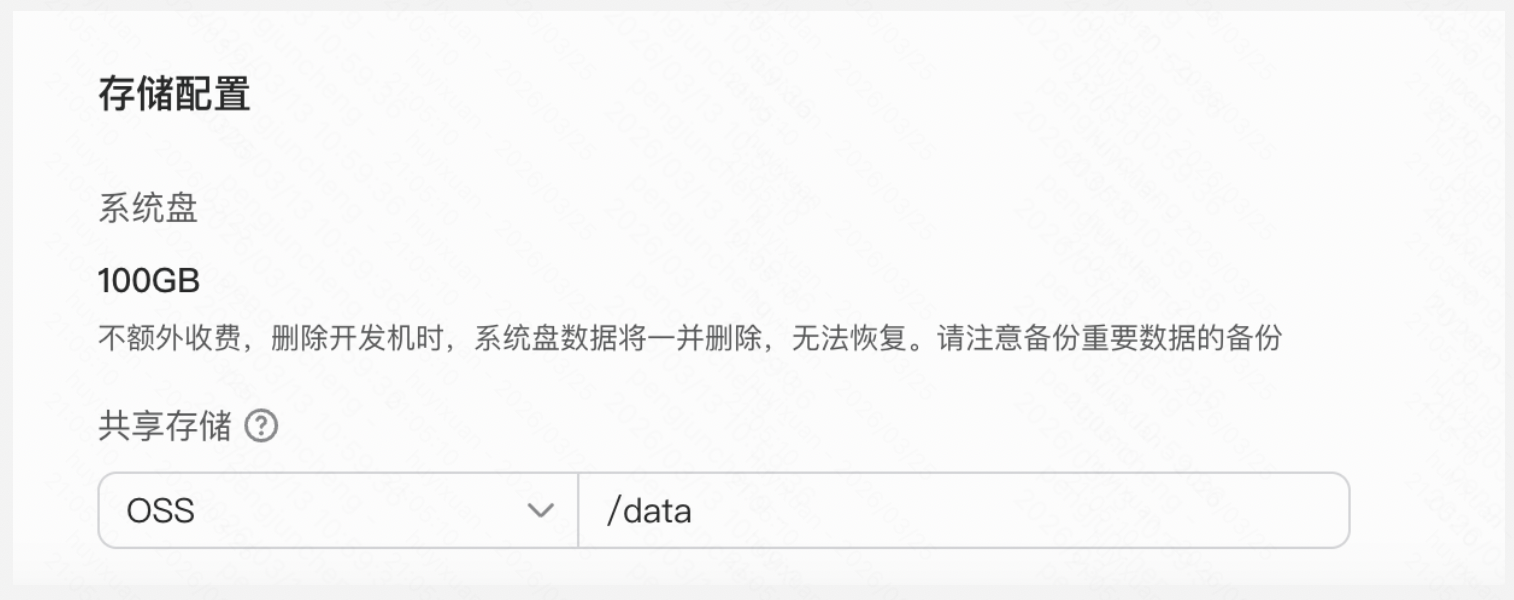
- 重要:建议选择共享存储,否则开发机关机后数据不会保留!
存储配置如图所示,该存储会挂载到开发机的 /data 目录下:
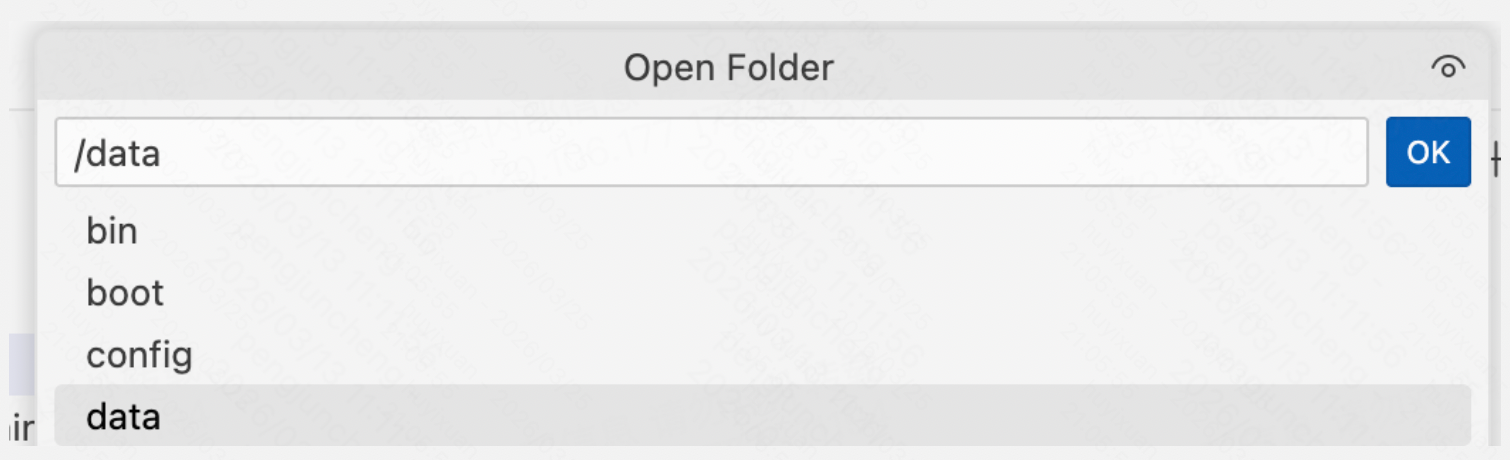
1.2 配置 VS Code
- 打开 VS Code,点击左上角切换工作目录: File → Open Folder
- 选择创建开发机时的共享存储路径(通常是
/data路径)
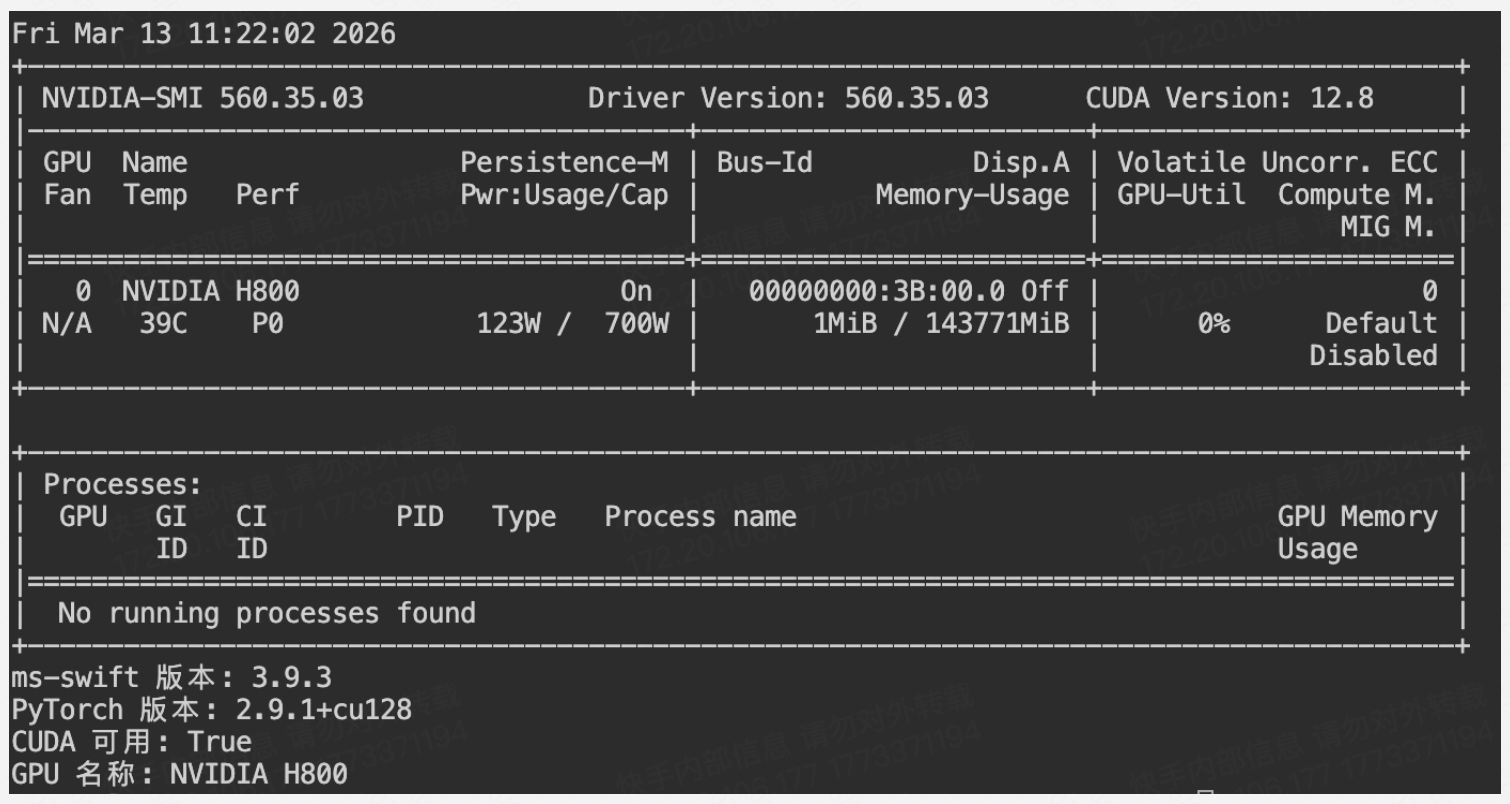
二、ms-swift 框架使用
2.1 检查环境
# 检查 GPU 状态
nvidia-smi
# 检查 Python3 和 torch
python3 -c "
import torch
import swift
print('ms-swift 版本:', swift.__version__)
print('PyTorch 版本:', torch.__version__)
print('CUDA 可用:', torch.cuda.is_available())
print('GPU 名称:', torch.cuda.get_device_name(0) if torch.cuda.is_available() else '无')
"
2.2 场景选择
ms-swift 支持多种类型的微调任务,您可根据任务目标进行选择(本文教程均为 SFT 微调方式)
你的目标 | 对应微调类型 |
做一个聊天机器人 / 问答系统 / 角色扮演 | 文本对话模型 |
让模型看懂图片、做 VQA 图片问答 | 视觉语言模型 (VLM) |
做文本分类、情感分析、意图识别 | 序列分类 |
做语义搜索、相似文本匹配、向量检索 | 文本嵌入(Embedding) |
优化搜索结果排序、提升 RAG 效果 | 重排序(Reranker) |
2.3 步骤指引
2.3.1 文本对话模型(因果语言)
训练
- 第一步:下载训练数据
本示例共有3个jsonl微调文件,下载代码如下:
# 在云端运行:python3 /workspace/exportDataset.py
import json
import os
os.makedirs('/workspace/train_data', exist_ok=True)
# 下载 AI-ModelScope/alpaca-gpt4-data-zh
print("正在下载 alpaca-gpt4-data-zh (中文 Alpaca)...")
