
模型量化
一、什么是模型量化
模型量化是一种模型压缩技术,通过降低模型参数的数值精度(如从 16bit 降至 8bit 或 4bit),在保持模型效果基本不变的前提下,大幅减少模型体积和计算资源需求,将模型中连续、高精度的数值(通常是32位浮点数)转换为离散、低精度的数值(如8位整数),从而大幅减少模型对存储和计算资源的需求,并提升推理速度。平台当前支持支持 AWQ 和 GPTQ 两种主流的训练后量化方法,使您能在保持模型核心能力的前提下,实现高效的模型部署。
体验链接:模型量化
二、核心价值
价值 | 说明 |
显存节省 | 模型体积显著缩小,GPU 显存占用大幅降低 |
推理加速 | 计算量减少,推理响应速度提升 |
精度保持 | 经过优化的量化方案,精度损失很小 |
成本降低 | 所需 GPU 资源更少,硬件和云服务成本相应降低 |
三、 典型应用场景
- 场景 1:成本敏感型部署
- 痛点:中小企业 AI 预算有限,大模型推理成本过高
- 方案:使用 AWQ 量化将模型压缩至 4bit,大幅降低 GPU 需求
- 效果:同等预算可服务更多用户,或以更少预算达到同等效果
- 场景 2:有限显存环境部署
- 痛点:部署环境 GPU 显存有限
- 方案:量化后的模型可在更小显存的 GPU 上运行
- 效果:降低硬件配置要求,扩大可部署环境范围
- 场景 3:高并发推理
- 痛点:业务高峰期需处理大量并发请求
- 方案:量化后模型单卡占用更少,同一 GPU 可部署更多推理实例
- 效果:系统吞吐量显著提升,高峰期响应能力增强
四、核心能力
万擎支持两种量化方式:
对比维度 | AWQ(W4A16) | GPTQ(Wfp8Afp8) |
权重精度 | 4bit 整数 | fp8 浮点 |
