
模型精调
若模型表现不能满足您的需要,您可以使用模型精调能力,通过SFT、DPO、CPT的方式对模型参数进行优化,使其更加适配业务场景。
体验链接:模型精调
一、判断精调必要性
精调限制
- 难以通过精调实现模型通用基础能力,如推理能力优化、长上下文理解等能力的大幅提升;
- 难以通过精调提高模型对高时效性信息的检索能力,建议您使用Function Call调用支持联网搜索的插件;
- 难以通过精调提高模型对特定领域信息的检索能力,建议您使用知识库能力。
精调成本
- 需高质量标注数据(如问答对、偏好排序),数据清洗和标注可能消耗大量人力;
- 超参数调优、验证集迭代可能需多次试验,耗时数天至数周。
二、精调方式介绍
2.1 SFT(有监督微调)
2.1.1 什么是 SFT
SFT(Supervised Fine-Tuning,有监督微调):是使用标注好的问答数据对预训练模型进行进一步训练的技术。通过让模型在特定领域的高质量数据上学习,使其掌握该领域的知识、术语和回答规范。
2.1.2 SFT 核心价值
- 任务适应:使通用模型快速适应特定业务场景
- 性能提升:在特定任务上,经过微调的小模型可能超越通用大模型
- 数据高效:不需要海量数据,数百至数千条高质量数据即可产生明显效果
- 成本可控:微调成本远低于从零训练一个模型
2.1.3 典型应用场景
- 场景 1:企业客服对话优化
- 痛点:通用模型不了解公司产品和话术规范
- 方案:使用公司历史客服数据进行 SFT,使模型掌握公司话术和产品知识
- 效果:回答准确率和客户满意度可显著提升
- 场景 2:垂直领域文本生成
- 痛点:法律文书、医疗问诊、金融报告等场景需要专业知识
- 方案:使用领域专业数据进行 SFT,使模型掌握行业术语和业务逻辑
- 效果:输出内容的专业性和准确性可大幅提升
- 场景 3:特定格式输出适配
- 痛点:需要模型输出 JSON、XML 等结构化数据,通用模型格式正确率不高
- 方案:使用标准格式示例进行 SFT,训练模型严格按格式输出
- 效果:结构化输出的格式正确率可显著提高
- 场景 4:品牌语气风格定制
- 痛点:品牌有独特调性(如活泼、专业、温暖),通用模型风格不匹配
- 方案:使用符合品牌风格的问答数据进行 SFT
- 效果:模型输出风格与品牌调性高度一致
2.1.4 核心能力
1)模型支持
SFT 支持文本生成、图像理解、图像生成、图像编辑、文生视频、图生视频六种种任务类型
2)训练方法:全量更新 vs LoRA
建议用户先使用【 LoRA 】快速验证效果,满意后再评估是否需要【全量更新】。
对比维度 | 全量更新(Full Fine-Tuning) | LoRA(低秩适应) |
原理 | 更新模型所有参数 | 仅更新少量新增的低秩参数 |
训练速度 | 较慢 | 较快 |
显存占用 | 大 | 小 |
效果上限 | 更高,参数充分调整 | 略低,但大多数场景可满足需求 |
适用场景 | 数据量大、追求极致效果 | 数据量适中、快速迭代、成本敏感 |
推荐程度 | 适合大客户、高要求场景 | 大多数客户的首选方案 |
3)超参数
以下参数对训练效果有直接影响,万擎平台为上述参数提供了合理的默认值,客户无需具备深度学习调参经验即可完成微调。对于有经验的技术团队,平台也支持自定义参数配置。
参数 | 含义 | 说明 |
学习率(Learning Rate) | 模型每次参数更新的幅度 | 过大易导致训练不稳定,过小则收敛缓慢。平台提供默认推荐值 |
训练轮次(Epochs) | 对训练数据的完整遍历次数 | 一般 2-5 轮,过多可能导致过拟合 |
批量大小(Batch Size) | 每次参数更新使用的样本数 | 影响训练速度和显存占用 |
LoRA Rank | LoRA 低秩矩阵的维度 | 值越大学习能力越强,但计算成本也越高 |
4)数据集管理
训练集:支持两种数据来源:
- 平台已发布数据集:万擎内置的公开数据集,客户可直接使用或参考其格式
- 自定义数据集:客户上传自己的业务数据
验证集:用于在训练过程中评估模型效果,防止过拟合:
- 数据拆分:从训练数据中自动按比例拆出一部分作为验证集
- 指定数据集:客户单独上传一份验证数据集
5)模型发布
训练完成后,模型可通过两种方式发布:
- 发布为新模型:创建一个全新的定制模型
- 发布为已有模型的新版本:在现有定制模型基础上迭代更新
2.1.5 效果指标
【⚠️若任务处于排队中状态 ,将无法查看效果指标】
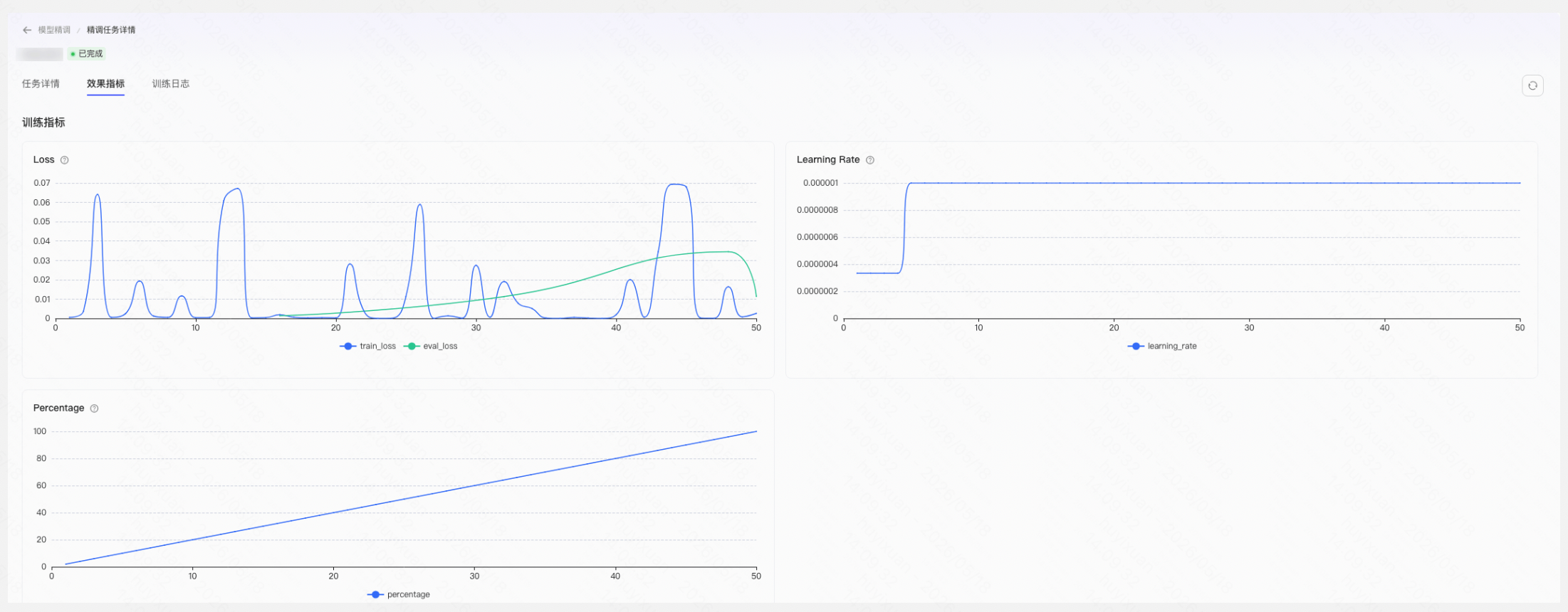
训练过程中,平台会展示以下关键指标:
指标 | 含义 | 判读方式 |
loss(训练损失) | 模型在训练数据上的预测误差 | 应持续下降,表示模型在有效学习 |
eval_loss(验证损失) | 模型在验证数据上的预测误差 | 应持续下降,且与 loss 趋势一致 |
lr(学习率) | 当前的学习率数值 | 一般按预设策略自动调整 |
注意:如果 loss 持续下降但 eval_loss 开始上升,表明模型出现过拟合(仅记住训练数据而非学到通用规律),需调整参数或增加训练数据。
AIGC 专用指标(图像生成 / 图像编辑 / 文生视频/图生视频)
当任务类型为图像生成、图像编辑或文生视频/图生视频时,效果指标页面还将展示以下专项内容:
训练曲线:以折线图展示 training loss / eval loss / LR 指标随训练步数(Step)的变化,hover 数据点显示详细 tooltip。运行中状态下定时轮询拉取增量数据点。
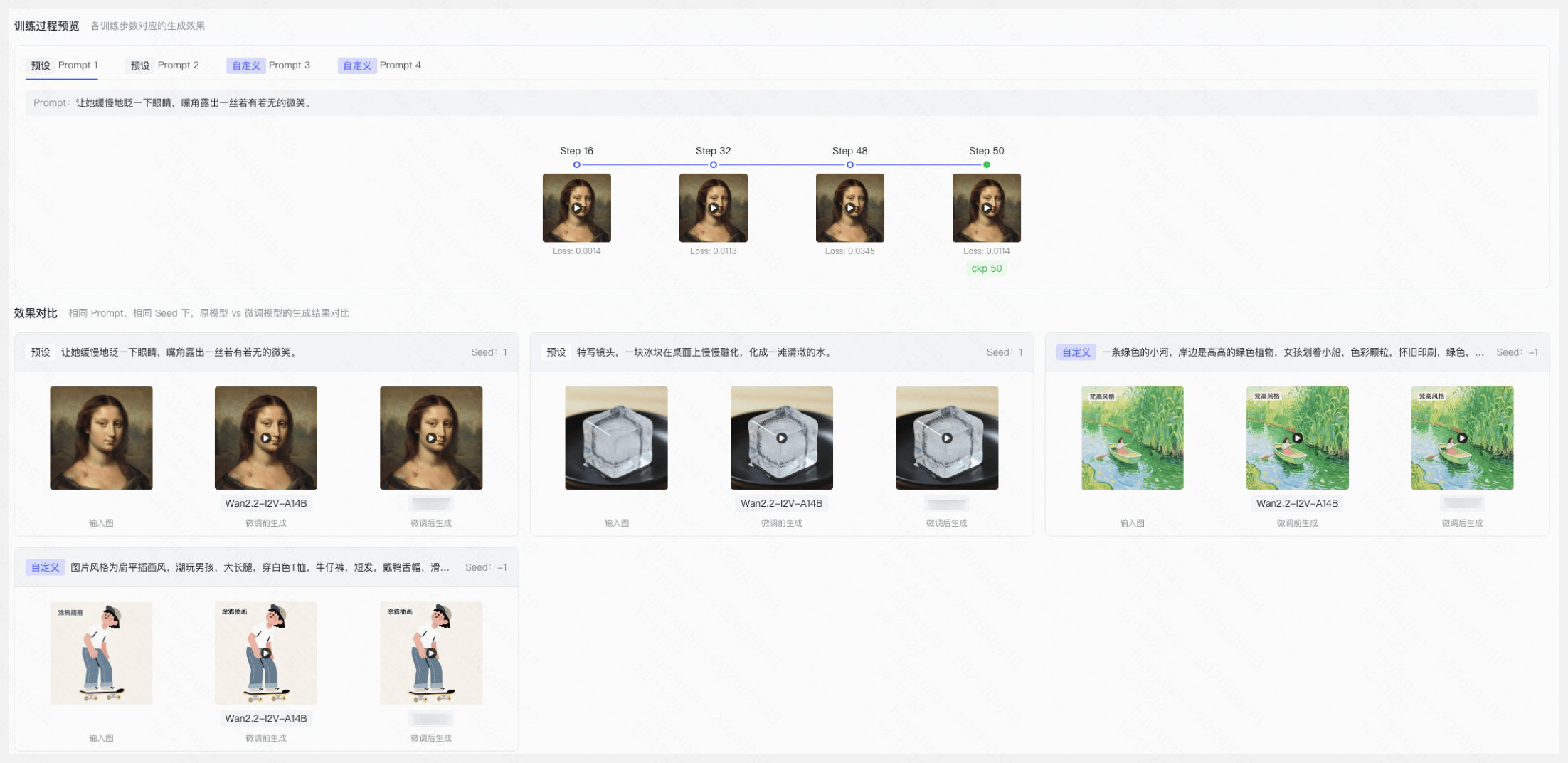
训练过程预览:标题为"各训练步数对应的生成效果"。支持按 Prompt 编号(tab 形式)切换查看不同 Prompt 在各 checkpoint 步数下的生成效果,采用时间线布局,每个节点标注 Step N。各 step 的效果图/视频点击可查看大图或在线播放。
效果对比:展示相同 Prompt、相同 Seed 条件下,原始模型 vs 微调模型的生成结果对比:
任务类型 | 效果对比内容 |
图像生成 | prompt+seed+原模型生成图 vs 微调模型生成图 |
图像编辑 | prompt+ seed+原图+原模型编辑结果 vs 微调模型编辑结果 |
文生视频 | prompt +seed+原模型生成视频 vs 微调模型生成视频 |
图生视频 | prompt+首帧图+seed+原模型生成视频 vs 微调模型生成视频 |
下图为「图生视频」任务示例:
2.1.6 场景示例:电商客服模型定制全流程
前置准备
- 权限申请:
- 主账号(即溪流湖账户)拥有账号下所有项目的访问/管理权限,无需权限申请,主账号可对所有任务进行修改、删除;
- 子账号:可由主账号为名下子账号设置某项目的只读/管理权限,子账号不支持删除主账号新建的任务;
- 若账户余额不足,请先充值;
- 确认权限及余额无问题后,在左侧导航栏中「模型定制」下方点击「模型精调」进入产品页面,点击「+新建精调任务」进入创建页面。
背景:某电商平台使用通用大模型构建智能客服系统,存在以下问题:产品信息回答不准确、话术不符合公司规范、无法处理退换货等特定流程。
目标:定制一个掌握公司业务知识和话术规范的专属客服模型。
Step 1:准备训练数据
整理公司历史客服对话记录,制作「问题-标准回答」配对数据,格式示例:
{
"messages": [
{"role": "system", "content": "你是XX电商的智能客服,请根据公司政策回答客户问题。"},
{"role": "user", "content": "这件衣服有M码吗?"},
{"role": "assistant", "content": "这款商品有S/M/L/XL四个尺码。M码适合身高160-170cm、体重50-60kg的顾客。您可以参考商品详情页的尺码表选择,也可以告知您的身高体重,我为您推荐合适的尺码。"}
]
}
建议准备 500-2000 条高质量问答数据,覆盖主要问题类型。
1.如果已有处理好可直接训练的数据,直接上传即可。
2.若原始数据质量不高、格式不对、分布不均等,需要处理后,才能用于训练,可通过平台产品化工具,对原始数据进行分析、清洗、格式化、增强,生成高质量的「问题-回答」配对数据集,然后再微调。
a. 质量不高:部分对话包含无效信息、重复内容、脏数据
b. 格式不对:原始数据为非结构化文本,未按「问题-标准回答」配对