from modelscope.msdatasets import MsDataset
ds_zh = MsDataset.load('AI-ModelScope/alpaca-gpt4-data-zh', split='train')
out_path = '/data/pengc/train_data/alpaca_zh.jsonl'
count = 0
with open(out_path, 'w', encoding='utf-8') as f:
for i, row in enumerate(ds_zh):
if i >= 500:
break
row = dict(row)
instruction = row.get('instruction') or ''
input_text = row.get('input') or '' # ← 修复:None 转为空字符串
if input_text.startswith('输入:'):
input_text = input_text[3:]
query = (instruction + '\n' + input_text).strip() if input_text else instruction.strip()
item = {
"messages": [
{"role": "user", "content": query},
{"role": "assistant", "content": row.get('output') or ''}
]
}
f.write(json.dumps(item, ensure_ascii=False) + '\n')
count += 1
print(f"已保存 {count} 条到 {out_path}")
# 下载 AI-ModelScope/alpaca-gpt4-data-en
print("正在下载 alpaca-gpt4-data-en (英文 Alpaca)...")
ds_en = MsDataset.load('AI-ModelScope/alpaca-gpt4-data-en', split='train')
out_path = '/data/pengc/train_data/alpaca_en.jsonl'
count = 0
with open(out_path, 'w', encoding='utf-8') as f:
for i, row in enumerate(ds_en):
if i >= 500:
break
row = dict(row)
instruction = row.get('instruction') or ''
input_text = row.get('input') or '' # ← 修复:None 转为空字符串
query = (instruction + '\n' + input_text).strip() if input_text else instruction.strip()
item = {
"messages": [
{"role": "user", "content": query},
{"role": "assistant", "content": row.get('output') or ''}
]
}
f.write(json.dumps(item, ensure_ascii=False) + '\n')
count += 1
print(f"已保存 {count} 条到 {out_path}")
# 下载 swift/self-cognition(自我认知)
print("正在下载 swift/self-cognition (自我认知)...")
ds_sc = MsDataset.load('swift/self-cognition', split='train')
out_path = '/data/pengc/train_data/self_cognition.jsonl'
count = 0
MODEL_NAME_ZH = '千问'
MODEL_NAME_EN = 'Qwen'
MODEL_AUTHOR_ZH = '万擎'
MODEL_AUTHOR_EN = 'WangQing'
with open(out_path, 'w', encoding='utf-8') as f:
for i, row in enumerate(ds_sc):
if i >= 500:
break
row = dict(row)
tag = row.get('tag') or 'zh'
query = row.get('query') or ''
response = row.get('response') or ''
name = MODEL_NAME_ZH if tag == 'zh' else MODEL_NAME_EN
author = MODEL_AUTHOR_ZH if tag == 'zh' else MODEL_AUTHOR_EN
query = query.replace('{{NAME}}', name).replace('{{AUTHOR}}', author)
response = response.replace('{{NAME}}', name).replace('{{AUTHOR}}', author)
item = {
"messages": [
{"role": "user", "content": query},
{"role": "assistant", "content": response}
]
}
f.write(json.dumps(item, ensure_ascii=False) + '\n')
count += 1
print(f"已保存 {count} 条到 {out_path}")
# 汇总
print("全部下载完成!文件列表:")
for fname in os.listdir('/data/pengc/train_data'):
fpath = f'/data/pengc/train_data/{fname}'
lines = sum(1 for _ in open(fpath, encoding='utf-8'))
size_kb = os.path.getsize(fpath) / 1024
print(f" {fpath} ({lines} 条, {size_kb:.1f} KB)")
数据格式示例:
{
"messages": [
{
"role": "user",
"content": "Give three tips for staying healthy."