激活精度 | 16bit 浮点 | fp8 浮点 |
压缩比 | 较高(约 4 倍压缩) | 适中(约 2 倍压缩) |
显存节省 | 非常显著 | 显著 |
精度保持 | 略有损失,大部分场景可接受 | 精度保持更好 |
适用场景 | 成本敏感、显存有限 | 精度敏感、质量优先 |
选择建议:
- 追求极致成本优化、显存紧张 → 选择 AWQ
- 追求精度优先、不希望损失效果 → 选择 GPTQ
支持模型
- 预置模型:万擎平台内置的公开模型
- 定制模型:通过 SFT、DPO、蒸馏等方式产生的定制模型
【⚠️注意:当前不支持用户自主上传外部模型后进行量化。】
五、场景示例
前置准备
- 权限申请:
- 主账号(即溪流湖账户)拥有账号下所有项目的访问/管理权限,无需权限申请,主账号可对所有任务进行修改、删除;
- 子账号:可由主账号为名下子账号设置某项目的只读/管理权限,子账号不支持删除主账号新建的任务;
- 若账户余额不足,请先充值;
- 确认权限及余额无问题后,在左侧导航栏中「模型定制」下方点击「模型量化」进入产品页面,点击「+新建量化任务」进入创建页面。
背景:某企业使用 70B 参数大模型构建内部知识问答系统,效果良好但 GPU 成本较高。
目标:在尽量保持效果的前提下,降低部署和推理成本。
Step 1:选择要量化的模型
在万擎平台模型列表中,选择当前使用的 32B 模型。
Step 2:选择量化方式
- 追求最大成本节省 → 选择 AWQ(4bit),相同QPS情况下,TTFT略慢于基础模型1%~3%,TPOT快50%
- 追求最小精度损失 → 选择 GPTQ(fp8),相同QPS情况下,TTFT快20%,TPOT快30%
Step 3:创建量化任务