c. 分布不均:高频问题(如退换货)样本多,低频问题(如跨境物流)样本极少,模型微调后可能偏向高频问题
3.具体处理方法
a. 数据预览与质量分析
操作:「数据集」→ 导入原始客服对话数据(CSV/JSON)→ 提交「数据分析」任务 → 查看数据分析结果(分布、字段统计、空值比例、重复占比等) → 筛选正常符合预期的数据保存为新版本
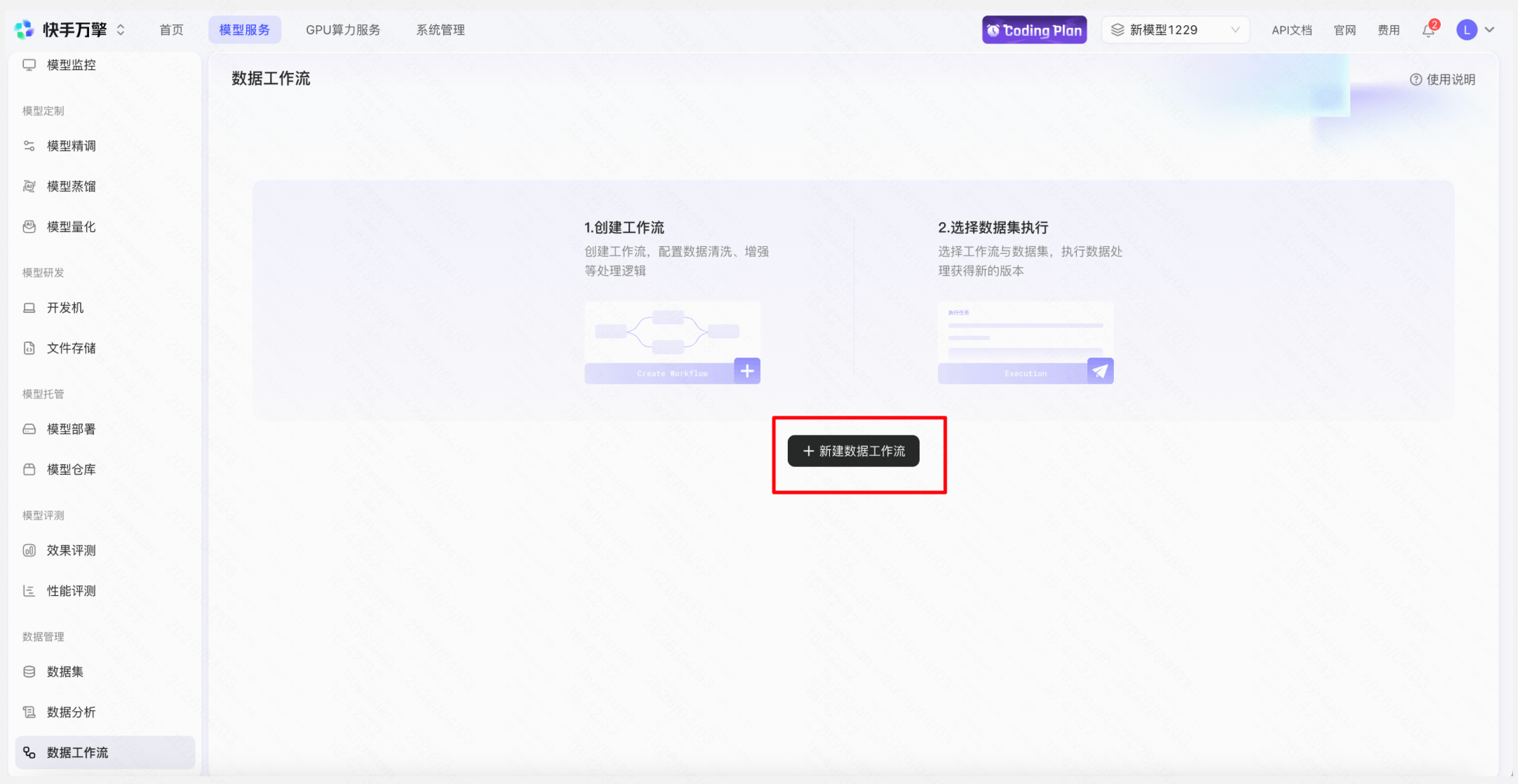
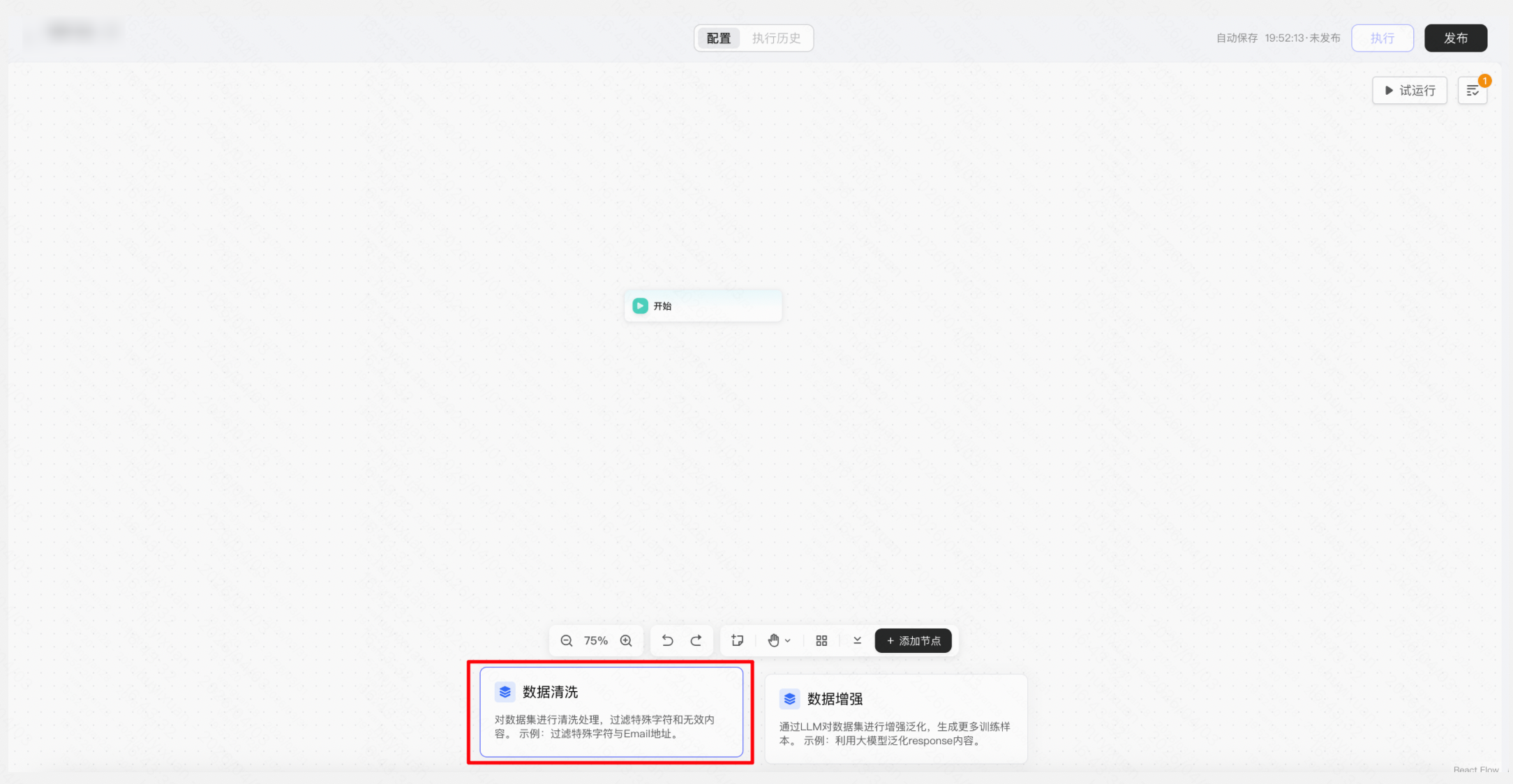
b. 新建数据工作流进行清洗与格式化
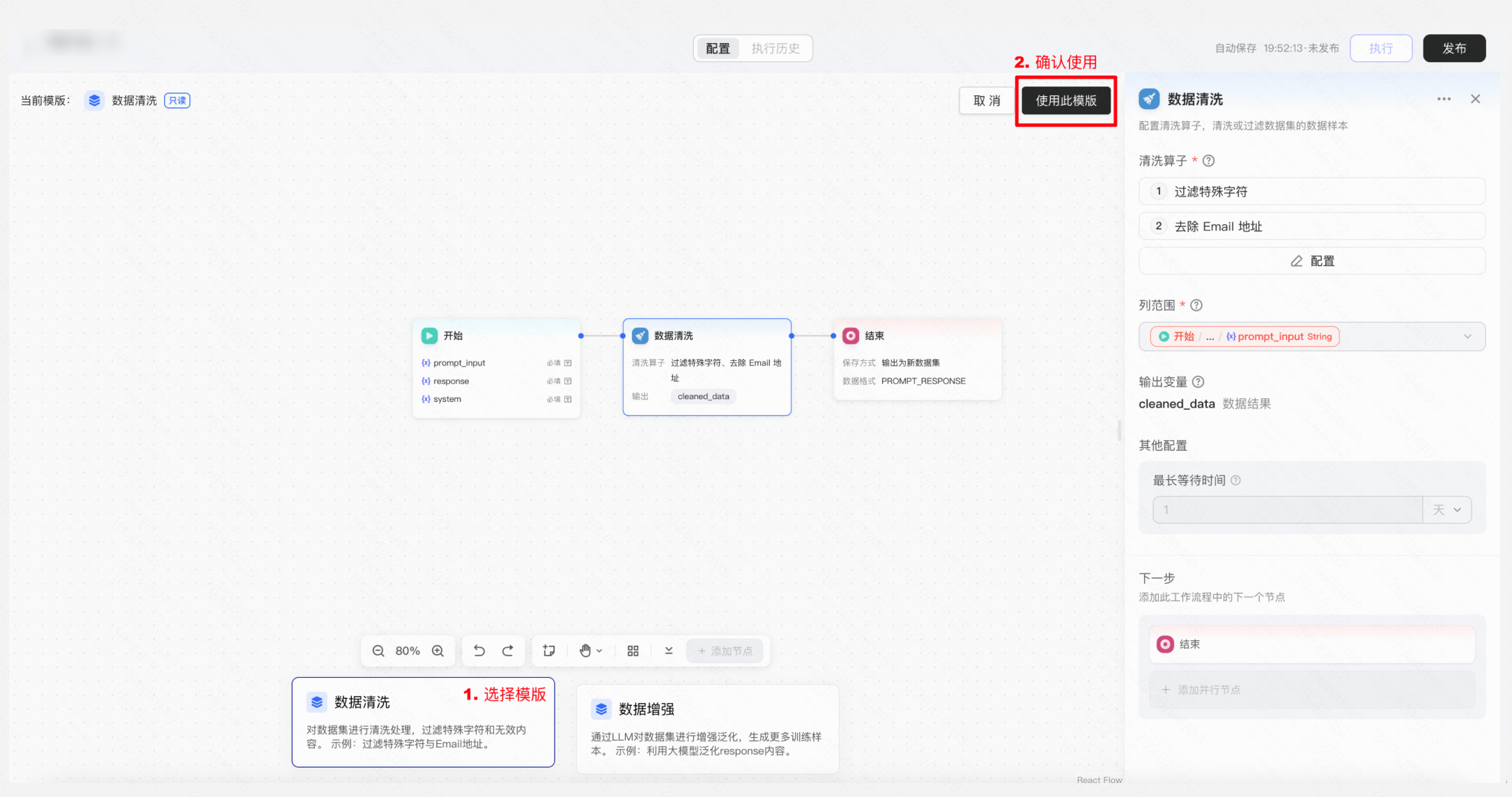
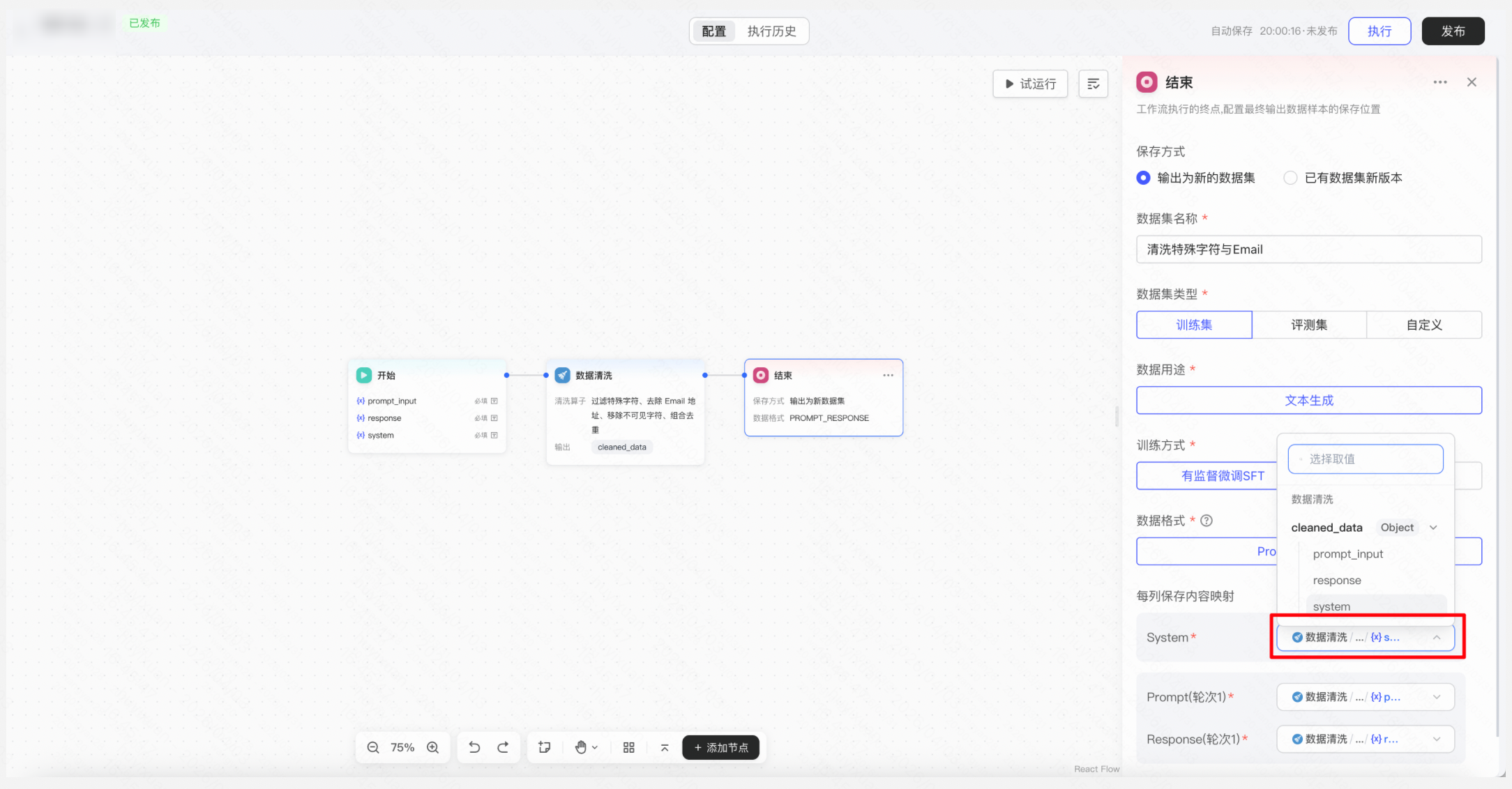
操作:「数据工作流」→ 新建工作流 → 选择「数据清洗」模版,配置清洗规则(去重、过滤空值、过滤特殊字符、去除Email地址等)→设置结束后保存到训练集/文本生成/SFT的列映射 → 发布工作流→ 执行工作流
c. 数据增强与平衡处理
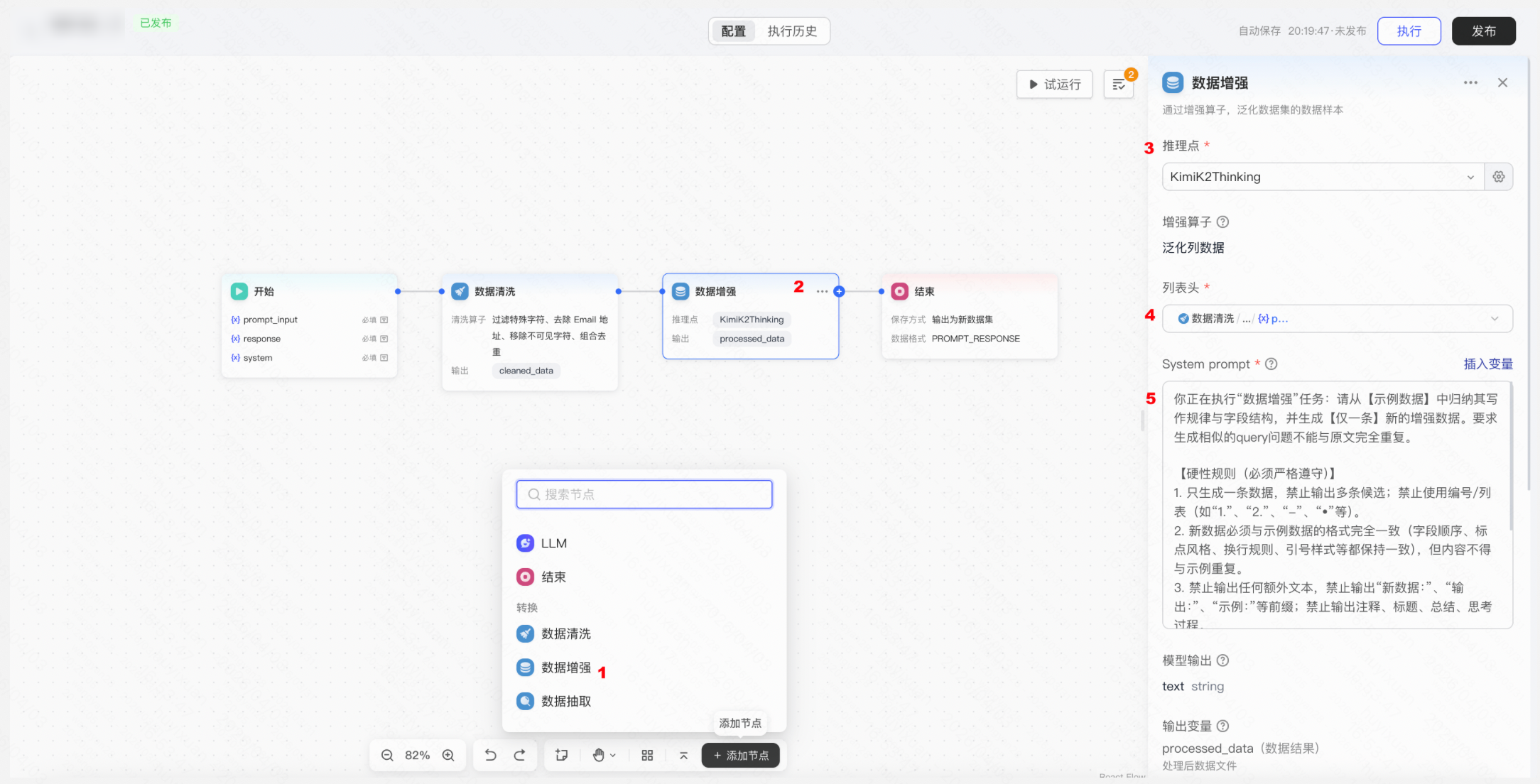
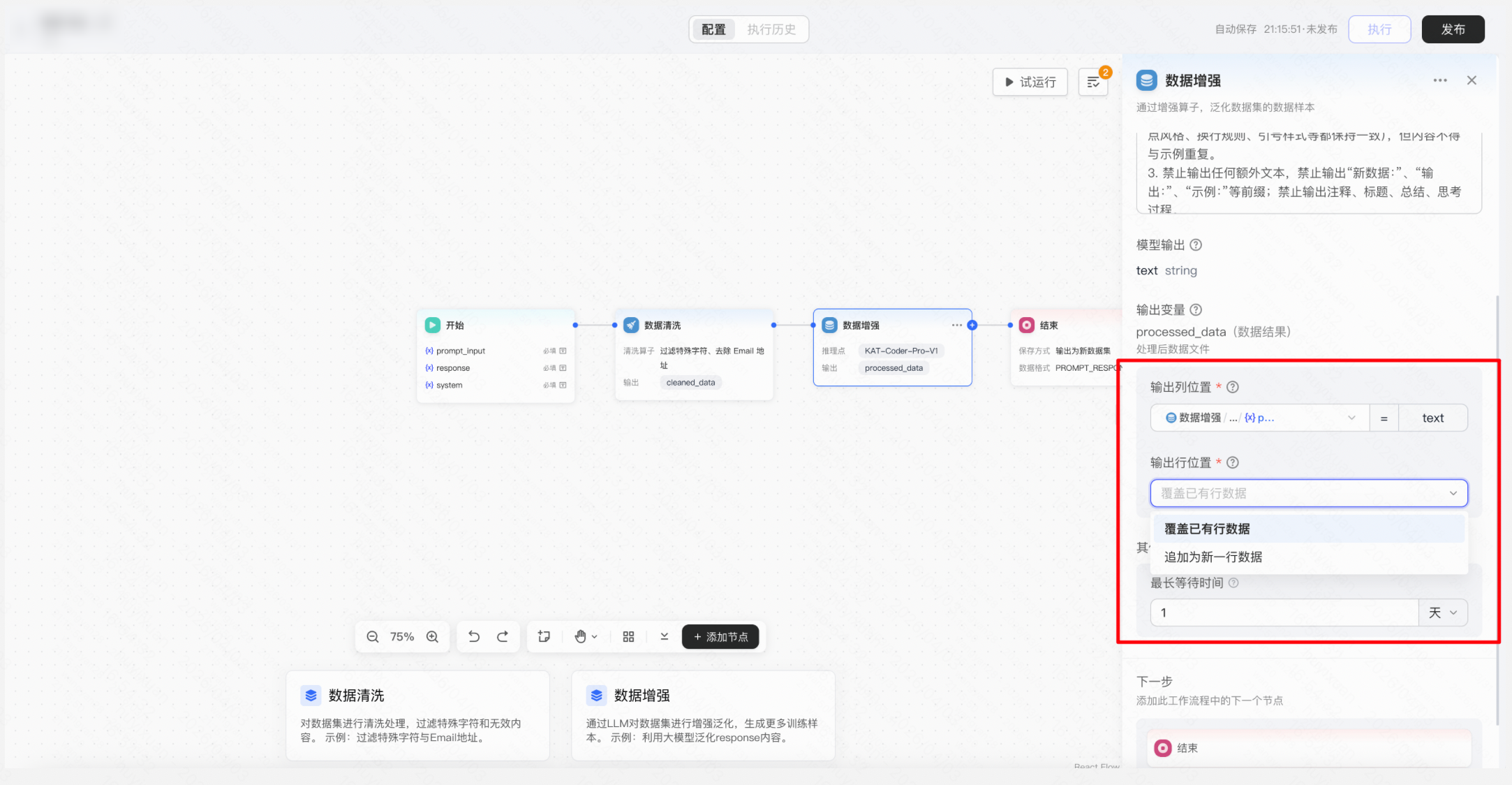
操作:在工作流中继续添加「数据增强」节点 → 选择用于增强的推理点(模型),配置增强策略(大模型生成相似问法),设置保存数据列映射配置&输出策略(新增/覆盖)→ 运行工作流,生成增强后的平衡数据集
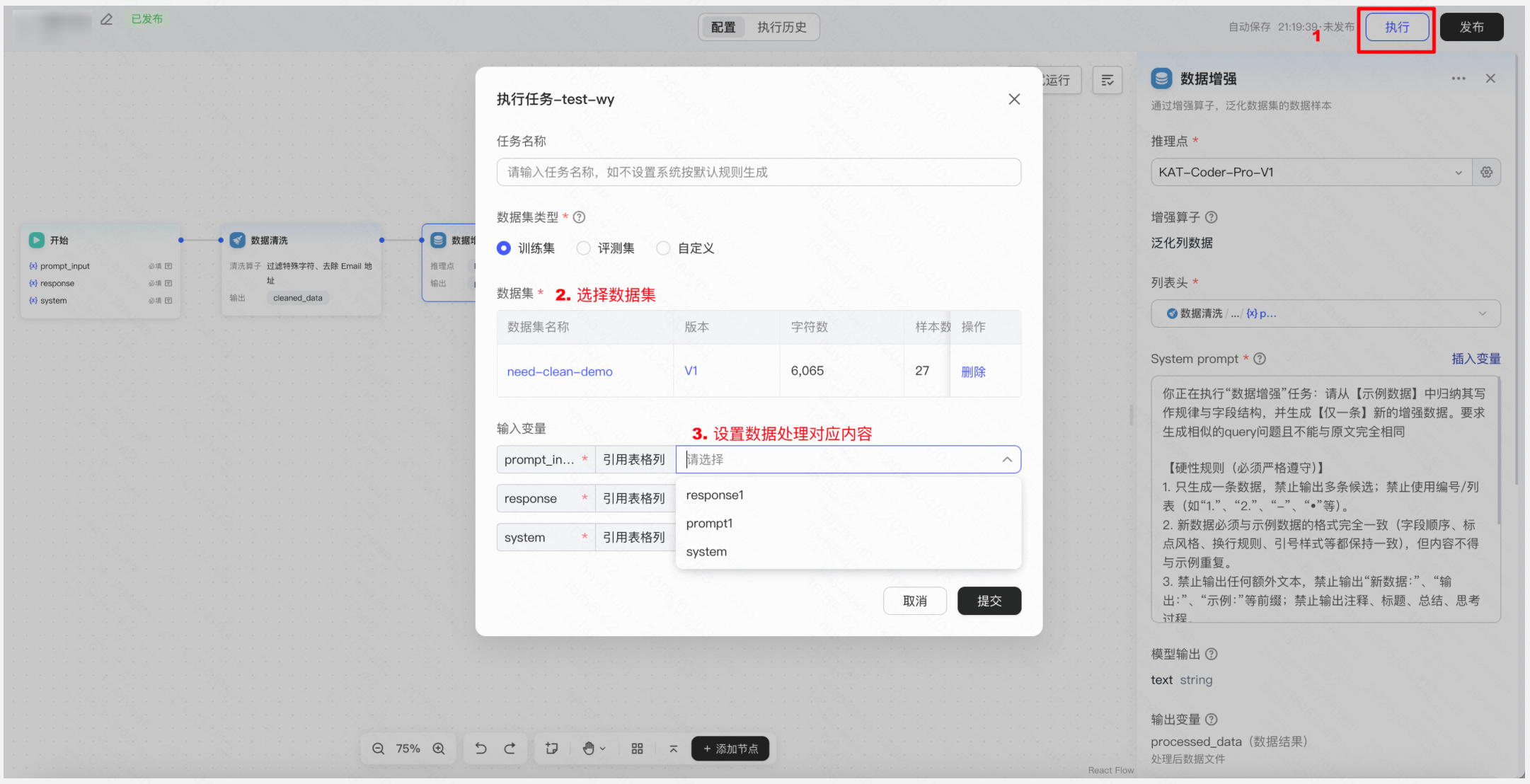
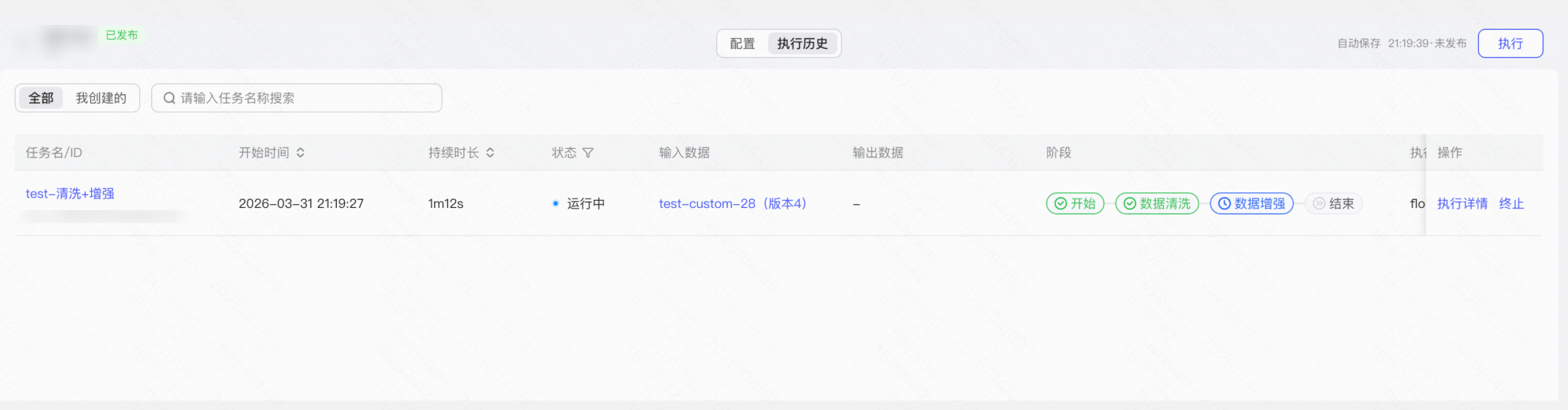
d. 数据集保存与版本管理
操作:「数据工作流」运行完成后 → 将结果数据集保存至平台「数据集」→ 发布数据集,供后续微调任务直接使用
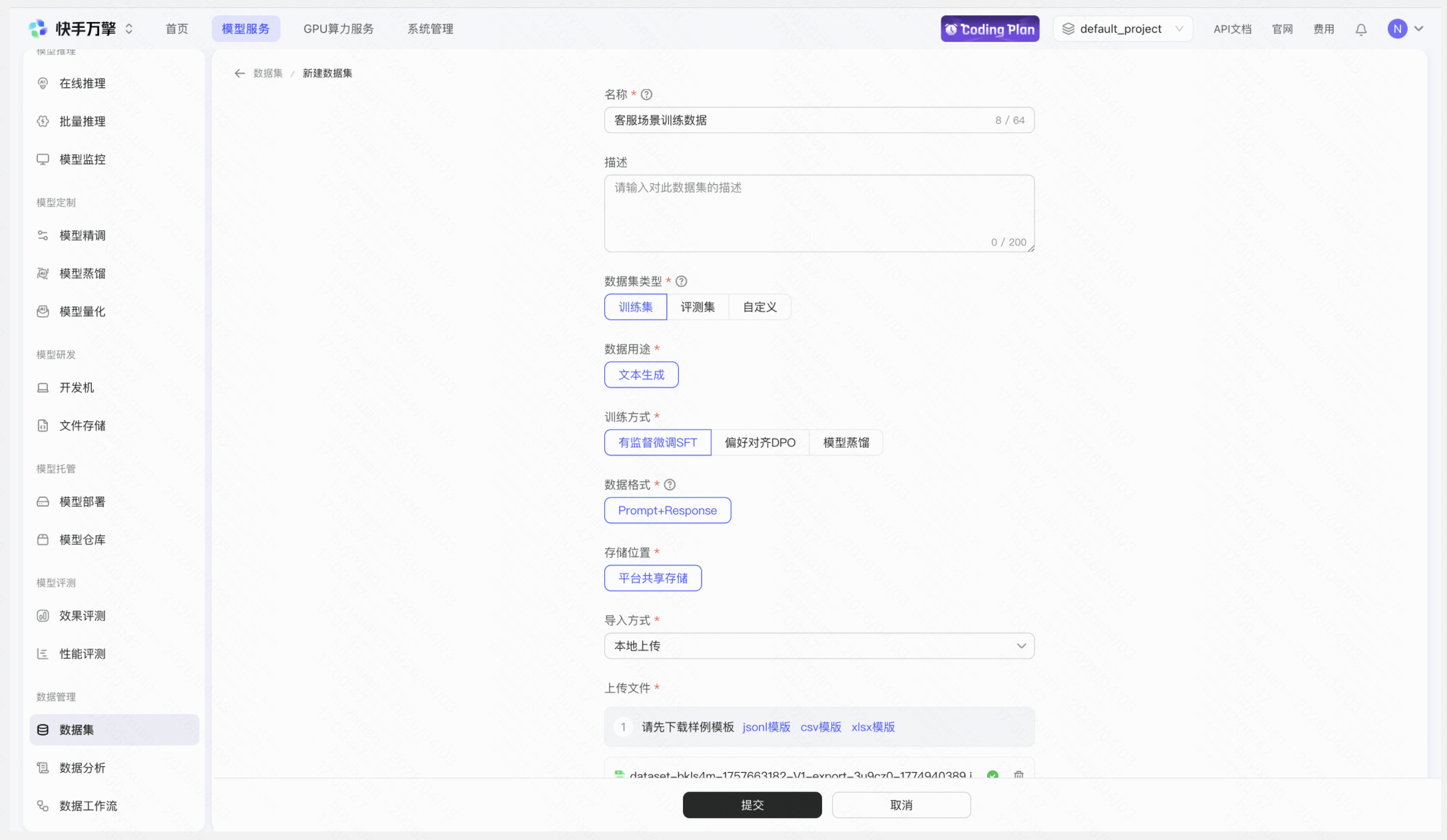
Step 2:上传数据集
在万擎平台「数据集」模块上传数据文件,平台将自动校验数据格式。
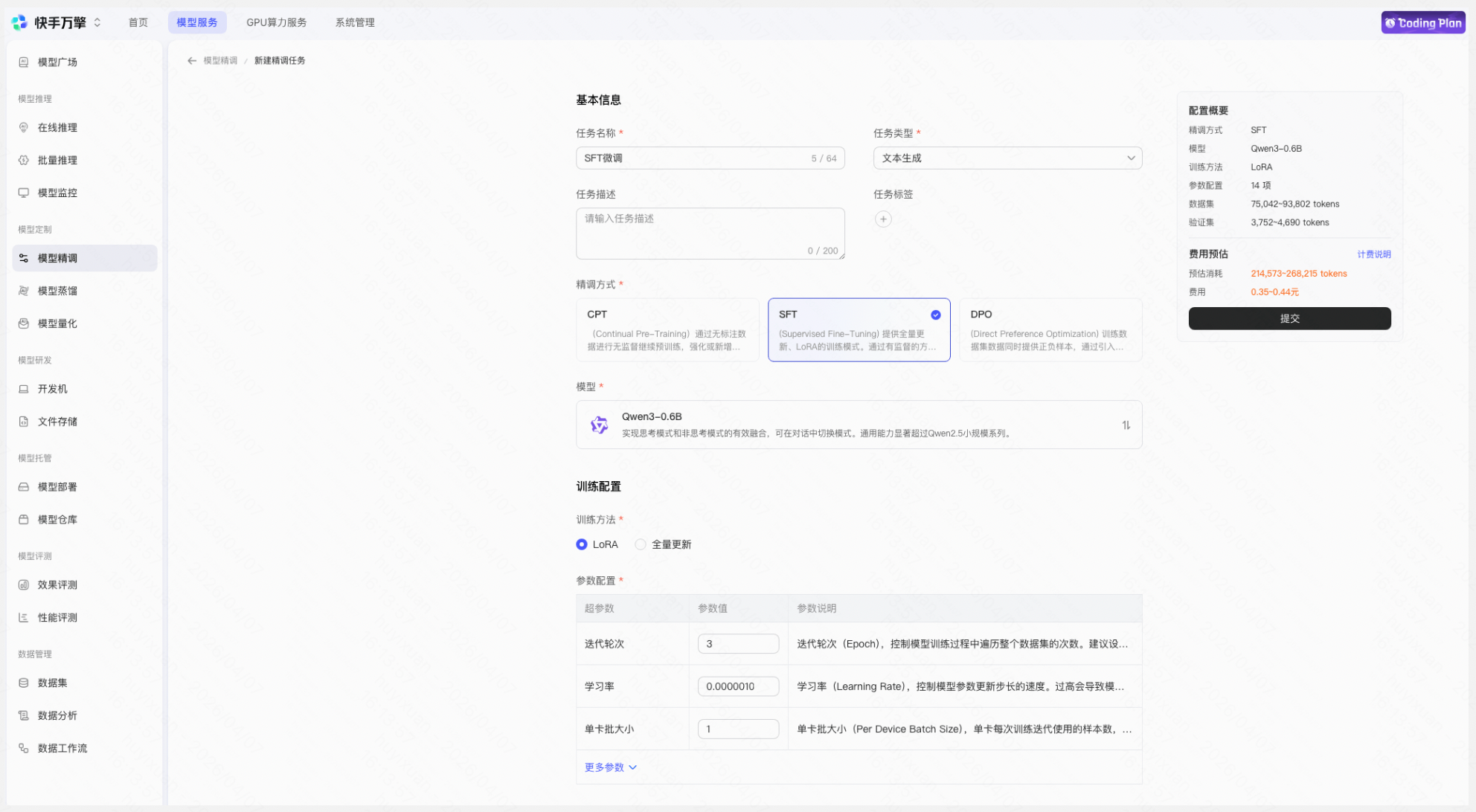
Step 3:创建 SFT 微调任务
1.选择基础模型(如 Qwen 系列对话模型)
2.选择训练方法(推荐先用 LoRA做验证)
3.关联训练数据集
4.配置验证方式(推荐使用数据拆分)
5.设置超参数(可使用平台默认值)
6.提交训练任务
【费用预估:精调配置选择完毕后,页面将展示计费详情。预估条件(精调方式、基础模型、基础模型版本、训练方法、数据集、验证集)均填写后,将展示折合后的具体金额范围;若预估条件不充分,将提示“按token后付费”】
Step 4:监控训练过程
1.实时查看 loss 和 eval_loss 曲线
2.确认 loss 持续下降,表明模型在有效学习
3.查看训练日志,了解训练进度
【⚠️若任务处于排队中状态 ,将无法查看训练日志】
Step 5:发布模型
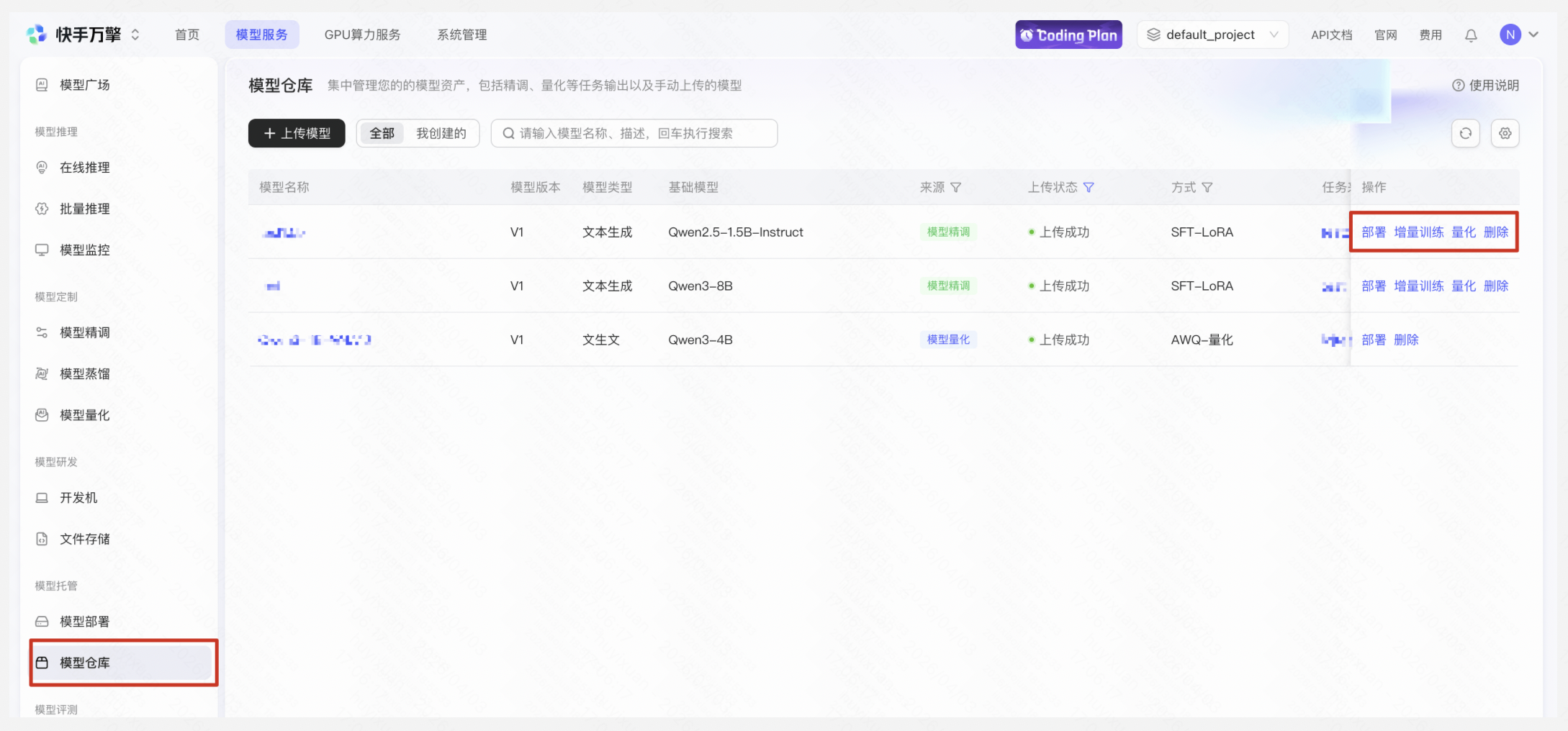
训练完成后,将模型发布为新模型或已有模型的新版本,可在【模型仓库】对已发布模型执行继续增量训练、量化、部署操作。
- 发布为新模型:此次训练的模型发布后使用新的模型名称。
- 已有模型新版本:同系列模型仅更新版本,不更新模型名称。需保持基础模型一致、精调方式一致、任务类型一致、训练方法一致。
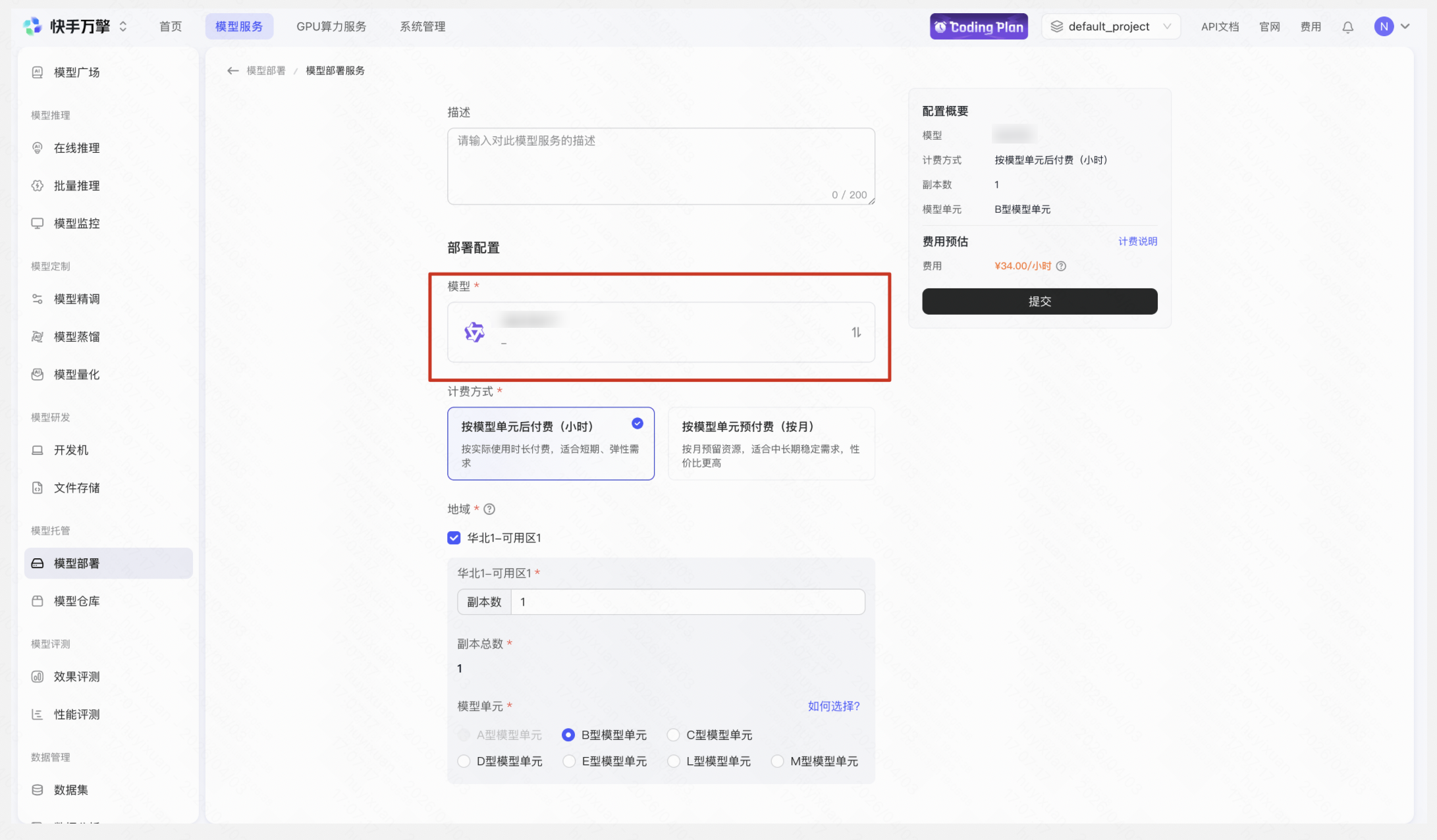
Step 6:模型部署
在【模型仓库】选择已发布的定制模型进行部署,部署流程将会默认选中当前模型,点击提交部署完成后,可进行模型效果评测和性能评测。
Step 7:模型评测
已部署的模型可通过点击评测进入效果评测流程,支持人工评测和自动评测(LLM as a Judge),自动评测可大幅提升评测效率,评测完成后可通过评测详情和评测结果对比模型表现。
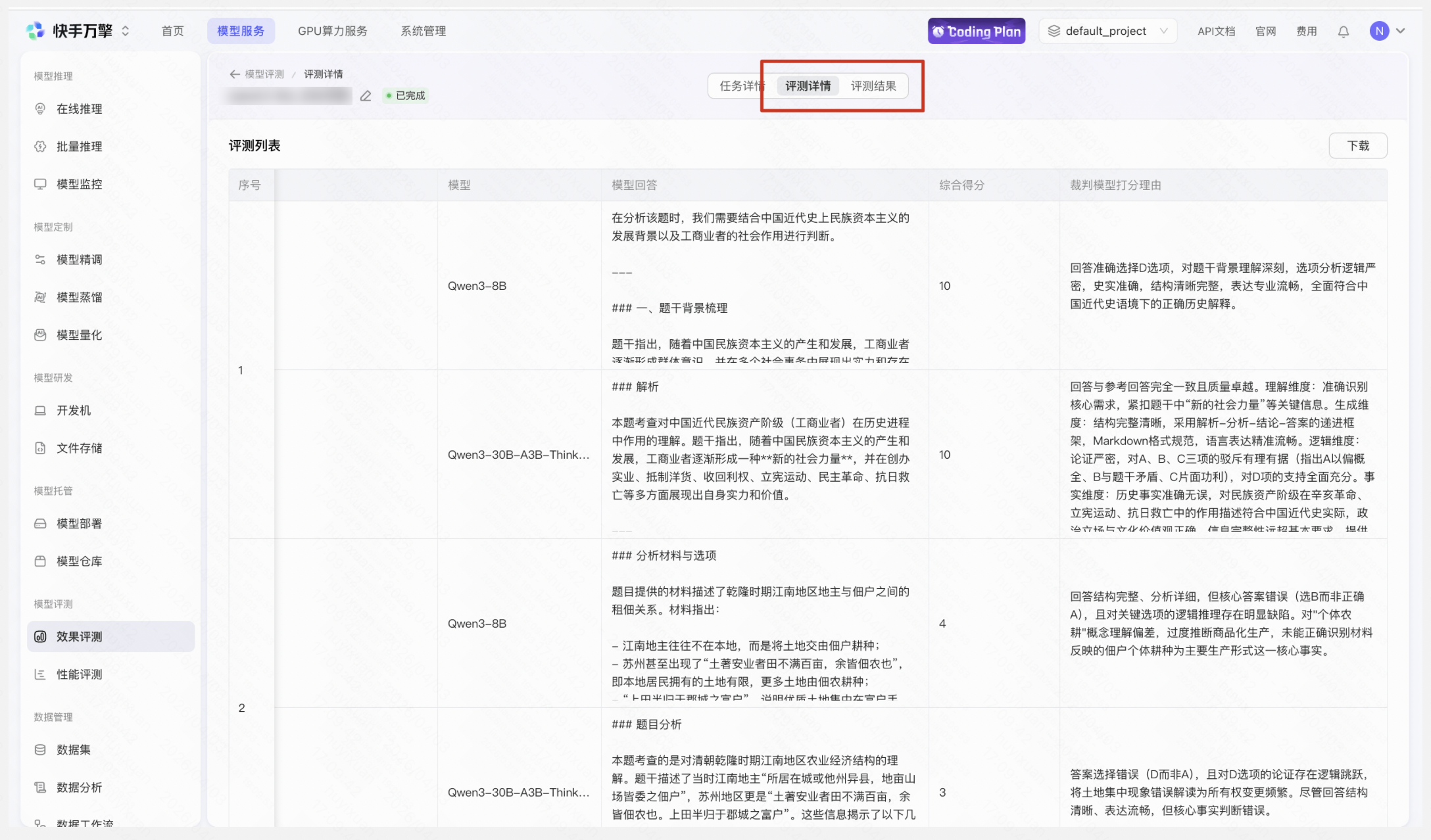
通过模型性能评测能够了解模型在不同压力条件下的推理性能表现,包括延迟、吞吐量、成功率等关键指标,可基于此制定合理的调用策略和限流配置。
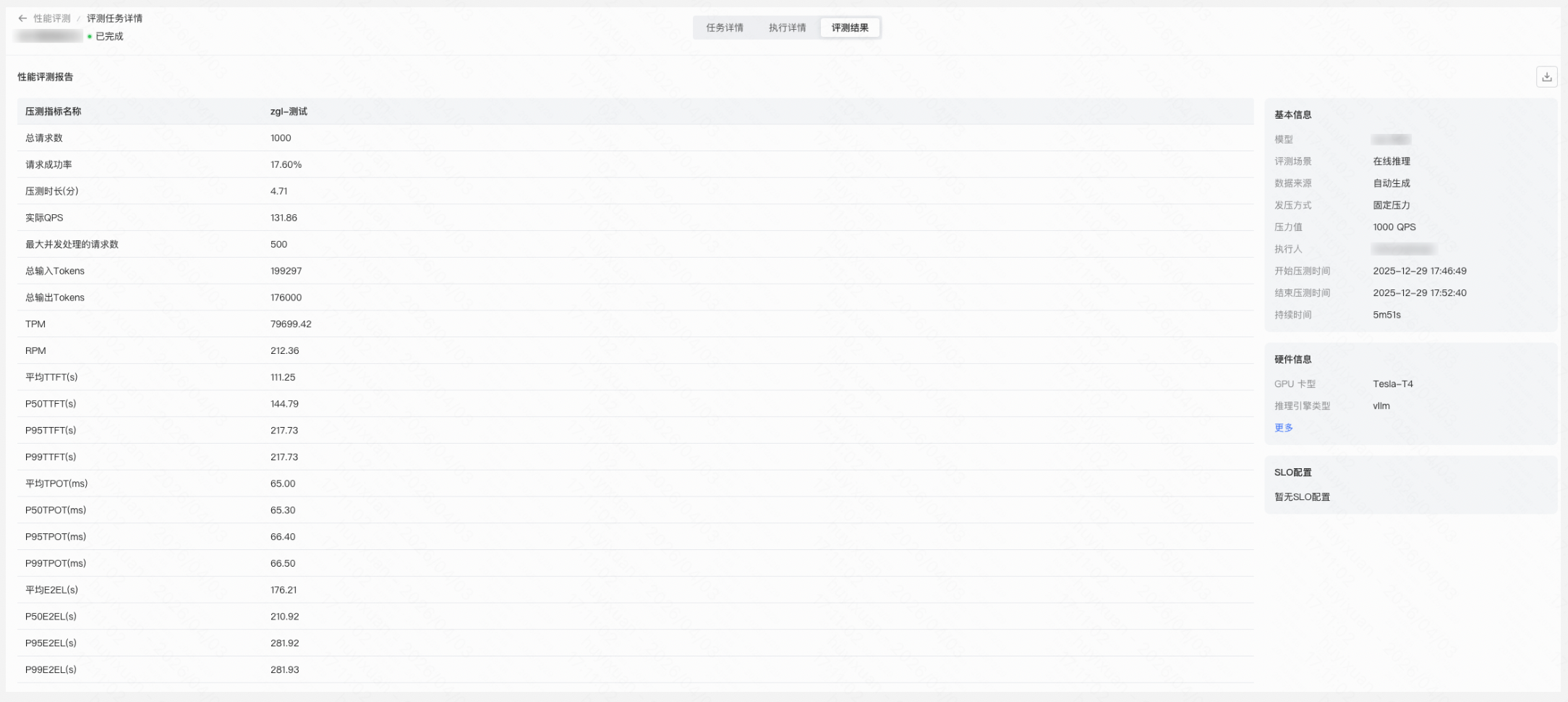