},
{
"role": "assistant",
"content": "1. Eat a balanced and nutritious diet: Make sure your meals are inclusive of a variety of fruits and vegetables, lean protein, whole grains, and healthy fats. This helps to provide your body with the essential nutrients to function at its best and can help prevent chronic diseases.\n\n2. Engage in regular physical activity: Exercise is crucial for maintaining strong bones, muscles, and cardiovascular health. Aim for at least 150 minutes of moderate aerobic exercise or 75 minutes of vigorous exercise each week.\n\n3. Get enough sleep: Getting enough quality sleep is crucial for physical and mental well-being. It helps to regulate mood, improve cognitive function, and supports healthy growth and immune function. Aim for 7-9 hours of sleep each night."
}
]
}
- 第二步:运行命令,启动训练
swift sft \
--model Qwen/Qwen2.5-7B-Instruct \
--train_type lora \
--dataset /data/fine-tuning/train_data/alpaca_zh.jsonl \
/data/fine-tuning/train_data/alpaca_en.jsonl \
/data/fine-tuning/train_data/self_cognition.jsonl \
--torch_dtype bfloat16 \
--num_train_epochs 3 \
--per_device_train_batch_size 1 \
--per_device_eval_batch_size 1 \
--learning_rate 1e-4 \
--lora_rank 8 \
--lora_alpha 32 \
--target_modules all-linear \
--gradient_accumulation_steps 16 \
--eval_steps 50 \
--save_steps 50 \
--save_total_limit 2 \
--logging_steps 5 \
--max_length 2048 \
--output_dir /data/fine-tuning/output/qwen2.5-7b-sft \
--system 'You are a helpful assistant.' \
--warmup_ratio 0.05 \
--dataloader_num_workers 4 \
--model_name Qwen \
--model_author Alibaba
参数详解:
参数 | 含义 |
model | 基座模型,从 ModelScope 自动下载,支持的模型列表:支持的模型 |
train_type | 训练方式。可使用下述代码查看支持的训练方式: python3 -c "from swift.llm.argument.base_args.base_args import get_supported_tuners; print(sorted(get_supported_tuners()))" |
dataset | 数据集路径,可使用在线数据集路径,支持的数据集:支持的数据集,在线例如: --dataset 'AI-ModelScope/alpaca-gpt4-data-zh#500' \ |
torch_dtype | 数据类型。支持:bfloat16 ,float16,float32,None(默认,框架自动判断) |
num_train_epochs | 整个数据集训练轮数 |
per_device_train_batch_size | 每张 GPU 每次处理的数据条数 |
per_device_eval_batch_size | 评估时每张 GPU 每次处理的数据条数。即评估时的 batch_size |
learning_rate | 学习率 |
lora_rank | LoRA 的秩,越大参数越多效果越好,显存也越多。一般为8~64 |
lora_alpha | LoRA 缩放系数,实际缩放比例 = lora_alpha/lora_rank |
target_modules | 对模型线性层添加LoRA,支持以下参数: 1.所有线性层都加 LoRA(覆盖最全面):all-linear 2.所有 Embedding 层(新增专有词汇时使用):all-embedding 3.注意力层:q_proj, k_proj, v_proj, o_proj 4.MLP 层:gate_proj, up_proj, down_proj |
gradient_accumulation_steps | 累积n步更新一次参数。batch_size等效于:gradient_accumulation_steps*per_device_train_batch_size |
eval_steps | 每 n 步做一次验证集评估 |
save_steps | 每 n 步保存一次checkpoint |
save_total_limit | 最多保留 x 个 checkpoint,旧的自动删除(省磁盘) |
logging_steps | 每 n 步打印一次 loss 等训练指标 |
max_length | 每条数据最大 token 长度,超出截断(影响显存) |
output_dir | 模型输出文件夹 |
system | 自动添加的系统提示词 |
warmup_ratio | 前 n% 步数学习率从 0 线性预热到目标值,防止训练初期不稳定 |
dataloader_num_workers | 数据加载的并行进程数,加快数据读取 |
model_name | 模型名词 |
model_author | 模型作者 |
SFT微调后测试
方式一:命令行交互推理
微调后模型效果:
swift infer \
--adapters /data/fine-tuning/output/qwen2.5-7b-sft/v1-20260313-113018/checkpoint-210 \
--stream true

微调前模型效果:
swift infer \
--model Qwen/Qwen2.5-7B-Instruct \
--stream true

方式二:单条测试(非交互)
swift infer \
--adapters /data/fine-tuning/output/qwen2.5-7b-sft/v1-20260313-113018/checkpoint-210 \
--stream true \
--infer_backend pt \
--val_dataset /data/fine-tuning/alpaca_zh.jsonl
infer_backend参数-推理框架选择:
参数值 | 速度 | 是否系统自带 |
pt | 慢 | √ |
vllm | 快 | × |
sglang | 最快 | × |
lmdeploy | 快 | × |