- 填写任务名称、描述;
- 选择需进行量化的模型,当前支持平台预置模型及用户微调后模型,暂不支持上传模型;
- 选择量化方式,量化位宽将根据您选择的量化方式自动填充;
- 选择数据集,若量化来源为微调后的模型,则默认填充微调的数据集,您可选择切换为其他数据集;
- 选择发布方式并完成基础信息填写。
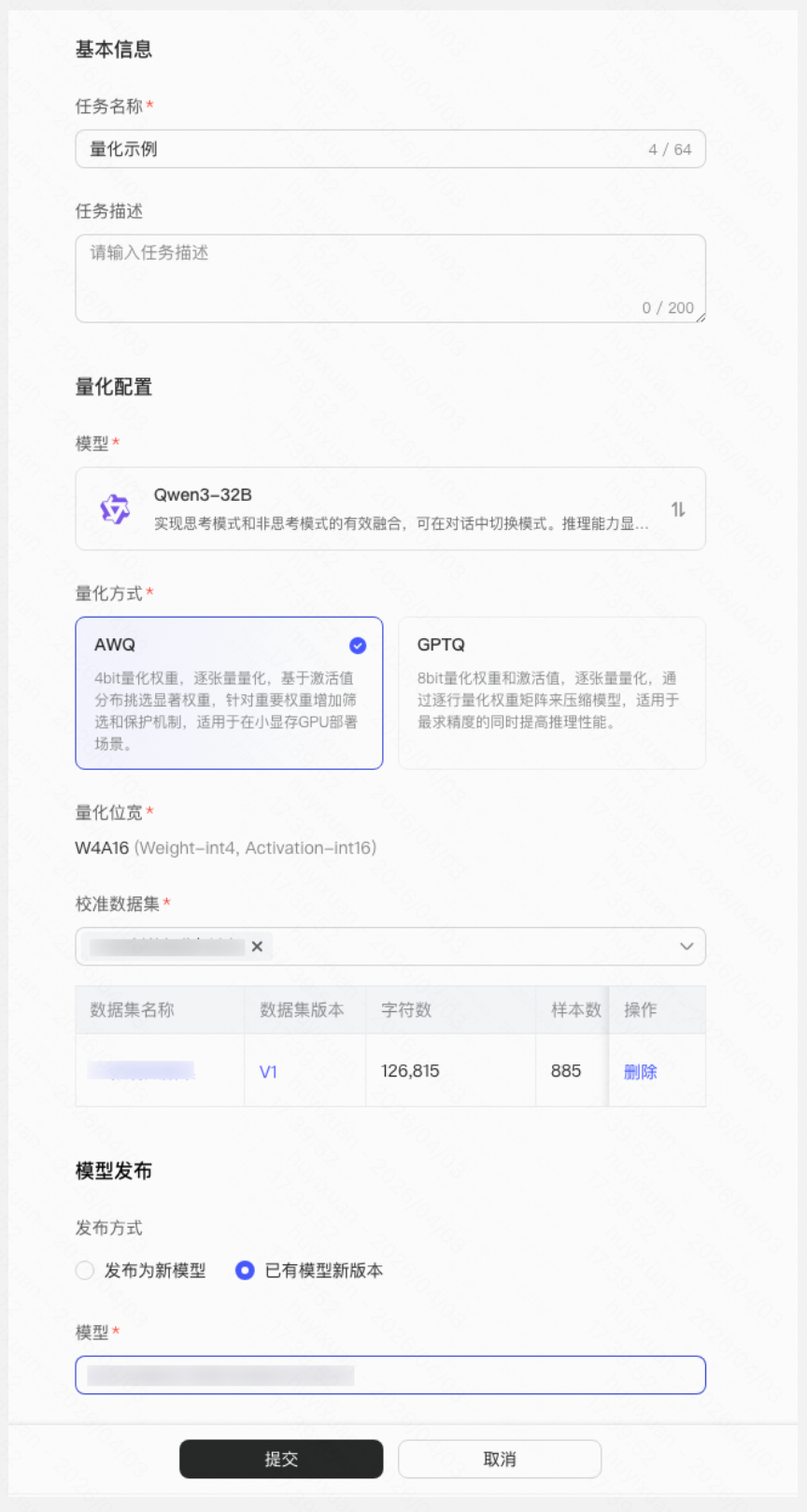
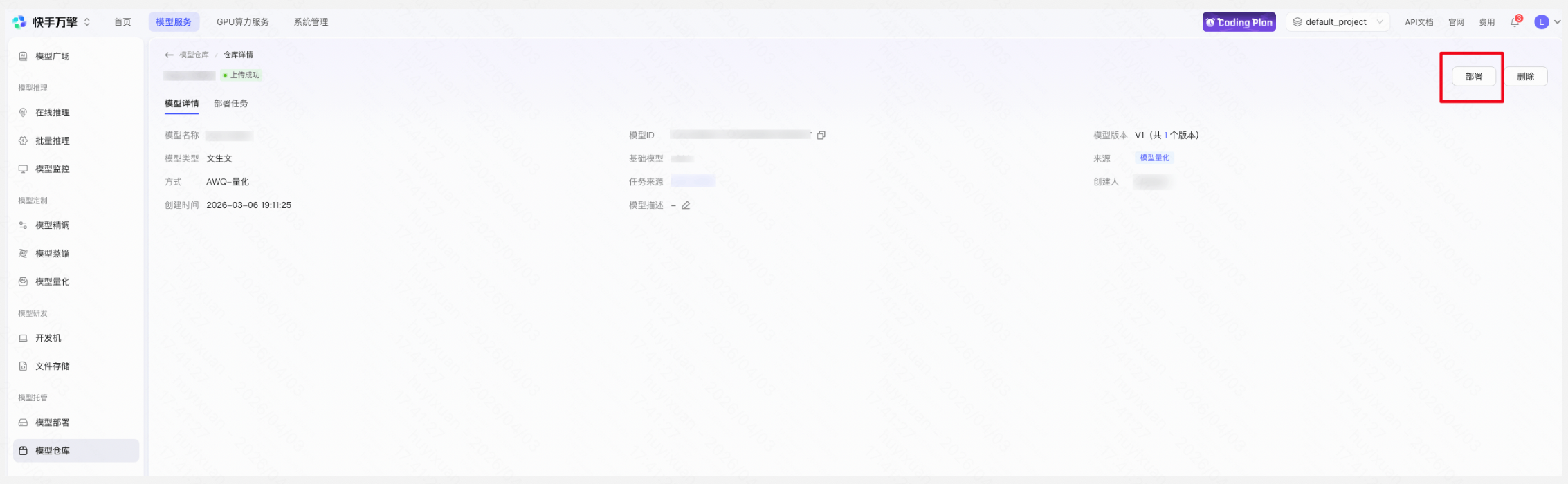
Step 4:部署量化后模型
将量化后的模型部署为推理接入点,替换原有的全精度模型。
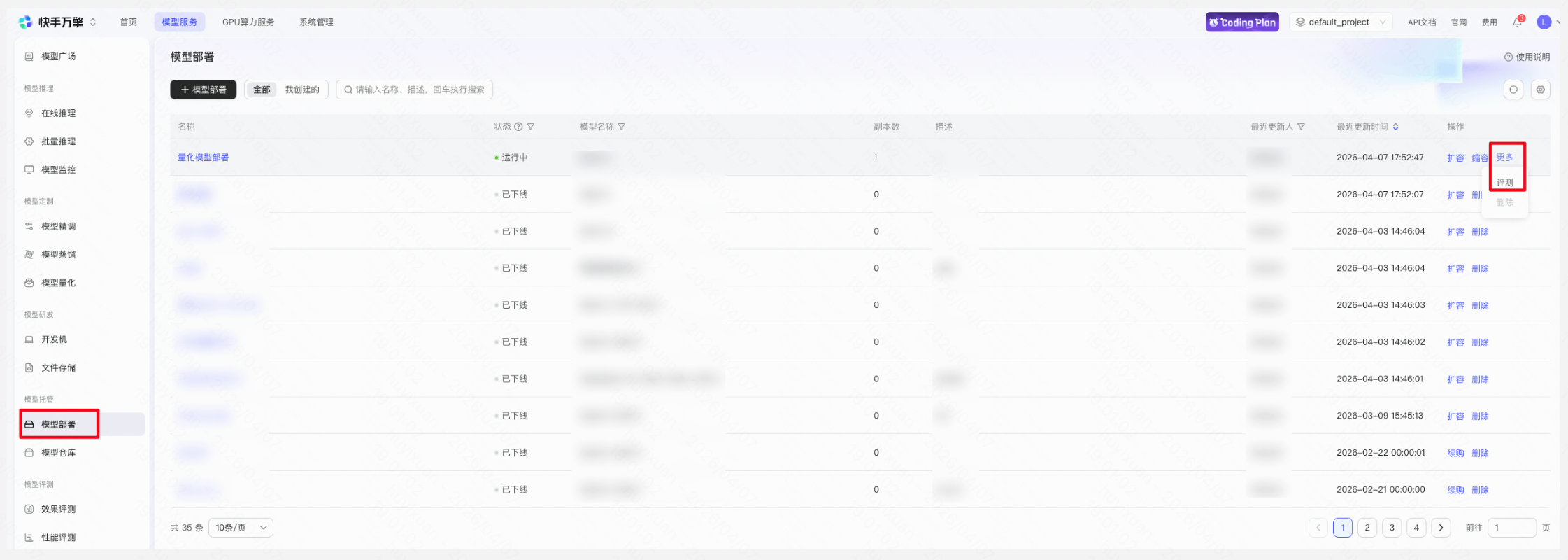
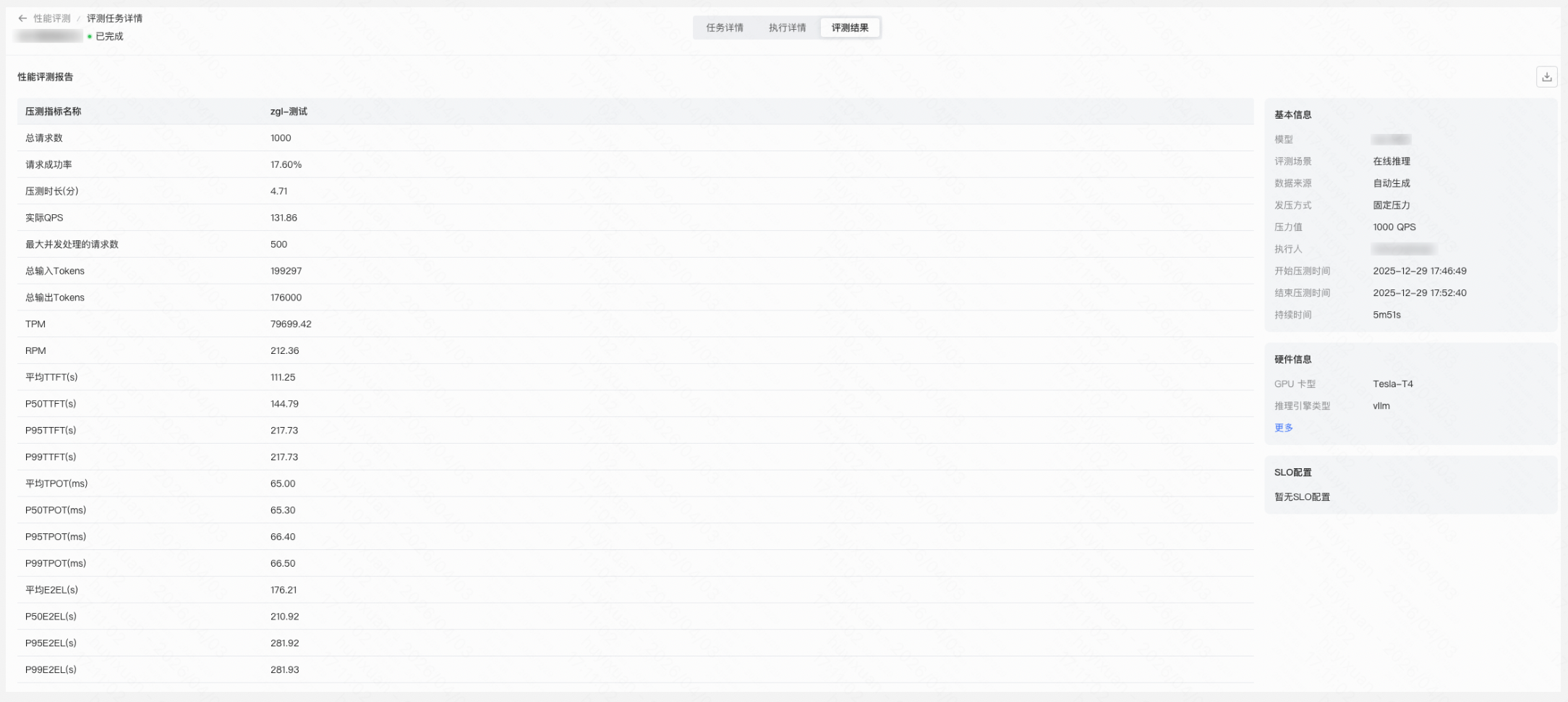
Step 5:模型评测