Step 8:创建推理点
在万擎平台创建推理接入点(Endpoint),选择已发布的定制模型进行部署。
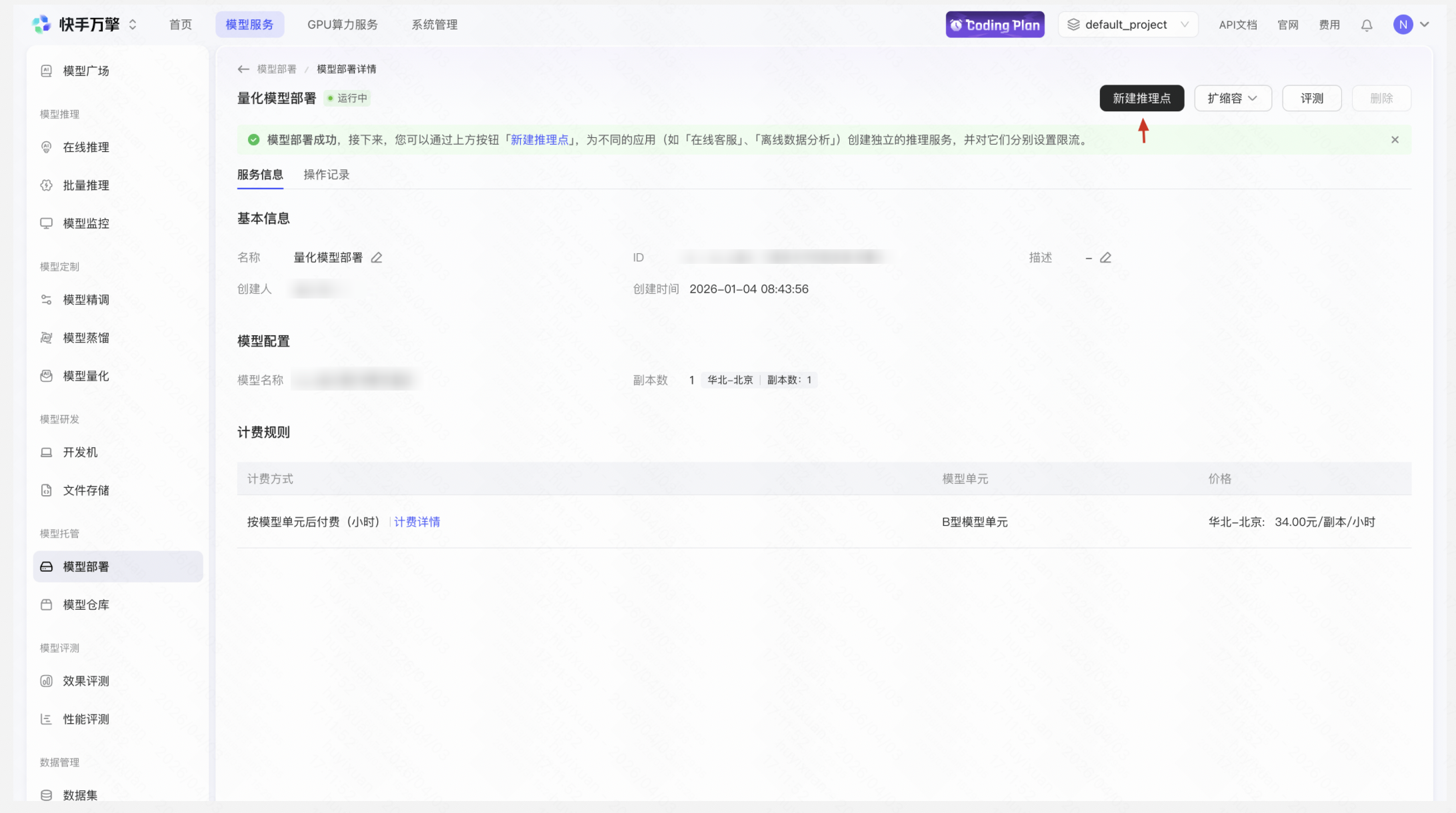
Step 9:接入业务系统
通过 API 将推理接入点对接到企业客服系统,定制模型即可上线服务。
预期效果:产品信息回答准确率和话术规范符合度可显著提升,客户服务体验得到明显改善。具体提升幅度视数据质量和业务场景而定。
2.1.7 场景示例:品牌电商商品图生成模型定制全流程
前置准备
- 权限申请:
- 主账号(即溪流湖账户)拥有账号下所有项目的访问/管理权限,无需权限申请,主账号可对所有任务进行修改、删除;
- 子账号:可由主账号为名下子账号设置某项目的只读/管理权限,子账号不支持删除主账号新建的任务;
- 若账户余额不足,请先充值;
- 确认权限及余额无问题后,在左侧导航栏中「模型定制」下方点击「模型精调」进入产品页面,点击「+新建精调任务」进入创建页面。
背景:某时尚品牌电商平台使用通用文生图模型生成商品展示图,存在以下问题:生成图片的品牌风格不统一(色调/构图/光影风格杂乱)、无法准确还原品牌 VI 视觉规范(Logo 位置、品牌色、背景风格)、模特形象与品牌定位不符。
目标:定制一个掌握品牌视觉风格规范、能稳定生成符合品牌调性的商品展示图的专属文生图模型。
Step 1:准备训练数据
整理品牌历史高质量商品图及对应的 Prompt 描述,制作「图文配对」训练数据,格式示例:
{
"prompt": "一款简约风格的女士手提包,米白色荔枝纹牛皮材质,金色五金件,正面印有品牌LOGO,放置在白色大理石台面上,自然光从左侧45度打光,柔和阴影,浅灰色背景,商业摄影风格,高分辨率,品牌官网商品图风格",
"image": "https://cdn.brand.com/training_data/bag_001.png"
}
建议准备 500-1000 组高质量图文配对数据,覆盖主要商品品类(服装、鞋履、包袋、配饰、美妆等),确保每个品类的样本量均衡。
Step 2:上传数据集
在万擎平台「数据集」模块上传数据文件(包含 Prompt JSON 文件和对应的图片包),平台将自动校验数据格式和图片完整性。
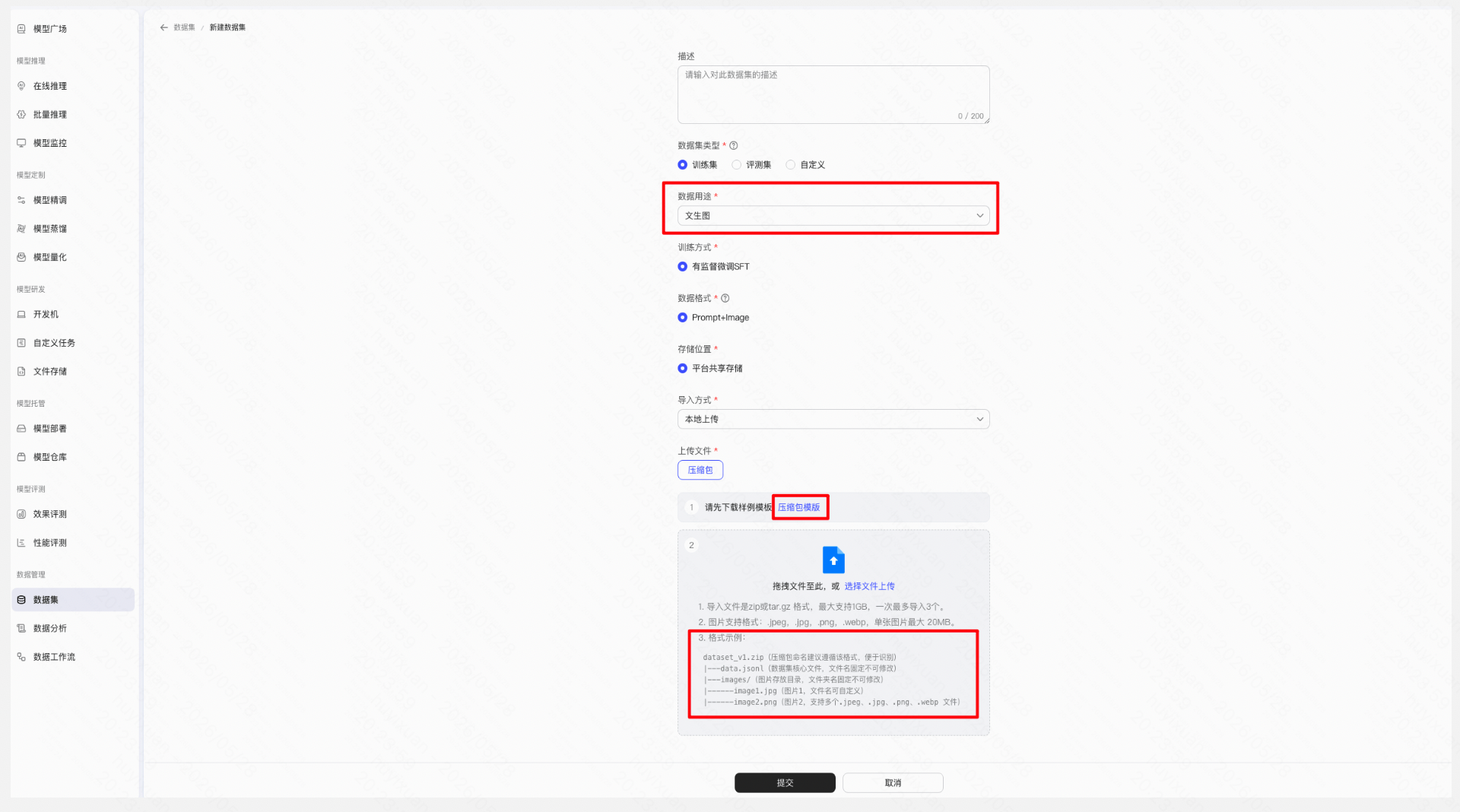
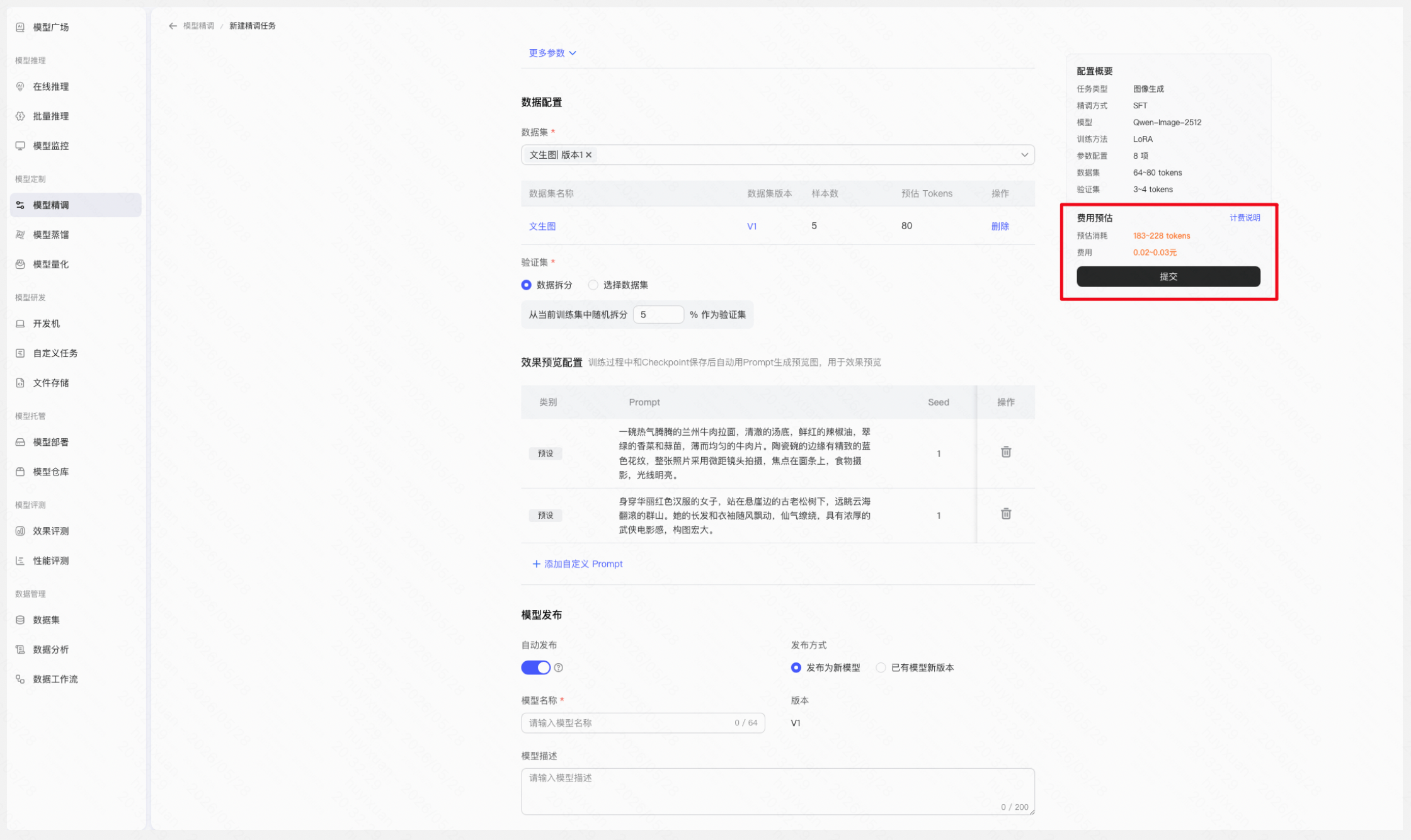
Step 3:创建 SFT 微调任务
1.任务类型选择「图像生成」
2.选择基础生图模型
3选择训练方法(推荐用 LoRA做验证)
4.设置超参数(可使用平台默认值)
5.关联训练数据集
6.配置验证方式(推荐使用数据拆分)
7.填写效果配置
8.提交训练任务
【费用预估:精调配置选择完毕后,页面将展示计费详情。预估条件(精调方式、基础模型、基础模型版本、训练方法、数据集、验证集)均填写后,将展示折合后的具体金额范围;若预估条件不充分,将提示“按token后付费”】
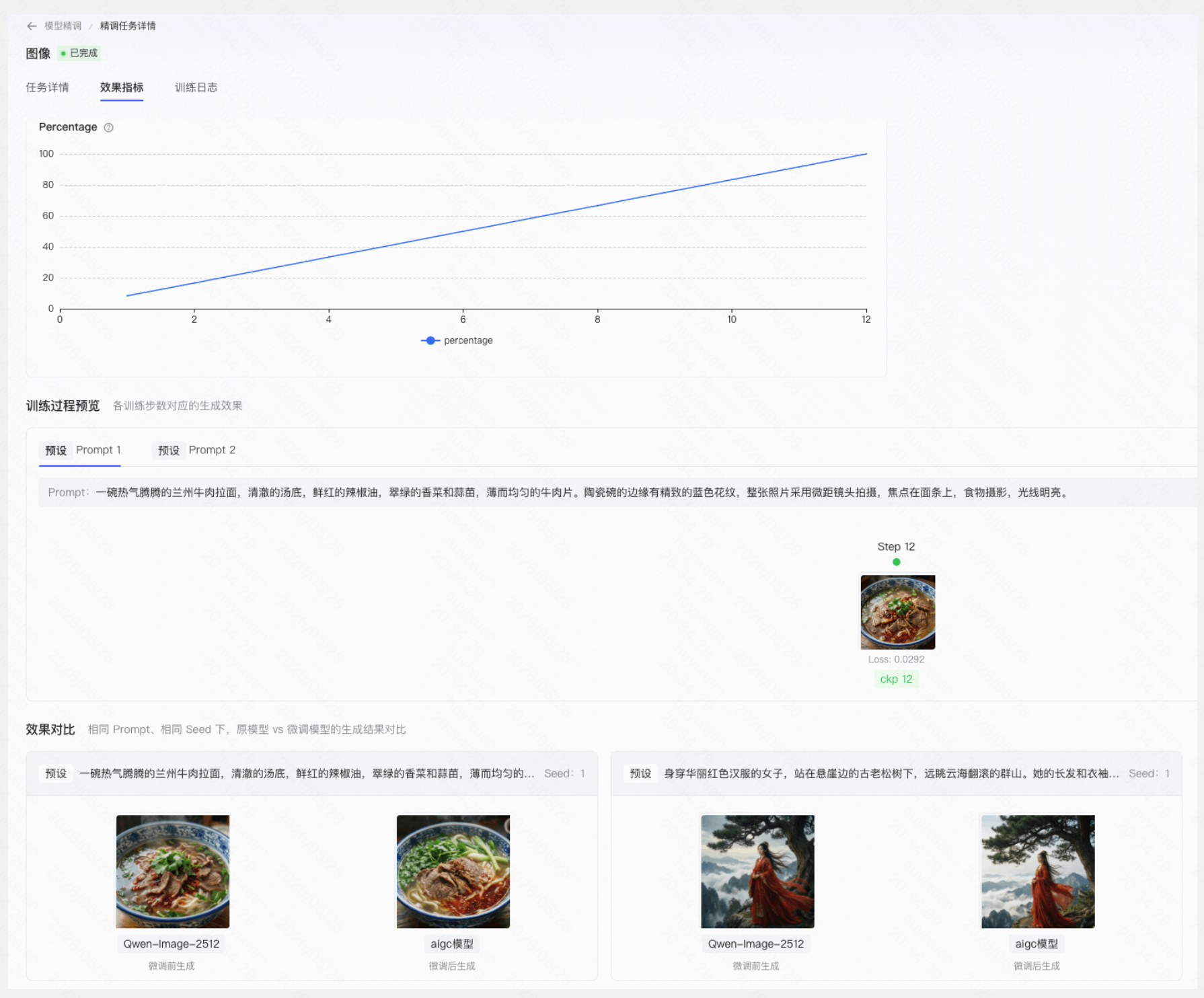
Step 4:监控训练过程
1.实时查看 loss 和 eval_loss 曲线
2.确认 loss 持续下降,表明模型在有效学习
3.效果指标中可查看训练过程中生成的生成效果以及微调前后的效果对比
4.查看训练日志,了解训练进度
【⚠️若任务处于排队中状态 ,将无法查看训练日志】
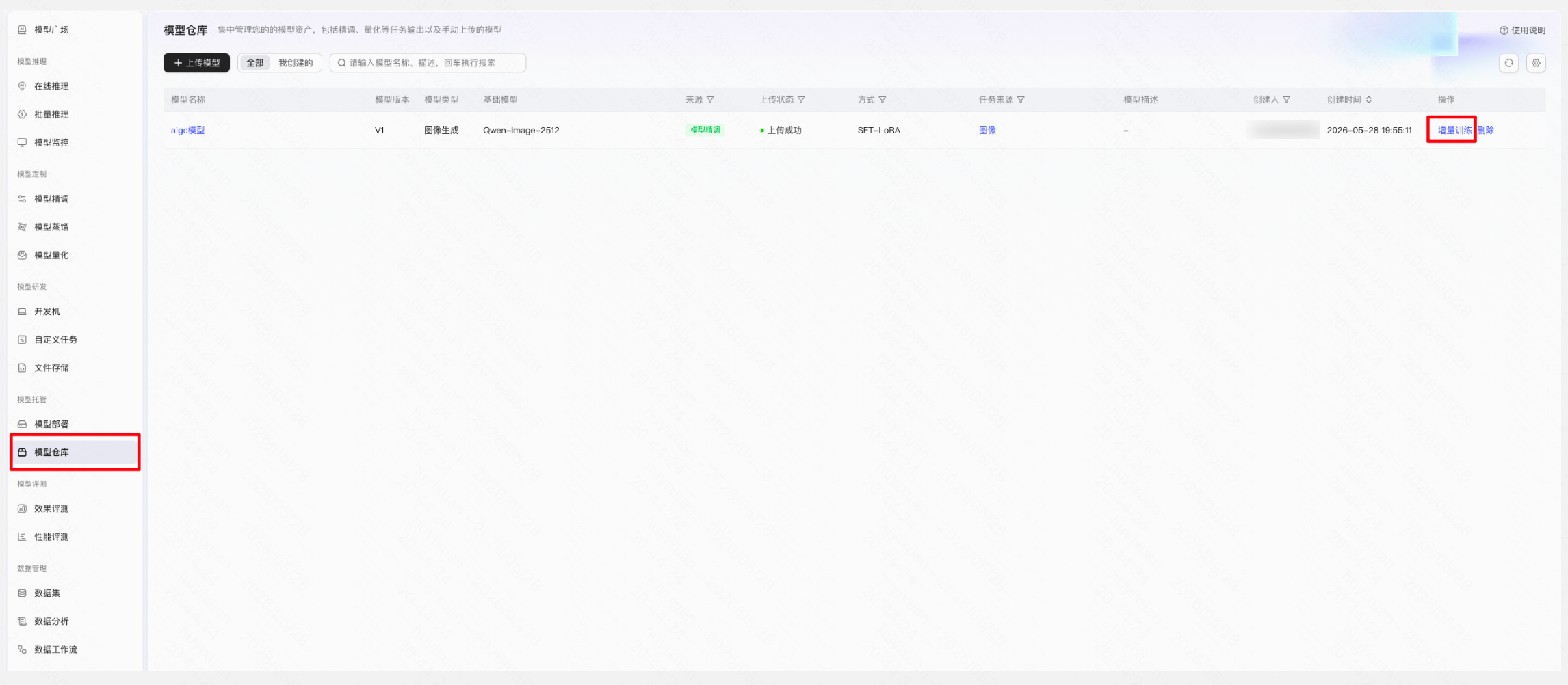
Step 5:发布模型
训练完成后,将模型发布为新模型或已有模型的新版本,可在【模型仓库】对已发布模型执行继续增量训练。
- 发布为新模型:此次训练的模型发布后使用新的模型名称。
- 已有模型新版本:同系列模型仅更新版本,不更新模型名称。需保持基础模型一致、精调方式一致、任务类型一致、训练方法一致。
2.2 DPO(直接偏好优化)
2.2.1 什么是 DPO
DPO(Direct Preference Optimization,直接偏好优化):是一种通过正负样本对比来优化模型输出质量的训练方法。与 SFT 教模型「如何回答」不同,DPO 教模型「什么样的回答更好」——通过学习大量「优质回答 vs 低质回答」的对比数据,使模型倾向于生成更高质量的输出。