2.3.2 VLM 视觉语言模型(因果语言)
训练
- 第一步:下载图片数据集
下载代码如下(500条数据):
from modelscope.msdatasets import MsDataset
import json, os
os.makedirs('/data/fine-tuning-vlm/train_data/images', exist_ok=True)
ds = MsDataset.load(
'swift/RLAIF-V-Dataset',
split='train',
download_mode='reuse_dataset_if_exists'
)
out_path = '/data/fine-tuning-vlm/train_data/rlaif_v.jsonl'
count = 0
with open(out_path, 'w', encoding='utf-8') as f:
for i, row in enumerate(ds):
if count >= 500:
break
if i % 50 == 0:
print(f"处理中: {count}/500")
row = dict(row)
img = row.get('image')
caption = row.get('chosen') or row.get('caption') or ''
if not img or not caption:
continue
img_path = f'/data/fine-tuning-vlm/train_data/images/{count:04d}.jpg'
if hasattr(img, 'save'):
img.save(img_path)
item = {
"messages": [
{"role": "user", "content": "<image>请描述这张图片"},
{"role": "assistant", "content": str(caption)}
],
"images": [img_path]
}
f.write(json.dumps(item, ensure_ascii=False) + '\n')
count += 1
print(f"已保存 {count} 条到 {out_path}")
单个数据格式示例:
{
"messages": [
{
"role": "user",
"content": "<image>请描述这张图片"
},
{
"role": "assistant",
"content": "A leather crafter is more likely to use these tools. The image shows various crafting tools, including scissors and a hole punch, which are commonly used in leatherworking projects. Leather is a material that requires cutting, shaping, and precise hole-punching techniques to create desired designs or patterns. In contrast, paper crafters typically use different types of tools, such as adhesives, decorative papers, or specialized cutting machines like the Silhouette Cameo, for their projects."
}
],
"images": [
"/data/fine-tuning-vlm/train_data/images/0000.jpg"
]
}
- 第二步:安装pytorch视觉处理库并运行命令
pip install "torchvision==0.24.0" --no-deps
CUDA_VISIBLE_DEVICES=0 \
MAX_PIXELS=1003520 \
swift sft \
--model Qwen/Qwen2.5-VL-7B-Instruct \
--dataset /data/fine-tuning-vlm/train_data/rlaif_v.jsonl \
--split_dataset_ratio 0.01 \
--train_type lora \
--torch_dtype bfloat16 \
--num_train_epochs 1 \
--per_device_train_batch_size 1 \
--per_device_eval_batch_size 1 \
--learning_rate 1e-4 \
--lora_rank 8 \
--lora_alpha 32 \
--target_modules all-linear \
--freeze_vit true \
--gradient_accumulation_steps 16 \
--eval_steps 50 \
--save_steps 50 \
--save_total_limit 2 \
--logging_steps 5 \
--max_length 2048 \
--output_dir /data/fine-tuning-vlm/output \
--warmup_ratio 0.05 \
--dataloader_num_workers 4
参数详解:
参数 | 含义 |
freeze_vit | 一般为true,冻结视觉编码器。(大型数据集训练时可使用false) |
MAX_PIXELS | 控制图片最大分辨率,图片超过这个分辨率自动缩小。 举例:1003520 = 1280 × 28 × 28(Qwen2.5-VL 的 patch 尺寸) |
SFT微调后测试
命令行交互推理
测试图像:

微调后模型效果:
swift infer \
--adapters /data/fine-tuning-vlm/output/v4-20260316-102418/checkpoint-31 \
--stream true \
--infer_backend pt

微调前模型效果:

2.3.3 序列分类
训练
- 第一步:下载分类数据集
from modelscope.msdatasets import MsDataset
import json, os
os.makedirs('/data/fine-tuning-seq-cls/train_data', exist_ok=True)
# 下载 DAMO_NLP/jd 的 cls 子集
ds = MsDataset.load('DAMO_NLP/jd', subset_name='default', split='train')
out_path = '/data/fine-tuning-seq-cls/train_data/jd_cls.jsonl'
count = 0
with open(out_path, 'w', encoding='utf-8') as f:
for i, row in enumerate(ds):
if count >= 2000:
break
row = dict(row)
sentence = row.get('sentence') or ''
label = row.get('label')
if not sentence or label is None:
continue
item = {
"query": sentence,
"label": int(label)
}
f.write(json.dumps(item, ensure_ascii=False) + '\n')
count += 1
if count % 200 == 0:
print(f"已处理 {count} 条...")