已部署的模型可通过点击评测进入效果评测流程,支持人工评测和自动评测,自动评测可大幅提升评测效率,评测完成后可通过评测详情和评测结果对比模型表现。
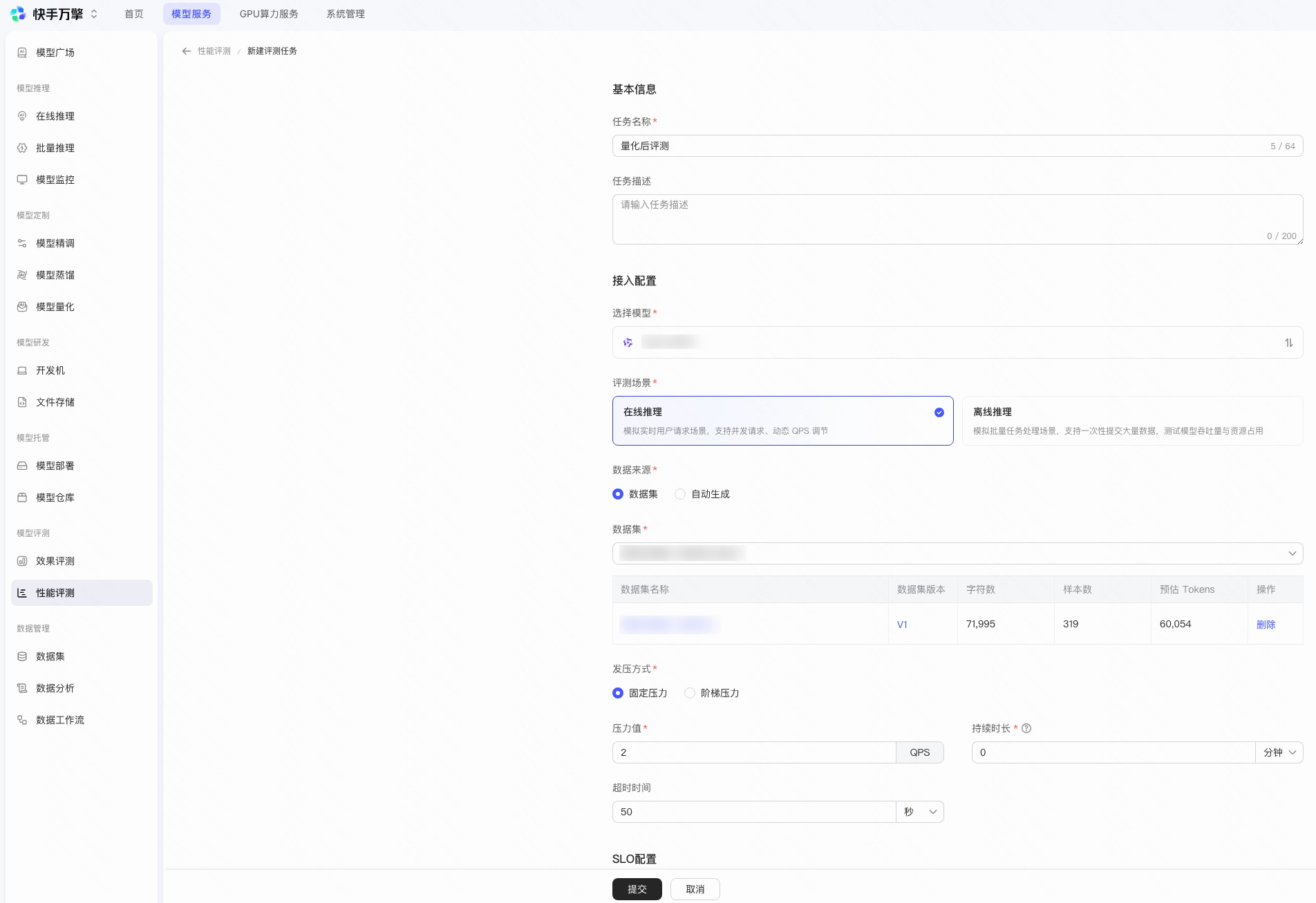
您也可以创建性能评测任务检验模型在不同压力条件下的推理性能表现,包括延迟、吞吐量、成功率等关键指标,可基于此制定合理的调用策略和限流配置。
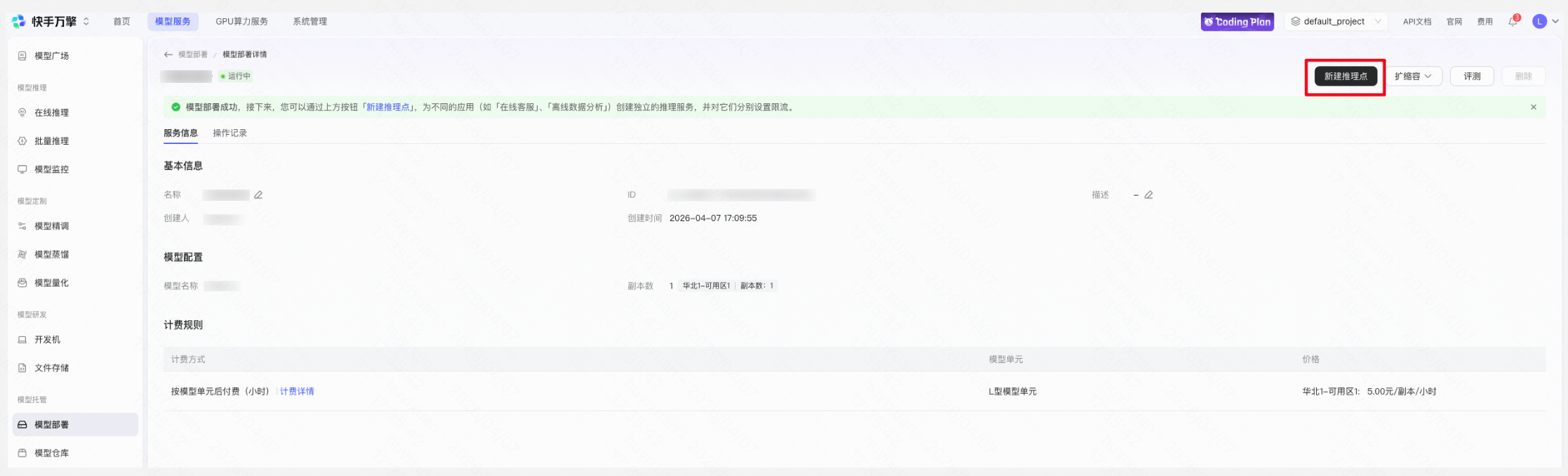
Step 6:创建推理点并上线
在万擎平台创建推理接入点(Endpoint),选择已发布的定制模型创建推理接入点并上线。
预期效果:GPU 显存占用和推理成本可大幅降低,推理速度相应提升,模型效果损失较小。具体数据视所选量化方式和业务场景而定。建议量化后进行业务测试,确认效果满足需求后再正式切换。