与 SFT 的区别和互补关系
精调方式并不互斥,而是递进的、相辅相成的。在通过SFT完成特定业务场景适配后,可再通过DPO进行偏好的对齐,提升输出质量。
维度 | SFT | DPO |
训练目标 | 使模型掌握特定领域的回答能力 | 使模型学会区分输出质量的优劣 |
数据格式 | 问题 + 标准答案 | 问题 + 优质回答 + 低质回答 |
适合阶段 | 先做 SFT 建立基础能力 | 再做 DPO 提升输出质量 |
SFT + DPO 组合使用效果最佳:先用 SFT 注入领域知识,再用 DPO 优化输出质量。
2.2.2 DPO 的核心价值
- 偏好对齐:使模型输出更符合人类期望和业务标准
- 质量提升:在多种可能的回答中,引导模型选择质量更高的回答
- 流程简化:相比传统 RLHF 方法,DPO 无需训练额外的奖励模型,实现成本更低
2.2.3 典型应用场景
- 场景 1:减少幻觉
- 痛点:模型有时会生成不准确或编造的信息
- 方案:收集「事实准确的回答」vs「包含编造信息的回答」进行 DPO 训练
- 效果:模型在不确定时更倾向于如实表达,减少幻觉输出
- 场景 2:安全对齐
- 痛点:模型可能生成不当或有害内容
- 方案:收集「安全回答」vs「不当回答」进行 DPO 训练
- 效果:模型学会识别和拒绝不当请求,提升安全性
- 场景 3:输出质量提升
- 痛点:模型回答质量参差不齐
- 方案:收集高质量和低质量回答的对比数据进行 DPO 训练
- 效果:模型输出的平均质量显著提升,回答更准确、更有条理
2.2.4 核心能力
1)数据格式:正负样本对
DPO 的训练数据由三元组构成:一个问题 + 一个优质回答(chosen)+ 一个低质回答(rejected)。
{
"prompt": "请介绍一下你们的退货政策",
"chosen": "我们支持7天无理由退货。收到商品后7天内,保持商品完好即可申请退货,运费由我们承担。退款会在收到退货后3个工作日内原路退回。",
"rejected": "可以退的,你去找客服吧。"
}
2)其他能力参考SFT
2.2.5 效果指标
【⚠️若任务处于排队中状态 ,将无法查看效果指标】
除SFT部分基础指标外,DPO任务还包含以下指标:
指标 | 含义 | 判读方式 |
rewards accuracies(奖励准确率) | 模型正确区分优质回答和低质回答的比例 | 越高越好,接近 1.0 表示模型已能有效区分 |
rewards margins(奖励差距) | 模型对优质回答和低质回答的评分差距 | 越大越好,表示区分能力越强 |
rewards chosen(优质回答奖励值) | 模型对优质回答的评分 | 应为正值且逐步提高 |
rewards rejected(低质回答奖励值) | 模型对低质回答的评分 | 应为负值且逐步降低 |
logps chosen(优质回答对数概率) | 模型生成优质回答的概率 | 应逐步提高 |
logps rejected(低质回答对数概率) | 模型生成低质回答的概率 | 应逐步降低 |
简要判断标准:rewards accuracies 持续上升且趋近 1.0,rewards margins 持续扩大,即表示训练效果良好。
2.2.6 场景示例:内容平台 AI 写作助手质量优化
前置准备
- 权限申请:
- 主账号(即溪流湖账户)拥有账号下所有项目的访问/管理权限,无需权限申请,主账号可对所有任务进行修改、删除;
- 子账号:可由主账号为名下子账号设置某项目的只读/管理权限,子账号不支持删除主账号新建的任务;
- 若账户余额不足,请先充值;
- 确认权限及余额无问题后,在左侧导航栏中「模型定制」下方点击「模型精调」进入产品页面,点击「+新建精调任务」进入创建页面。
背景:某内容平台已通过 SFT 训练了一个写作助手,能生成文章,但输出质量不稳定——有时内容优质,有时存在冗余表达或事实错误。
目标:提升写作助手的输出质量稳定性,使其更符合平台内容标准。
Step 1:收集偏好对比数据
由内容审核团队对 AI 生成的文章进行评判,收集优质内容和低质内容的对比数据:
{
"prompt": "写一段关于春季护肤的建议",
"chosen": "春季气温回升,皮肤容易出现干燥脱皮。建议:1)将冬季厚重面霜换成清爽乳液;2)加强防晒,春季紫外线已经较强;3)每周做1-2次补水面膜。注意观察肌肤状态,及时调整护肤方案。",
"rejected": "春天来了,大家要注意护肤哦。护肤很重要的,可以用一些护肤品,比如面霜啊、乳液啊什么的。总之要好好爱护自己的皮肤。"
}
建议准备 500-1000 条偏好对比数据。
Step 2:上传偏好数据集
将整理好的正负样本对数据上传至万擎平台。
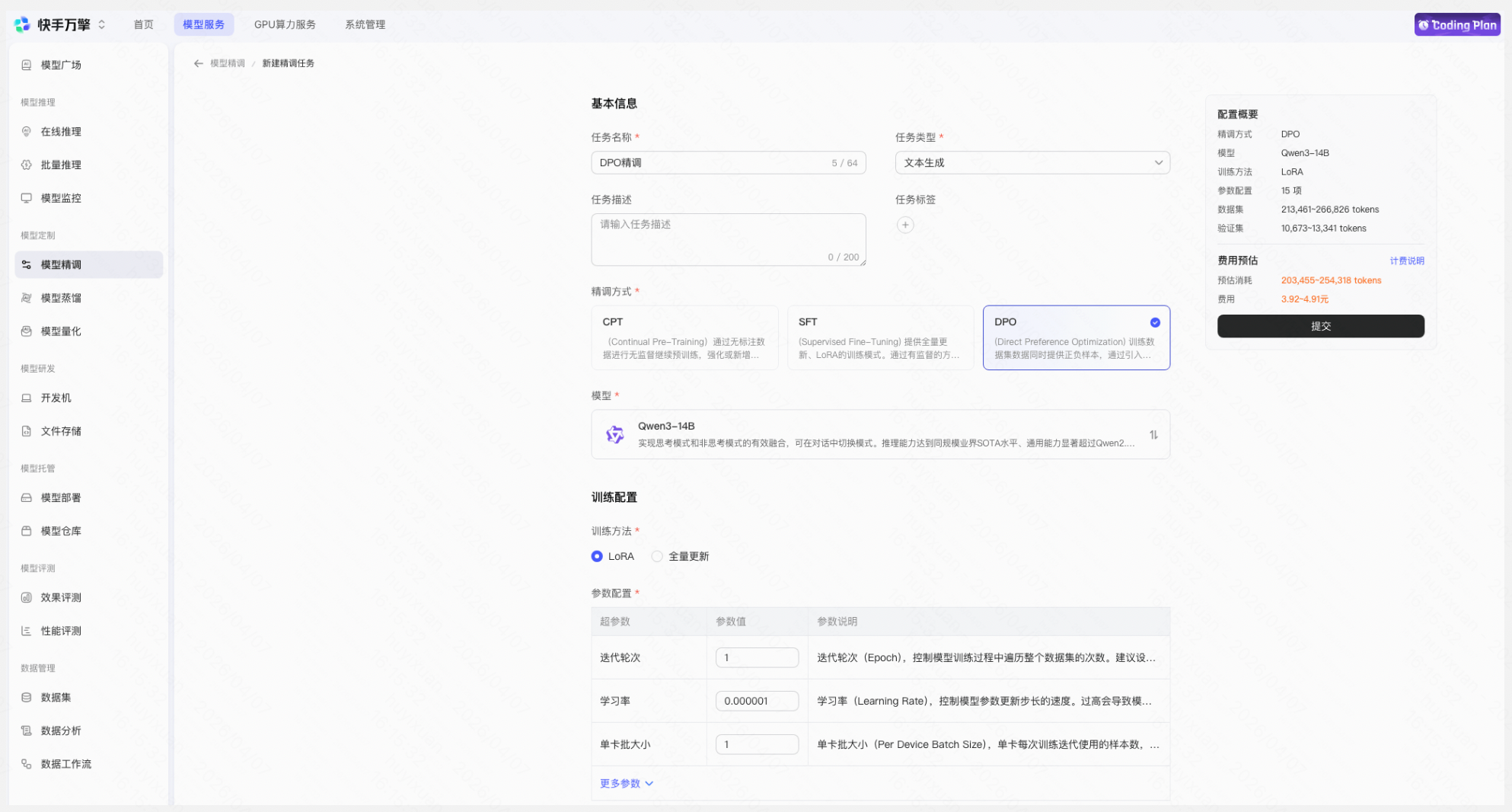
Step 3:创建 DPO 训练任务
- 选择基础模型(推荐使用已完成 SFT 的模型,也可直接使用预置模型)
- 关联偏好数据集
- 配置训练参数
- 提交训练任务
【费用预估:精调配置选择完毕后,页面将展示计费详情。预估条件(精调方式、基础模型、基础模型版本、训练方法、数据集、验证集)均填写后,将展示折合后的具体金额范围;若预估条件不充分,将提示“按token后付费”】
Step 4:查看效果指标
- 关注 rewards accuracies 是否持续上升
- 关注 rewards margins 是否持续扩大
- 确认模型逐步学会区分输出质量
【⚠️若任务处于排队中状态 ,将无法查看训练日志】
Step 5:发布模型
训练完成后,将模型发布为新模型或已有模型的新版本,可在【模型仓库】对已发布模型执行继续增量训练、量化、部署操作。
- 发布为新模型:此次训练的模型发布后使用新的模型名称。
- 已有模型新版本:同系列模型仅更新版本,不更新模型名称。需保持基础模型一致、精调方式一致、任务类型一致、训练方法一致。
Step 6:模型部署
在【模型仓库】选择已发布的定制模型进行部署,部署流程将会默认选中当前模型,点击提交部署完成后,可进行模型效果评测和性能评测。
Step 7:模型评测
已部署的模型可在列表页通过点击评测进入效果评测流程,支持人工评测和自动评测,自动评测可大幅提升评测效率,评测完成后可通过评测详情和评测结果对比模型表现。
您也可以创建性能评测任务检验模型在不同压力条件下的推理性能表现,包括延迟、吞吐量、成功率等关键指标,可基于此制定合理的调用策略和限流配置。
Step 8:创建推理点并上线
在万擎平台创建推理接入点(Endpoint),选择已发布的定制模型创建推理接入点并上线。
预期效果:模型输出的内容质量稳定性可显著提升,冗余表达减少,事实准确性增强。具体提升幅度视数据质量和业务场景而定。
2.3 CPT(继续预训练)
2.3.1 什么是 CPT
CPT(Continual Pre-Training,继续预训练):通过在特定领域的大规模无标注数据上进行持续训练,使模型强化或新增特定能力。与预训练阶段学习通用知识不同,CPT 专注于在已有基础模型上注入特定领域的知识。
与 SFT 的区别和互补关系
可先通过 CPT 注入领域知识,再用 SFT 完成特定任务的对齐,两者配合使用效果最佳。
维度 | CPT | SFT |
训练目标 | 使模型强化或新增特定领域知识 | 使模型掌握特定任务的回答能力 |
数据格式 | 无标注文本数据 | 问题 + 标准答案(标注数据) |
数据需求 | 大规模领域语料 | 少量高质量标注数据 |
适合阶段 | 前置阶段,注入领域知识 | 后置阶段,完成任务级对齐 |
典型训练流程:CPT → SFT → DPO
2.3.2 CPT 的核心价值
- 领域知识注入:通过大规模领域语料,使模型快速掌握特定领域的知识、术语和表达方式
- 能力增强:针对特定能力(如代码、数学、创意写作等)进行强化训练
- 知识更新:基于新知识或最新数据对模型进行更新,保持知识的时效性
- 成本效益:无需人工标注,利用海量无标注数据即可实现领域适配
2.3.3 典型应用场景
- 场景 1:领域知识增强
- 痛点:通用大模型在特定垂直领域(医疗、法律、金融、教育等)专业知识不足
- 方案:收集该领域的大规模专业文档、教材、论文、规范等无标注数据进行 CPT
- 效果:模型在领域内的专业知识深度显著提升,能够理解和生成更专业的内容
- 场景 2:企业私有知识注入
- 痛点:模型不了解企业内部知识(产品资料、技术文档、业务流程等),回答泛化、不贴合实际
- 方案:将企业内部文档、知识库、FAQ 等无标注数据进行清洗后用于继续预训练
- 效果:模型具备企业语境理解能力,回答更贴合实际业务,减少“查不到就不会答”的情况
- 场景 3:垂直内容风格学习
- 痛点:模型生成内容风格偏通用,不符合特定平台或场景(如种草文案、公文写作等)
- 方案:收集目标风格的大规模文本数据(如社区内容、历史文案等)进行训练
- 效果:模型语言风格更贴近目标场景,生成内容更自然、更具一致性
- 场景 4:知识时效性更新
- 痛点:模型知识截止于训练数据时间点,无法获取最新信息
- 方案:收集最新数据(新闻、论文、报告等)进行 CPT 训练
- 效果:模型能够掌握最新的领域动态和知识
2.3.4 核心能力
1)数据格式:无标注文本
CPT 的训练数据为无标注的纯文本,一行训练数据展开后结构如下::
{"text":"文本内容"}
数据量建议:
建议至少准备5千万token优质预训练数据,数据规模越大,越有可能获得更好的训练效果。但CPT所需的数据量受到多个因素的影响,包括任务的复杂性、领域的专业性、模型的规模等,因此在实际应用中,可以根据模型的表现调整数据规模。
2)混合语料:CPT方式下,用户可选择使用自身数据与通用语料数据做混合训练,从而有效降低模型幻觉问题,其中通用语料数据由万擎平台提供,根据混合比例将增加对应token数,同时计费也会增长。
3)其他能力参考SFT
2.3.5 效果指标
【⚠️若任务处于排队中状态 ,将无法查看效果指标】
除SFT部分基础指标外,CPT任务还包含以下指标:
指标 | 含义 | 判读方式 |
grad_norm(梯度范数) | 模型参数梯度的整体大小,用于反映训练过程中的更新幅度 | 应保持在合理范围内稳定波动;过大可能导致训练不稳定(梯度爆炸),过小可能导致学习缓慢或停滞(梯度消失) |
2.3.6 场景示例:内容平台领域知识增强
前置准备
- 权限申请:
- 主账号(即溪流湖账户)拥有账号下所有项目的访问/管理权限,无需权限申请,主账号可对所有任务进行修改、删除;
- 子账号:可由主账号为名下子账号设置某项目的只读/管理权限,子账号不支持删除主账号新建的任务;
- 若账户余额不足,请先充值;
- 确认权限及余额无问题后,在左侧导航栏中「模型定制」下方点击「模型精调」进入产品页面,点击「+新建精调任务」进入创建页面。
背景:某内容平台的通用大模型在内容创作场景中专业深度不足,无法准确理解和生成专业领域内容。
目标:通过 CPT 强化模型在内容创作领域的知识储备,使其能够生成更专业、更有深度的内容。
Step 1:收集领域语料
收集内容创作领域的专业数据:
建议准备中等规模及以上大小的领域语料,确保覆盖各类内容创作场景。
Step 2:上传领域数据集
将整理好的无标注文本数据上传至万擎平台。
Step 3:创建 CPT 训练任务
- 选择基础模型(推荐使用预置模型或已完成通用训练的模型)
- 配置训练参数(建议适当的学习率和训练轮数)
- 关联领域语料数据集
- 提交训练任务
【费用预估:精调配置选择完毕后,页面将展示计费详情。预估条件(精调方式、基础模型、基础模型版本、训练方法、数据集、验证集)均填写后,将展示折合后的具体金额范围;若预估条件不充分,将提示按token后付费】
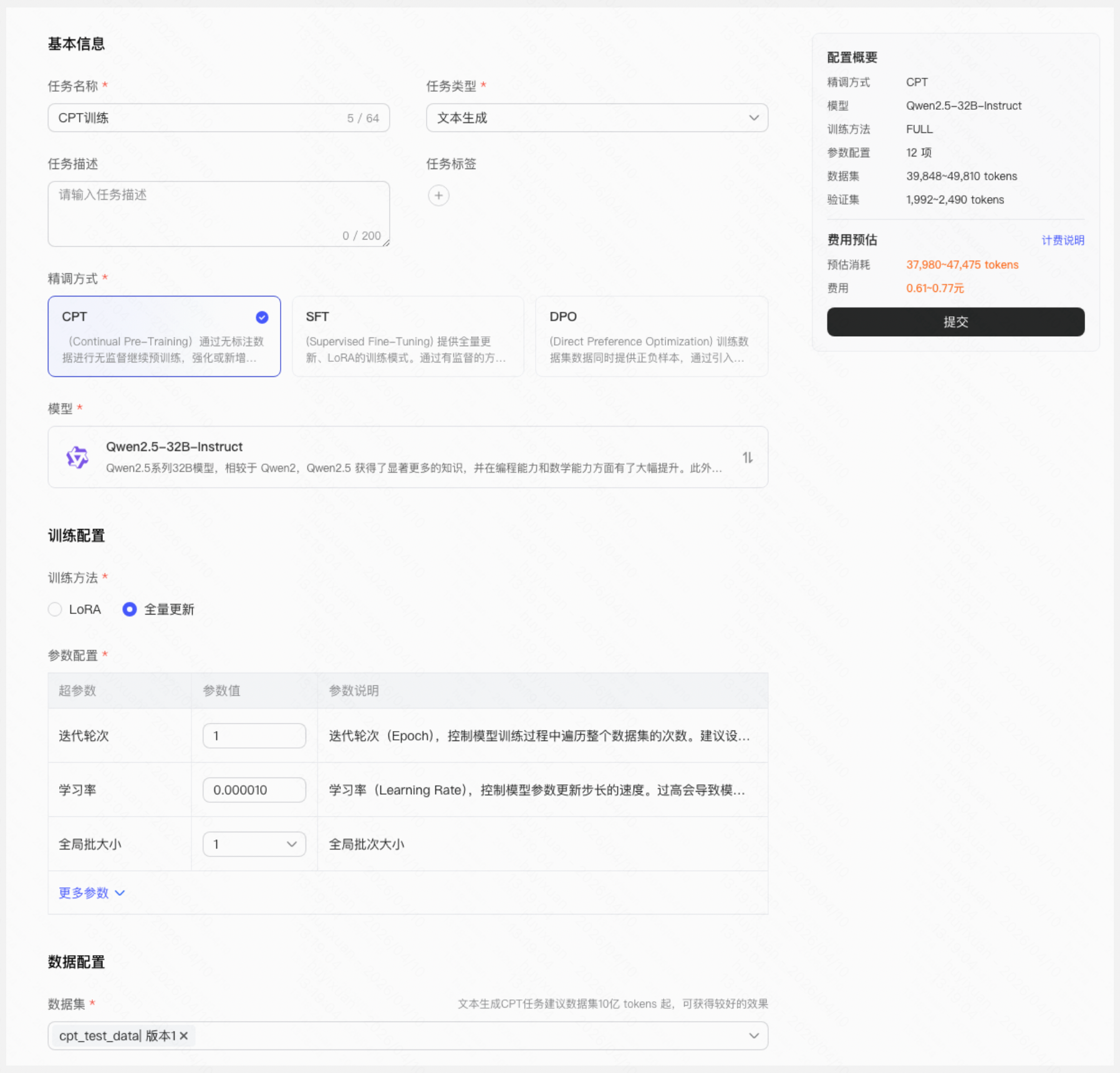
Step 4:查看效果指标
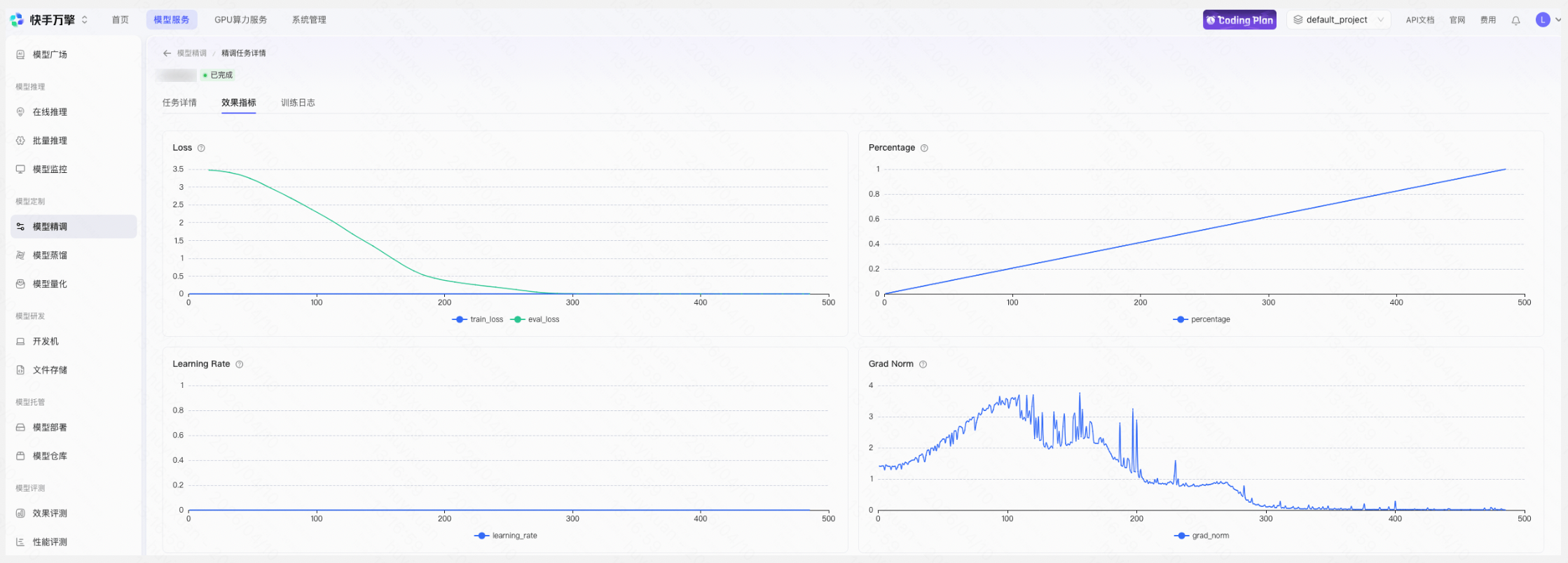
- 实时查看 loss 和 eval_loss 曲线,确认 loss 持续下降,表明模型在有效学习
- 关注 grad_norm,确认梯度范数保持稳定波动,无梯度爆炸或梯度消失的情况。
- 查看训练日志,了解训练进度
【⚠️若任务处于排队中状态 ,将无法查看训练日志】
Step 5:发布模型
训练完成后,将模型发布为新模型或已有模型的新版本,可在【模型仓库】对已发布模型执行继续增量训练、量化、部署操作。
- 发布为新模型:此次训练的模型发布后使用新的模型名称。
- 已有模型新版本:同系列模型仅更新版本,不更新模型名称。需保持基础模型一致、精调方式一致、任务类型一致、训练方法一致。
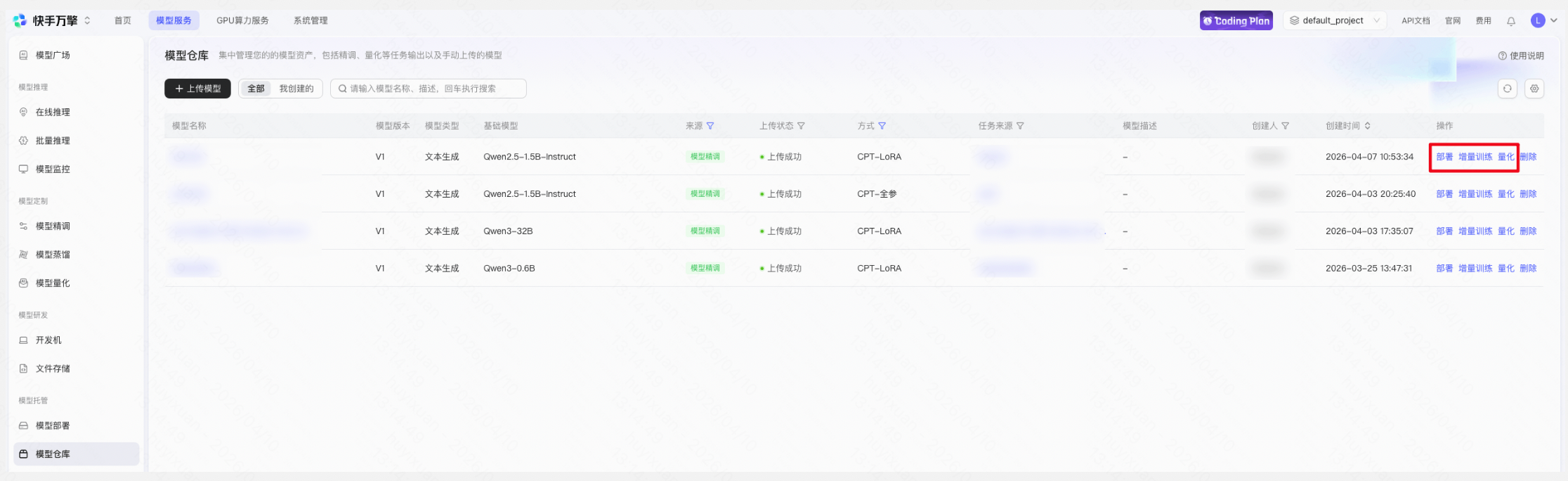
Step 6:模型部署
在【模型仓库】选择已发布的定制模型进行部署,部署流程将会默认选中当前模型,点击提交部署完成后,可进行模型效果评测和性能评测。
Step 7:模型评测
已部署的模型可在列表页通过点击评测进入效果评测流程,支持人工评测和自动评测,自动评测可大幅提升评测效率,评测完成后可通过评测详情和评测结果对比模型表现。
您也可以创建性能评测任务检验模型在不同压力条件下的推理性能表现,包括延迟、吞吐量、成功率等关键指标,可基于此制定合理的调用策略和限流配置。
Step 8:创建推理点并上线
在万擎平台创建推理接入点(Endpoint),选择已发布的定制模型创建推理接入点并上线。
预期效果:模型在内容创作领域的专业知识深度显著提升,能够准确理解领域概念,生成更专业、更有深度的内容。具体提升幅度视数据质量和业务场景而定。
后续可结合 SFT + DPO:完成 CPT 领域知识注入后,可继续通过 SFT 进行任务对齐,再通过 DPO 优化输出质量,形成完整的训练流程。
附录
精调任务训练配置-参数配置详情:
超参数 | 参数说明 |
迭代轮次 | 迭代轮次(Epoch),控制模型训练过程中遍历整个数据集的次数。建议设置在1-5之间,小数据集可增大Epoch以促进模型收敛。 |
学习率 | 学习率(Learning Rate),控制模型参数更新步长的速度。过高会导致模型难以收敛,过低则会导致模型收敛速度过慢,平台已给出默认推荐值,可根据经验调整。 |
单卡批大小 | 单卡批大小(Per Device Batch Size),单卡每次训练迭代使用的样本数,为了加快训练效率。全局批大小 = 单卡批大小 * 卡数 |
序列长度 | 序列长度(Sequence Length),单条数据的最大长度,包括输入和输出。超过该长度的数据在训练将被自动截断,单位为token。如果数据集中的文本普遍较短,建议选择较短的序列长度以提高计算效率。 |
预热比例 | 预热比例(Learning Rate Warmup),训练初期学习率预热步数占用总的训练步数的比例。学习率预热可以提高模型稳定性和收敛速度。 |
LoRA Ranks | LoRA 策略中的秩(LoRA Rank),决定了微调过程中引入的低秩矩阵的复杂度。较小的秩可以减少参数数量,降低过拟合风险,但可能不足以捕捉任务所需的所有特征;较大的秩可能增强模型的表示能力,但会增加计算和存储负担。 |
LoRA Alpha | LoRA微调中的缩放系数(LoRA Alpha),定义了LoRA适应的学习率缩放因子。该参数过高,可能会导致模型的微调过度,失去原始模型的能力;改参数过低,可能达不到预期的微调效果。 |
LoRA Dropout | LoRA微调中的Dropout系数(LoRA Dropout),用于防止lora训练中的过拟合。 |
学习率调整计划 | 学习率调整计划(Scheduler Type),用于在训练过程中动态调整学习率,以优化模型的收敛速度和性能。根据模型的训练情况和任务需求,选择合适的学习率调整方式。 |
正则化系数 | 正则化系数(Weight Decay),控制正则化项对模型参数的影响强度。适当增大系数可以增强正则化效果,防止过拟合,但过高的系数可能导致模型欠拟合。 |
验证步数 | 验证步数(Validation Steps),计算验证集Loss的间隔步数;为0时不开启验证,没有相关指标。 |
Checkpoint保存间隔数 | Checkpoint保存间隔数(Checkpoint Interval),训练过程中保存Checkpoint的间隔Step数。间隔太短可能导致频繁的Checkpoint操作增加训练时长,间隔太长则可能在故障时丢失更多的数据。 |
Packing | 数据拼接(Packing),将多条训练样本拼接到一个seqLen长度内。 |
DPO偏好损失类型 | DPO中偏好损失类型(Loss Type),可选择的类型包括sigmoid、ipo、kto_pair。sigmoid适用于一般情况,提供稳定训练过程,ipo可以纠正模型过度自信的问题,kto可以使模型更符合用户偏好。 |
beta | 温度超参(Beta),温度超参beta用于控制模型输出分布的集中程度。较高的beta值会使输出更具确定性,而较低的beta值则使输出更具多样性。 |