print(f"已保存 {count} 条到 {out_path}")
单个示例数据如下所示 (label 仅含 0, 1 两类)
{"query": "一百多和三十的也看不出什么区别,包装精美,质量应该不错。",
"label": 1}
- 第二步运行命令
CUDA_VISIBLE_DEVICES=0 \
swift sft \
--model Qwen/Qwen2.5-0.5B \
--train_type lora \
--dataset /data/fine-tuning-seq-cls/train_data/jd_cls.jsonl \
--load_from_cache_file true \
--split_dataset_ratio 0.01 \
--torch_dtype bfloat16 \
--num_train_epochs 1 \
--per_device_train_batch_size 1 \
--per_device_eval_batch_size 1 \
--learning_rate 1e-4 \
--lora_rank 8 \
--lora_alpha 32 \
--target_modules all-linear \
--gradient_accumulation_steps 16 \
--eval_steps 50 \
--save_steps 50 \
--save_total_limit 2 \
--logging_steps 5 \
--max_length 2048 \
--output_dir output \
--warmup_ratio 0.05 \
--dataloader_num_workers 4 \
--num_labels 2 \
--task_type seq_cls \
--use_chat_template false
参数详解:
参数 | 含义 |
task_type | 任务类型 |
num_labels | 标签数量 = 2 |
SFT微调后测试
命令行交互推理
微调后模型效果:
swift infer
--adapters /data/fine-tuning-seq-cls/output/v2-20260316-112238/checkpoint-124
--stream true
--infer_backend pt

微调前模型效果:
swift infer
--model Qwen/Qwen2.5-0.5B
--stream true

2.3.4 文本嵌入
训练
- 第一步:下载示例数据集
import os
os.environ['HF_ENDPOINT'] = 'https://hf-mirror.com'
from datasets import load_dataset
import json
os.makedirs('/data/fine-tuning-embedding/train_data', exist_ok=True)
ds = load_dataset('sentence-transformers/stsb', split='train', trust_remote_code=True)
out_path = '/data/fine-tuning-embedding/train_data/stsb_positive.jsonl'
count = 0
with open(out_path, 'w', encoding='utf-8') as f:
for row in ds:
# 只保留高相似度样本
if float(row['score']) >= 0.75:
if count >= 1000:
break
item = {
"messages": [
{"role": "user", "content": row['sentence1']}
],
"positive_messages": [
[{"role": "user", "content": row['sentence2']}]
]
}
f.write(json.dumps(item, ensure_ascii=False) + '\n')
count += 1
print(f"已保存 {count} 条正样本到 {out_path}")
单个示例数据如下所示(本案例使用InfoNCE 损失函数,训练对需全为正样本)
{"query": "A plane is taking off.", "response": "An air plane is taking off."}
- 第二步:运行命令
CUDA_VISIBLE_DEVICES=0 \
INFONCE_TEMPERATURE=0.1 \
swift sft \
--model Qwen/Qwen3-Embedding-0.6B \
--task_type embedding \
--train_type full \
--dataset /data/fine-tuning-embedding/train_data/stsb_positive.jsonl \
--torch_dtype bfloat16 \
--num_train_epochs 2 \
--per_device_train_batch_size 4 \
--per_device_eval_batch_size 4 \
--gradient_accumulation_steps 4 \
--learning_rate 6e-6 \
--loss_type infonce \
--dataloader_drop_last true \
--use_chat_template false \
--output_dir /data/fine-tuning-emb/output \
--save_steps 50 \
--logging_steps 5
SFT微调后测试
测试代码:
import torch
import torch.nn.functional as F
from transformers import AutoModel, AutoTokenizer
model_dir = '/data/fine-tuning-embedding/output/v1-20260316-142640/checkpoint-126'
tokenizer = AutoTokenizer.from_pretrained(model_dir, trust_remote_code=True)
model = AutoModel.from_pretrained(
model_dir,
torch_dtype=torch.bfloat16,
device_map="cuda:0",
trust_remote_code=True
)
model.eval()
{"messages": [{"role": "user", "content": ""}], "positive_messages": [[{"role": "user", "content": ""}]]}
texts = [
"A man is playing a guitar.",
"A man is playing an electric guitar.",
"A boy is playing a game"
]
inputs = tokenizer(texts, padding=True, truncation=True, max_length=512, return_tensors="pt").to("cuda:0")
with torch.no_grad():
outputs = model(**inputs)
# 拿到最后一层输出的特征矩阵
last_hidden_states = outputs.last_hidden_state
attention_mask = inputs['attention_mask']
input_mask_expanded = attention_mask.unsqueeze(-1).expand(last_hidden_states.size()).float()
embeddings = torch.sum(last_hidden_states * input_mask_expanded, 1) / torch.clamp(input_mask_expanded.sum(1), min=1e-9)
embeddings = F.normalize(embeddings, p=2, dim=1)
#计算余弦相似度
sim_0_1 = torch.dot(embeddings[0], embeddings[1])
sim_0_2 = torch.dot(embeddings[0], embeddings[2])
print("\n========== 测试结果 ==========")
print(f"句子 A: [{texts[0]}]")
print(f"句子 B: [{texts[1]}]")
print(f"句子 C: [{texts[2]}]\n")
print(f"A 和 B (意思相近) 的相似度: {sim_0_1.item():.4f}")
print(f"A 和 C (意思无关) 的相似度: {sim_0_2.item():.4f}")
print("==============================\n")

2.3.5 重排序
训练
- 第一步:下载示例数据集
import os
import json
import random
# 使用国内镜像加速 HuggingFace 下载
os.environ['HF_ENDPOINT'] = 'https://hf-mirror.com'
from datasets import load_dataset
out_dir = '/data/fine-tuning-reranker/train_data'
os.makedirs(out_dir, exist_ok=True)
ds = load_dataset('cmrc2018', split='train', trust_remote_code=True)
# 提取数据集中所有的上下文段落并去重
all_contexts = list(set([row['context'] for row in ds]))
out_path = os.path.join(out_dir, 'cmrc2018_reranker.jsonl')
count = 0
max_samples = 1000 # 生成 1000 条数据
num_negatives = 3 # 配合 ms-swift 默认配置:每 1 个正样本,配 3 个负样本
with open(out_path, 'w', encoding='utf-8') as f:
for row in ds:
if count >= max_samples:
break
query = row['question']
pos_doc = row['context']
neg_docs = random.sample([ctx for ctx in all_contexts if ctx != pos_doc], num_negatives)
item = {
"messages": [
{"role": "user", "content": query}
],
"positive_messages": [
[{"role": "assistant", "content": pos_doc}] # 注意:这是二维列表嵌套
],
"negative_messages": [
[{"role": "assistant", "content": neg}] for neg in neg_docs # 动态生成 3 个负样本的二维列表
]
}
# 写入 JSONL
f.write(json.dumps(item, ensure_ascii=False) + '\n')
count += 1
print(f"已成功保存 {count} 条重排序(Reranker)训练数据到 {out_path}")
单个示例数据如下所示
{
"messages": [
{
"role": "user",
"content": "Lazard公司的员工有多少人?"
}
],
"positive_messages": [
[
{
"role": "assistant",
"content": "Lazard Ltd(中文名称:瑞德集团,拉扎德或雷达飞瑞集团等,但尚未受到媒体广泛采用)是一家注册在百慕大群岛的投资银行,主要经营公司财务和资产管理业务。该公司是纽约证券交易所上市公司,交易代码为LAZ, 2014年12月市值约为62亿美元。Lazard的历史可以追溯到1848,是全球最著名的精品投资银行之一,虽然只有两千多名员工,却在兼并收购、重组和资产管理等领域具有悠久的历史和很强的实力。https://web.archive.org/web/20081220121354/http://www.lazard.com/PDF/Lazard%20FactSheet.pdf"
}
]
],
"negative_messages": [
[
{
"role": "assistant",
"content": "《多宝塔碑》是唐代重要碑刻,是书法中楷书代表作品。此碑是颜真卿书,是为颜真卿早期楷书代表作品,也是颜体书法的代表帖。《多宝塔碑》,又称作《多宝塔感应碑》,全称为《大唐西京千福寺多宝塔感应碑》,《多宝塔碑》立于唐玄宗天宝十一年(752年)四月二十日,该年颜真卿正值四十四岁,担任朝议郎尚书,奉旨书写此碑。《多宝塔碑》的碑文共有三十四行,满行有六十六个字,全文两千多字,由相门后裔南阳岑勋撰文,越州徐浩以隶书提额,河南史华刻字。碑体总高285公分,宽度102公分,唐朝时立碑于长安安定坊千福寺,宋代时移到西安碑林,清朝康熙年间碑体折断,现收藏于西安碑林博物馆,属于国宝级文物。"
}
],
[
{
"role": "assistant",
"content": "法比安·恩斯特(Fabian Ernst,),出生于德国汉诺威,是德国足球运动员,司职防守中场,效力土耳其联赛班霸比锡达斯。出身于德国小型球会汉诺威96,曾于1998-2000年间效力汉堡。效力汉堡时共上阵48场,没有进球。恩斯特终其球员生涯,效力最大的球会乃云达不莱梅。这也是恩斯特最成功之时。他于2000-05年间效力,一共出赛152场德甲,打入11球。这段期间恩斯特随球会赢得2004年德甲和德国杯双料冠军,并于翌年打入欧洲联赛冠军杯。2005年他转会到沙尔克04,可是却只能取得两届德甲亚军(2005、2007)。2009年,恩斯特征战海外,转至土耳其班霸比锡达斯。恩斯特乃于2002年首次进入德国国家队。惟迄今仅参加过2004年欧洲国家杯一项大型赛事。截至2007年,他代表国家队出场24次,打入1球。"
}
],
[
{
"role": "assistant",
"content": "张处瑾(),燕人,五代十国初期成德节度使留后张文礼的儿子。921年,张文礼发动兵变,杀死了赵王王镕全家,自立为留后。他既称臣于晋王李存勖又私通后梁,还勾结契丹耶律阿保机。李存勖以为王镕报仇为名,以王镕旧将符习为成德留后,又派相州刺史史建瑭、天平节度使阎宝,率军讨伐镇州。八月十一,晋军攻下了赵州,张文礼大惊腹疽发作而死。张处瑾秘不发丧,多次向李存勖谢罪未果,坚守镇州一年有余,晋军遭受重大打击,史建瑭阵亡,阎宝羞愤而死,随后的主帅昭义节度使李嗣昭、振武节度使李存进也相继阵亡。期间张处瑾又被弟张处球夺权。922年九月廿九,镇州粮尽,第四位晋军主帅李存审(符存审)破城,张处瑾及张处球、弟张处琪及张文礼妻(未知是否张处瑾母)被李存勖处死,张文礼的尸体在市上被车裂。"
}
]
]
}
- 第二步:运行命令
MAX_POSITIVE_SAMPLES=1 \
MAX_NEGATIVE_SAMPLES=3 \
CUDA_VISIBLE_DEVICES=0 \
swift sft \
--model Qwen/Qwen3-Reranker-0.6B \
--task_type generative_reranker \
--loss_type generative_reranker \
--padding_side left \
--label_names labels \
--train_type lora \
--target_modules all-linear \
--dataset /data/fine-tuning-reranker/train_data/cmrc2018_reranker.jsonl \
--torch_dtype bfloat16 \
--num_train_epochs 3 \
--per_device_train_batch_size 4 \
--gradient_accumulation_steps 8 \
--max_length 1024 \
--learning_rate 1e-4 \
--output_dir /data/fine-tuning-reranker/output \
--dataloader_num_workers 8 \
--logging_steps 5 \
--save_steps 100 \
--save_total_limit 2
SFT微调后测试
import torch
import torch.nn.functional as F
from transformers import AutoModelForCausalLM, AutoTokenizer
from peft import PeftModel
from modelscope import snapshot_download
base_model_dir = snapshot_download("Qwen/Qwen3-Reranker-0.6B")
lora_dir = "/data/fine-tuning-reranker/output/v0-20260316-171006/checkpoint-96"
tokenizer = AutoTokenizer.from_pretrained(base_model_dir, trust_remote_code=True)
# 对于多文档批量测试,必须显式设置左补齐
tokenizer.padding_side = "left"
if tokenizer.pad_token_id is None:
tokenizer.pad_token_id = tokenizer.eos_token_id
model = AutoModelForCausalLM.from_pretrained(
base_model_dir, device_map="cuda:0", torch_dtype=torch.bfloat16, trust_remote_code=True
)
model = PeftModel.from_pretrained(model, lora_dir)
model.eval()
yes_token_id = tokenizer.encode("yes", add_special_tokens=False)[0]
no_token_id = tokenizer.encode("no", add_special_tokens=False)[0]
#1 个问题,对应 5 个被粗召回的候选文档
query = "什么是深度学习?"
candidate_docs = [
"苹果手机的最新款有很多新功能,比如摄像头提升了。", # 明显无关
"深度学习是机器学习的一个分支,基于人工神经网络,能够从大量数据中自动提取特征。", # 最相关,绝对的Top1
"今天天气真不错,适合出去玩。", # 完全无关
"机器学习是一门多领域交叉学科,专门研究计算机怎样模拟或实现人类的学习行为。", # 有点相关,应该排第2
"神经网络模型需要大量的算力来进行矩阵乘法运算,GPU是最好的选择。" # 侧面相关,排第3
]
# 批量构建 Prompt 列表
prompts = []
for doc in candidate_docs:
prompt = (
"<|im_start|>system\n"
"Judge whether the Document meets the requirements based on the Query and the Instruct provided. "
"Note that the answer can only be \"yes\" or \"no\".<|im_end|>\n"
"<|im_start|>user\n"
"<Instruct>: Given a web search query, retrieve relevant passages that answer the query\n"
f"<Query>: {query}\n"
f"<Document>: {doc}<|im_end|>\n"
"<|im_start|>assistant\n"
)
prompts.append(prompt)
# 批量 Tokenize,转化为 GPU 张量
inputs = tokenizer(prompts, padding=True, truncation=True, max_length=1024, return_tensors="pt").to("cuda:0")
print(inputs)
with torch.no_grad():
outputs = model(**inputs)
last_token_logits = outputs.logits[:, -1, :]
# 批量提取所有样本的 yes 和 no 的 logits
yes_logits = last_token_logits[:, yes_token_id]
no_logits = last_token_logits[:, no_token_id]
score_matrix = torch.stack([yes_logits, no_logits], dim=1)
probs = F.softmax(score_matrix, dim=1)
final_scores = probs[:, 0].tolist()
# 排序 (Rerank)
scored_docs = list(zip(candidate_docs, final_scores))
scored_docs.sort(key=lambda x: x[1], reverse=True)
print(f"\n========== Rerank 最终重排序结果 ==========")
print(f"Query: [{query}]\n")
for rank, (doc, score) in enumerate(scored_docs):
print(f"Top {rank+1} (得分: {score:.4f}): {doc}")
print("=========================================")
结果:
