
模型蒸馏
一、什么是模型蒸馏
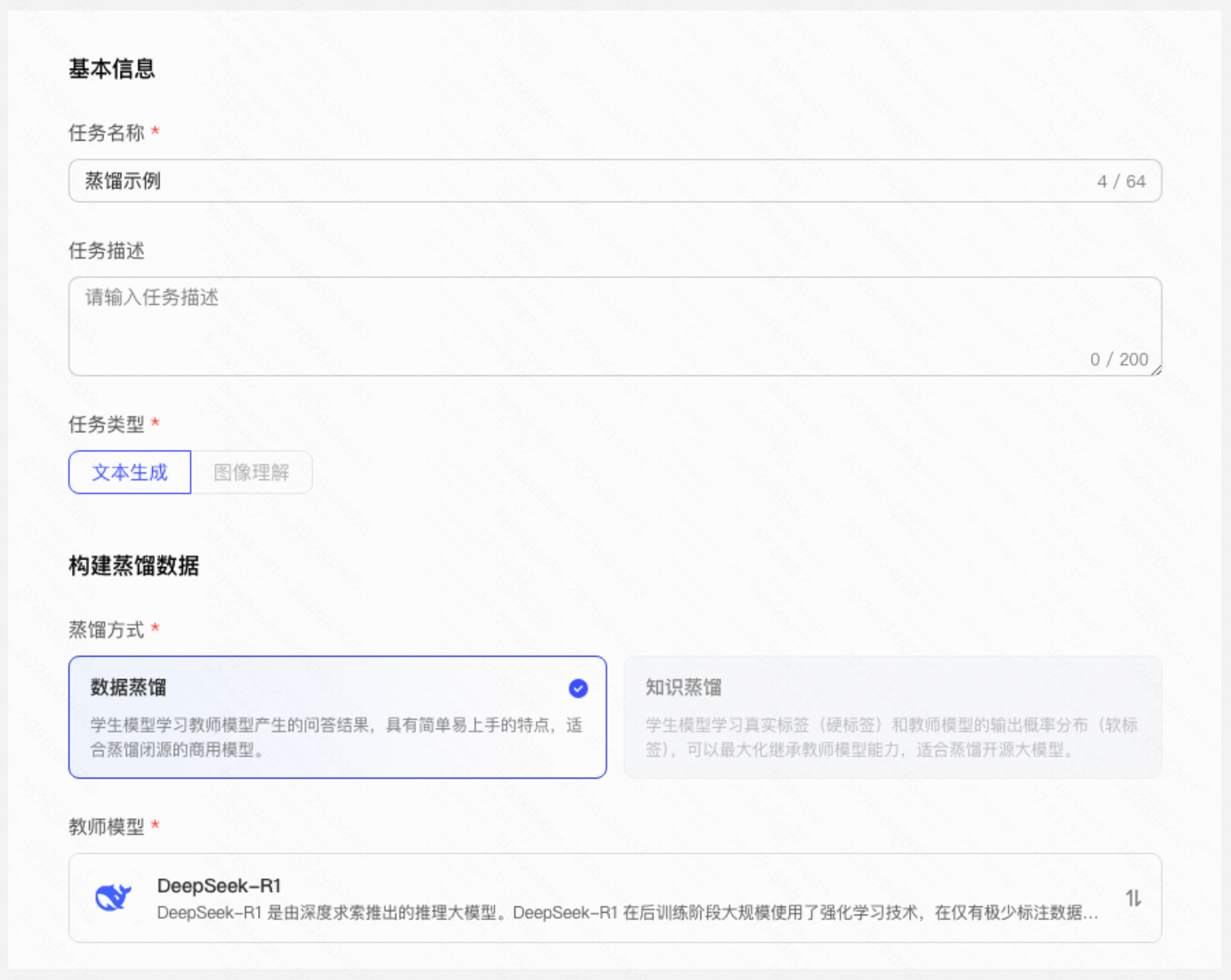
模型蒸馏(Model Distillation):是一种知识迁移技术,核心思路是利用大模型(教师模型)的能力生成高质量训练数据,再用这些数据训练小模型(学生模型)。经过蒸馏的小模型能够在特定任务上接近大模型的效果,同时具备推理速度快、部署成本低的优势。
体验链接:模型蒸馏
数据蒸馏 vs 知识蒸馏
方式 | 原理 |
数据蒸馏 | 用教师模型推理生成高质量训练数据,再用这些数据训练学生模型 |
知识蒸馏 | 学生模型同时学习真实标签(硬标签)和教师模型的输出概率分布(软标签) |
二、典型应用场景
- 场景 1:高成本推理优化
- 痛点:使用顶级大模型效果优秀但推理成本过高
- 方案:将大模型蒸馏到 Qwen3-8B 等小模型
- 效果:推理成本可大幅降低,业务效果保持在较高水平
- 场景 2:低延迟场景
- 痛点:实时翻译、语音交互等场景需要快速响应,大模型延迟过高
- 方案:蒸馏到轻量模型(如 Qwen3-4B 或 Qwen3-1.7B)
- 效果:响应延迟可显著降低
- 场景 3:领域知识迁移
- 痛点:希望小模型也具备大模型的医疗/法律/金融专业能力
- 方案:用领域数据驱动大模型生成专业回答,蒸馏到小模型
- 效果:小模型在特定领域的专业能力可大幅提升
三、核心能力
3.1 数据蒸馏
数据蒸馏流程
教师模型(大模型)推理生成高质量数据 → 自动构建训练数据集 → 训练学生模型(小模型)
支持教师模型
教师模型 | 特点 |
DeepSeek R1 | 推理能力强,适合逻辑推理、数学、代码场景 |
DeepSeek V3 | 综合能力强,通用场景表现优秀 |
DeepSeek-V3.2 | V3 升级版,能力进一步提升 |
支持学生模型
学生模型 | 适用场景 |
Qwen3-0.6B | 极致轻量,边缘设备、嵌入式场景 |
Qwen3-1.7B | 轻量部署,简单任务 |
Qwen3-4B | 性价比较优,中等复杂任务 |
Qwen3-8B | 推荐首选,兼顾效果和成本 |
Qwen3-14B | 追求更高效果,适合复杂任务 |
数据校验方式
- 自动校验:平台自动评估蒸馏数据质量和训练效果,教师模型推理完成后自动校验蒸馏数据构建结果,若通过校验自动进入训练流程。
- 手动校验:用户可手动审核蒸馏生成的数据质量,教师模型推理完成后后人工查看数据集进行校验,需手动点击开始训练,进入训练流程。
训练方法
与 SFT 相同,支持:
- 全量更新:更新所有参数,效果上限更高
- LoRA:仅更新部分参数,训练更快、成本更低
3.2 知识蒸馏
知识蒸馏流程
用户选择教师模型与学生模型 → 配置知识蒸馏参数 → 学生模型直接学习教师模型的软标签(输出概率分布)→ 训练完成
支持教师模型
教师模型 | 特点 |
Qwen3.5-397B-A17B | Qwen3.5系列中的高性能开源模型 |
支持学生模型
学生模型 | 适用场景 |
Qwen3-0.6B | 极致轻量,边缘设备、嵌入式场景 |
Qwen3-1.7B | 轻量部署,简单任务 |
Qwen3-4B | 性价比较优,中等复杂任务 |
Qwen3-8B | 推荐首选,兼顾效果和成本 |
Qwen3-14B | 追求更高效果,适合复杂任务 |
采样策略
- Off-Policy蒸馏:学生模型在数据集标准答案上模仿教师模型的输出分布,具有训练稳定、速度快的特点,适合大多数蒸馏场景。
- On-Policy蒸馏:学生模型先自行生成回答,再由教师模型在这些回答上提供分布作为学习目标,具有纠偏能力强、效果更优的特点,适合对蒸馏质量要求高的场景。
知识蒸馏参数
- 温度(Temperature):控制软标签概率分布的平滑程度,值越大分布越平滑,学生模型学习越"柔和"。(建议范围 0.9~1.2)
- Top-K:生成时只考虑概率最高的 K 个 token,0=不限制,较小值使生成更聚焦,较大值增加多样性。(建议值:64 或 0)
训练方法
与数据蒸馏相同,支持:
- 全量更新:更新所有参数,效果上限更高
- LoRA:仅更新部分参数,训练更快、成本更低
四、蒸馏后模型的延伸能力
蒸馏产出的模型支持进一步操作:
- 部署:直接创建推理接入点上线使用
- 精调:通过 SFT/DPO 进一步优化
- 量化:进一步压缩体积、降低成本
【⚠️注意:蒸馏 → 精调 → 量化的三步组合,可实现接近大模型效果、小模型成本的优化方案。】
五、场景示例
前置准备
- 权限申请:
- 主账号(即溪流湖账户)拥有账号下所有项目的访问/管理权限,无需权限申请,主账号可对所有蒸馏任务进行修改、删除;
- 子账号:可由主账号为名下子账号设置某项目的只读/管理权限,子账号不支持删除主账号新建的蒸馏任务;
- 若账户余额不足,请先充值;
- 确认权限及余额无问题后,在左侧导航栏中「模型定制」下方点击「模型蒸馏」进入产品页面,点击「+新建蒸馏任务」进入创建页面。
5.1 数据蒸馏示例
背景:某金融科技企业使用 DeepSeek R1(671B 参数)进行风控规则推理和金融报告生成,效果优秀但推理成本较高,响应延迟影响用户体验。
目标:在保持较高业务效果的前提下,大幅降低推理成本并缩短响应延迟。
Step 1:选择教师模型
选择 DeepSeek R1 作为教师模型——该模型已在企业业务中验证效果。
Step 2:准备数据集
准备用于蒸馏的数据集(即需要教师模型处理的问题集合):
- 可使用企业积累的真实业务问题
- 也可使用平台已有数据集
- 建议准备 1000-5000 条覆盖典型业务场景的问题
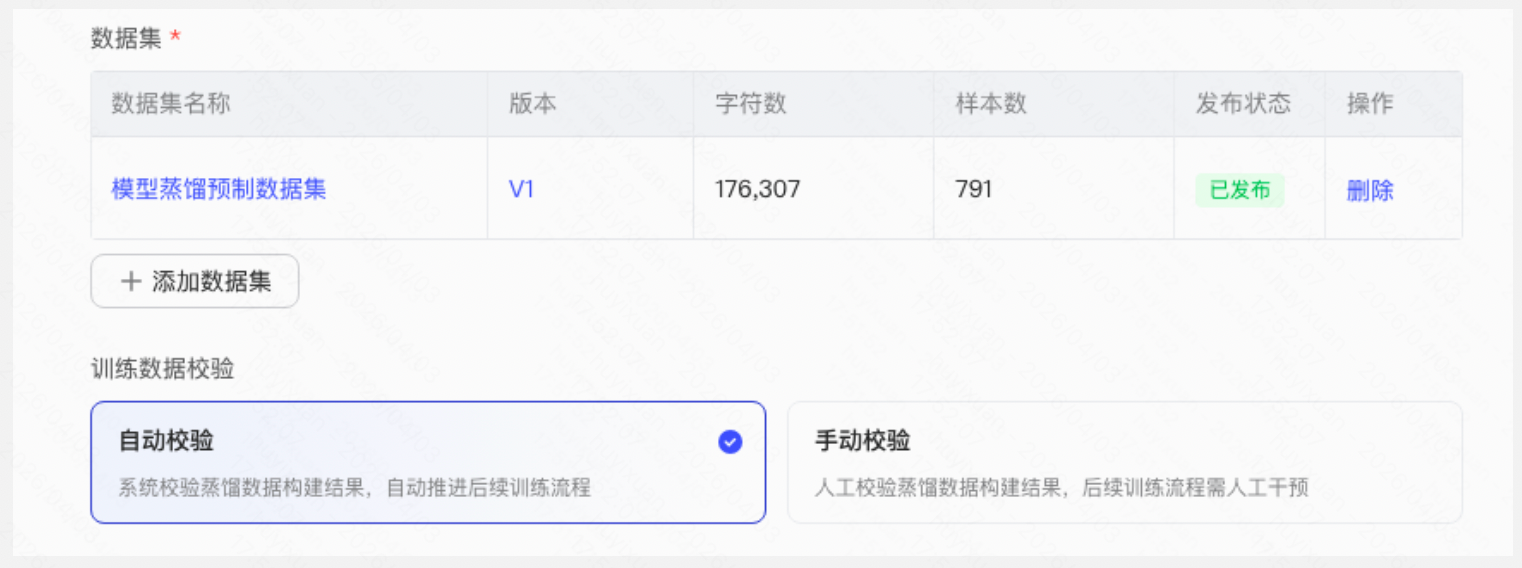
Step 3:教师模型推理生成蒸馏数据
平台自动将数据集发送给教师模型,教师模型针对每个问题生成高质量回答,形成蒸馏训练数据集。
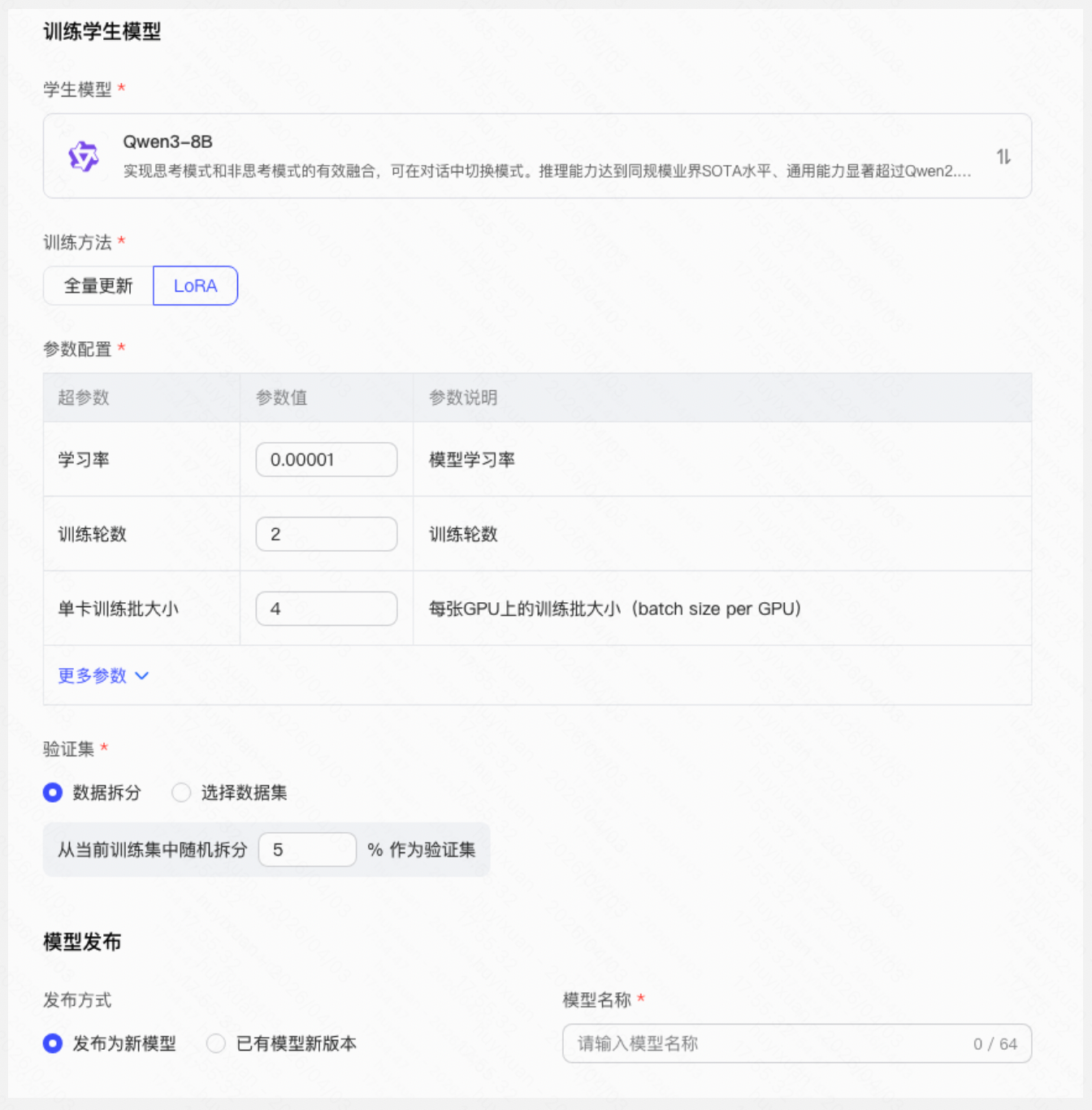
Step 4:选择学生模型
选择 Qwen3-8B 作为学生模型——参数量仅为教师模型的约 1/80,推理成本极低。
Step 5:训练学生模型
使用蒸馏数据集训练学生模型:
- 选择训练方法(推荐 LoRA 用于快速验证)
- 配置训练参数
- 平台支持自动校验或手动校验效果
- 自动校验:教师模型推理完成后自动校验蒸馏数据构建结果,若通过校验自动进入训练流程;
- 手动校验:教师模型推理完成后后人工查看数据集进行校验,需手动点击开始训练,进入训练流程。蒸馏数据构建完成后,在蒸馏任务列表中,任务状态会变为待训练,用户确认数据质量符合预期后,单击开始训练继续执行学生模型训练。
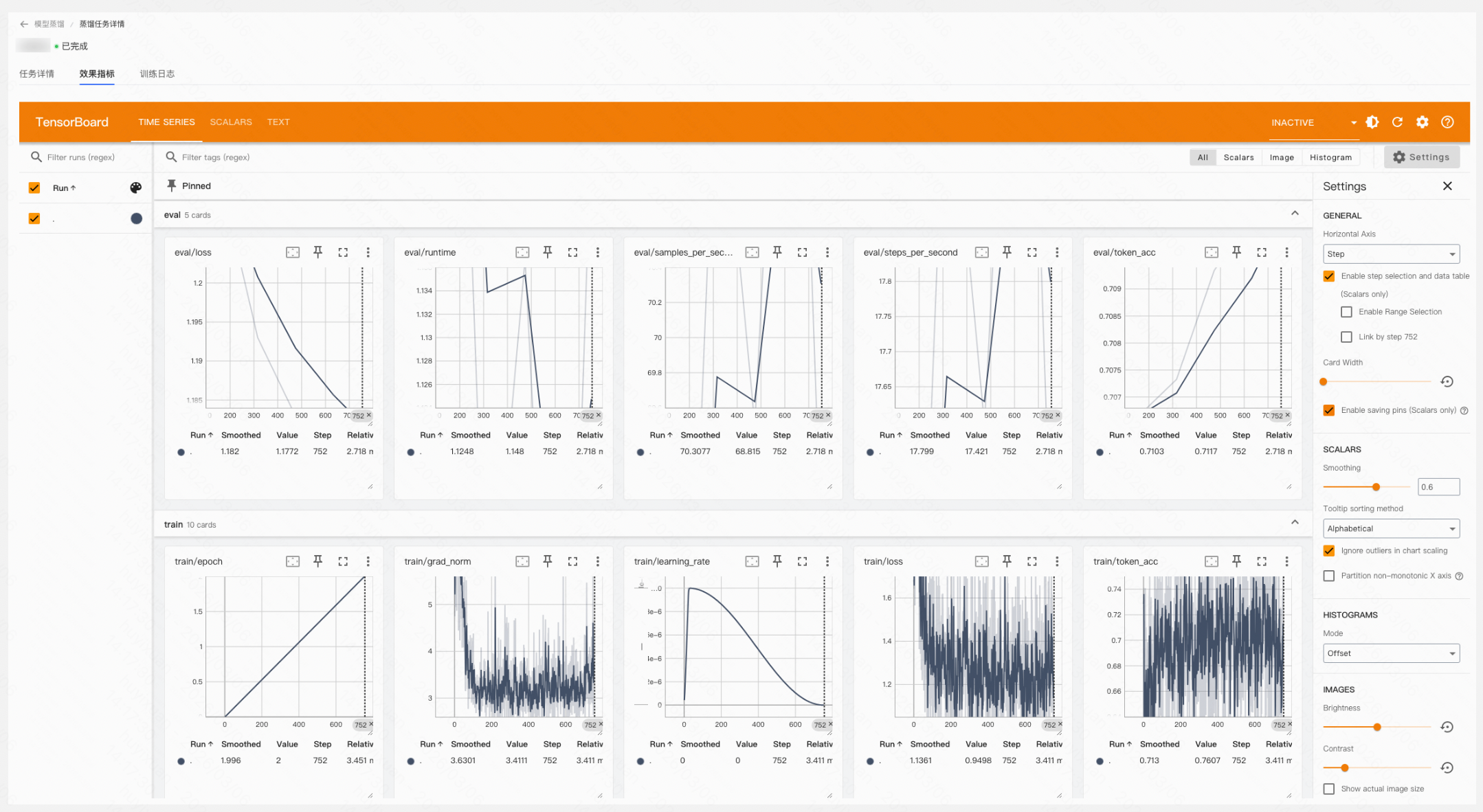
Step 6:监控训练过程
【⚠️仅在任务开始训练后支持查看效果指标/训练日志】
- 用户可通过平台提供的TensorBoard查看验证集和训练集的指标情况,包括loss(损失函数)、learning rate(学习率)、grad norm(梯度范数)等。
- 在任务日志页面,您可查看该蒸馏任务的日志详情,包括数据集处理、模型准备、训练任务执行过程等:
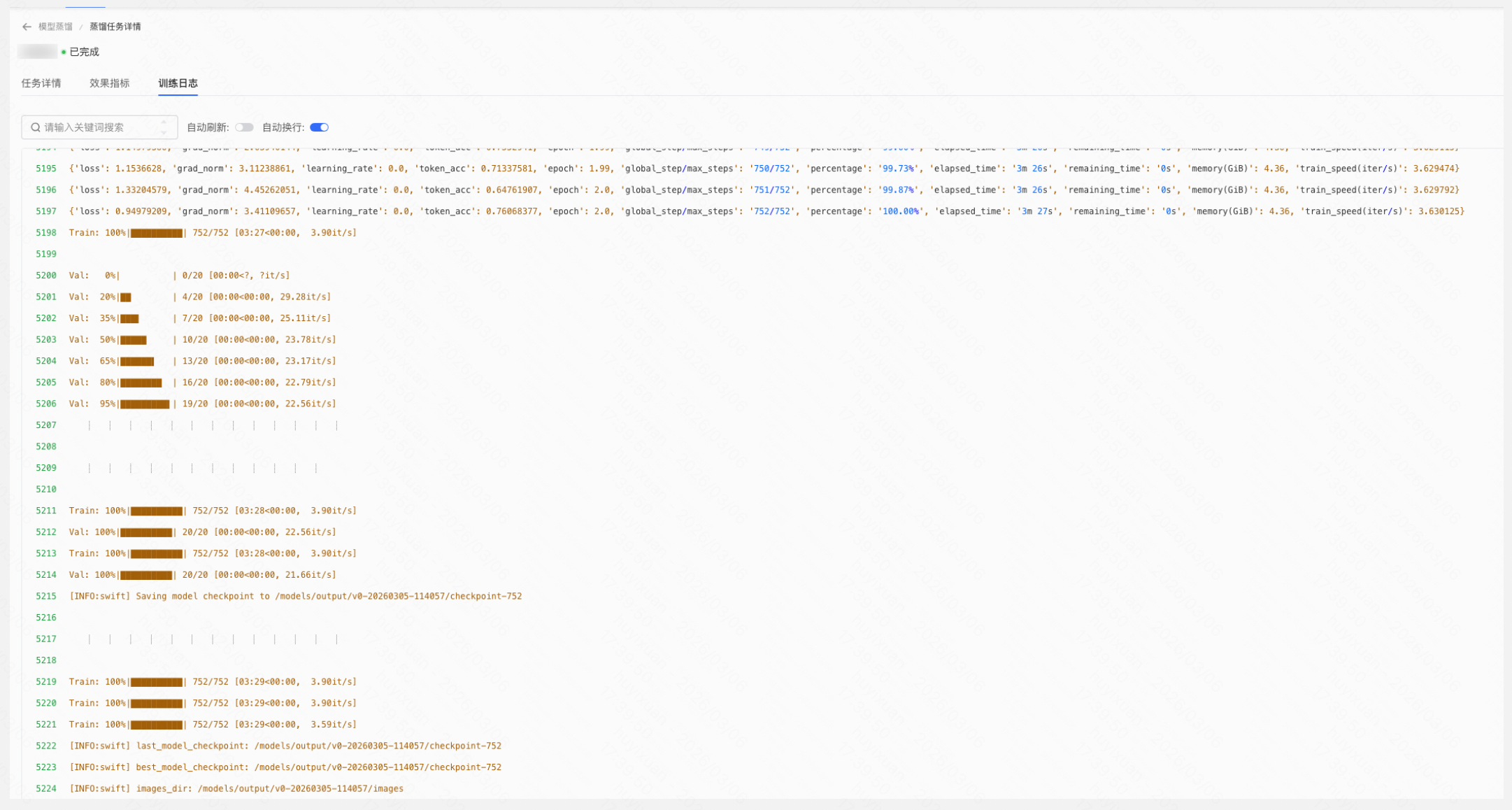
Step 7:部署轻量模型
将训练完成的学生模型部署上线,替换原有的大模型。
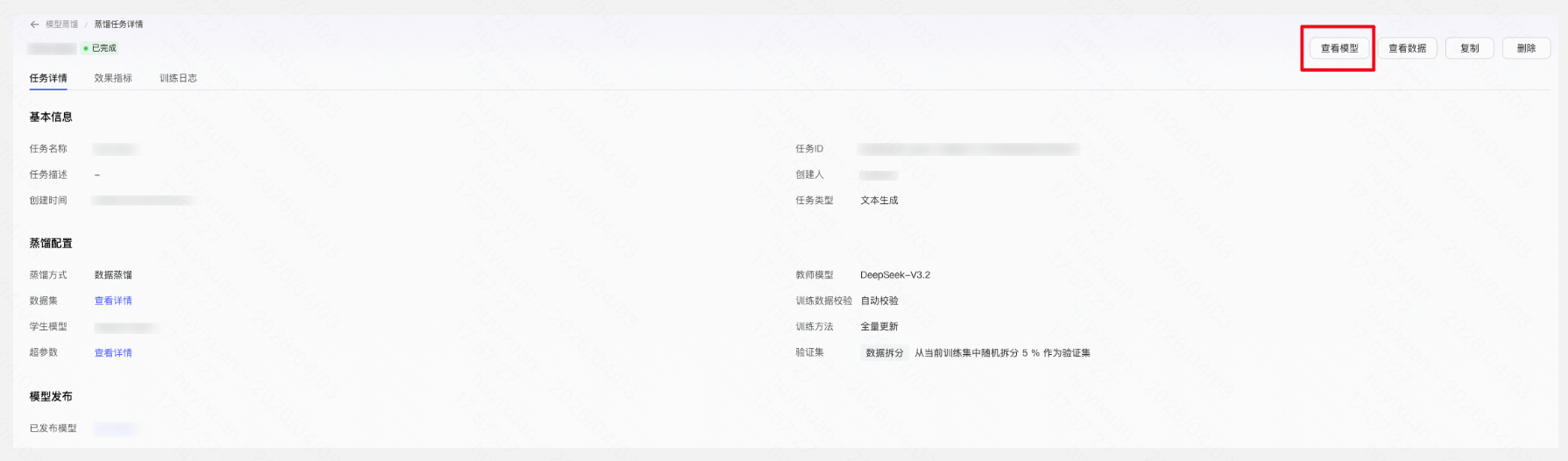

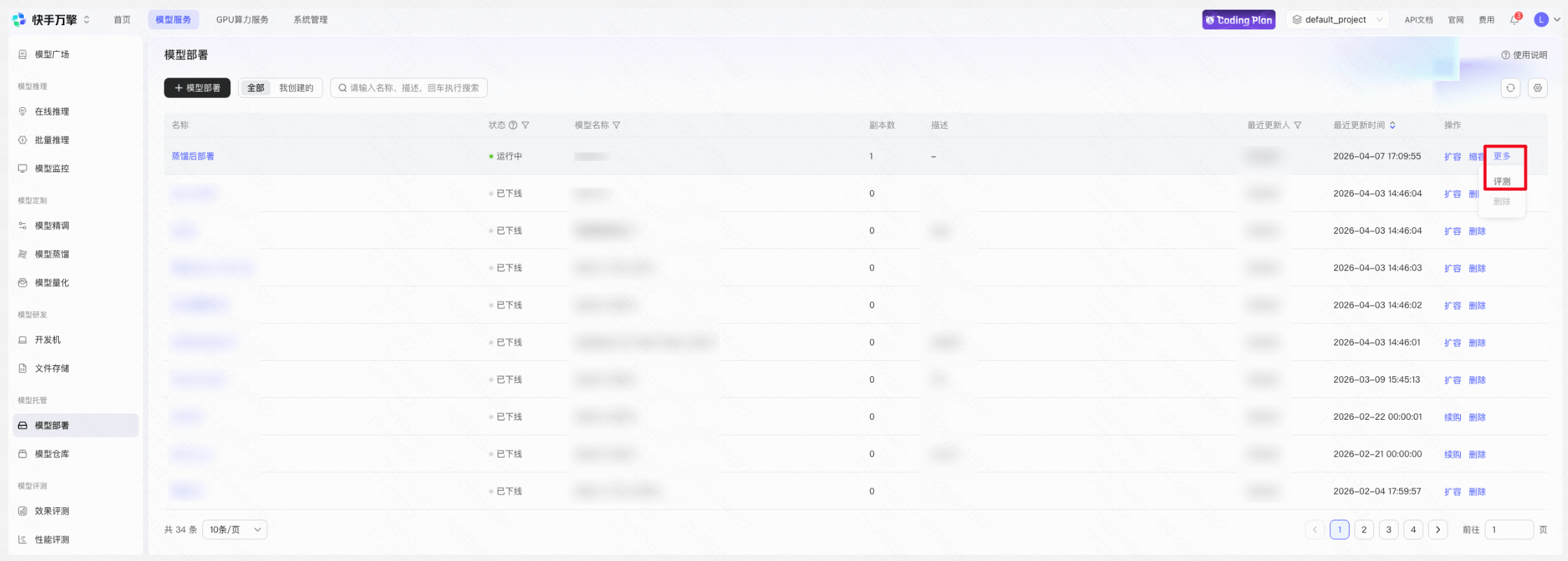
Step 8:模型评测
已部署的模型可通过点击评测进入效果评测流程,支持人工评测和自动评测,自动评测可大幅提升评测效率,评测完成后可通过评测详情和评测结果对比模型表现。
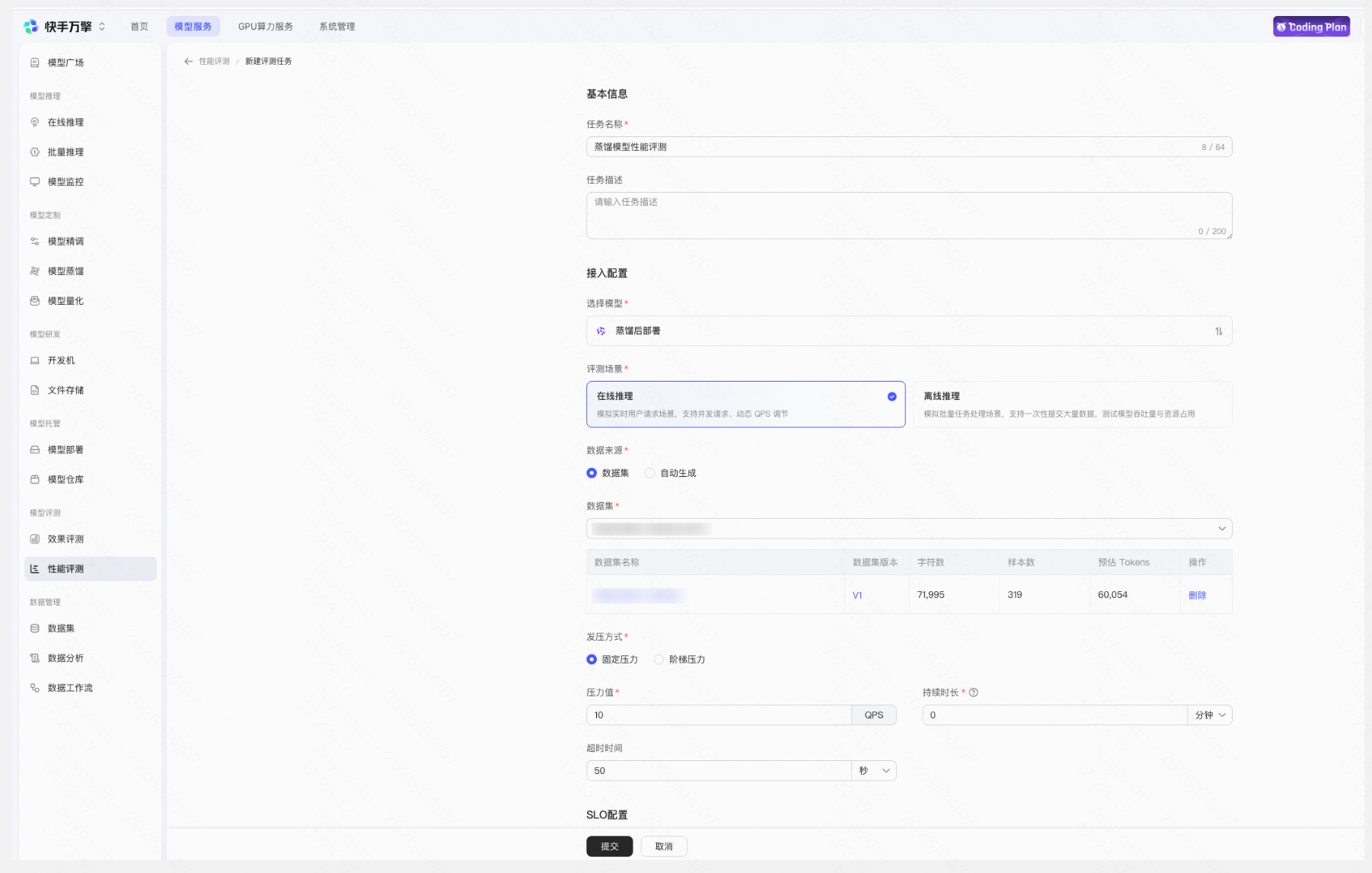
您也可以创建性能评测任务检验模型在不同压力条件下的推理性能表现,包括延迟、吞吐量、成功率等关键指标,可基于此制定合理的调用策略和限流配置。
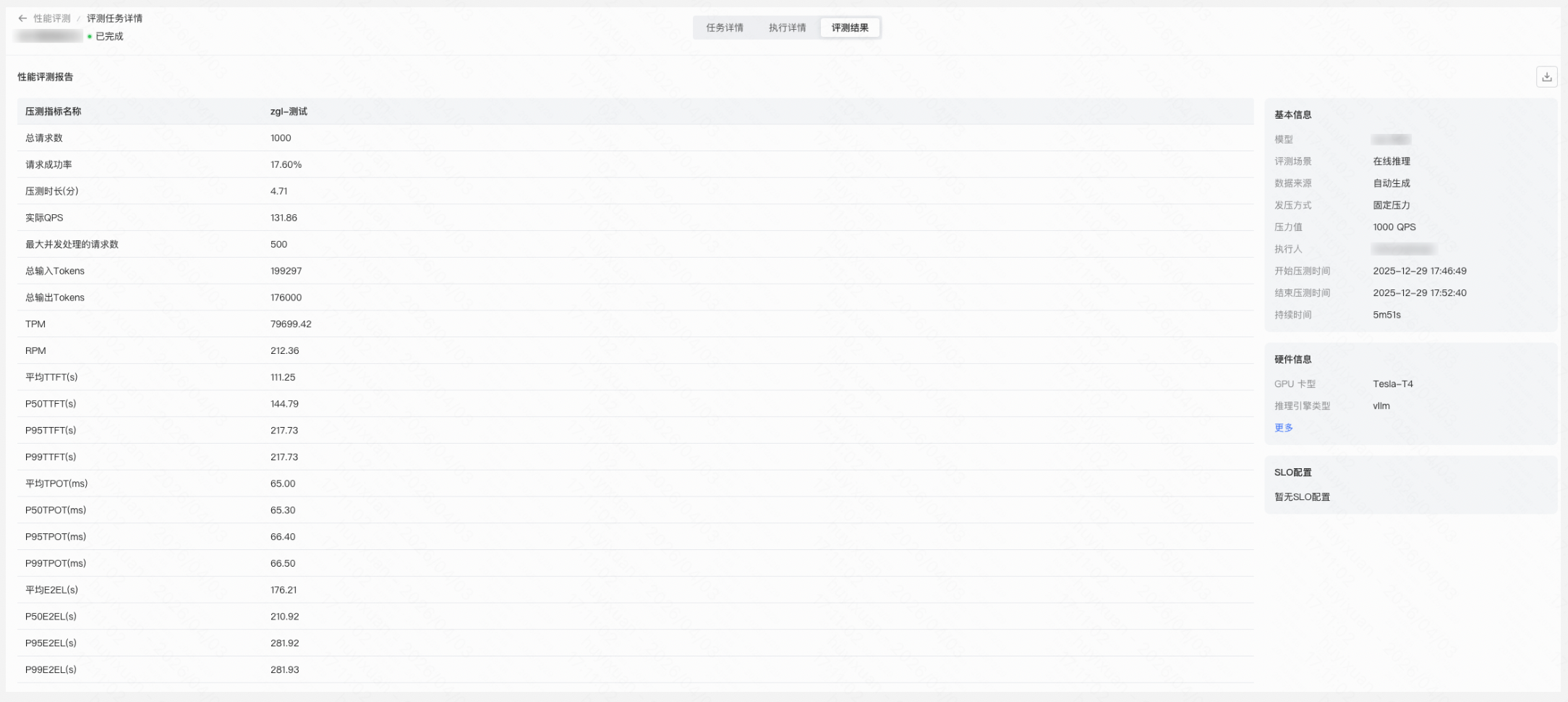
Step 9:创建推理点并上线
在万擎平台创建推理接入点(Endpoint),选择已发布的定制模型创建推理接入点并上线。
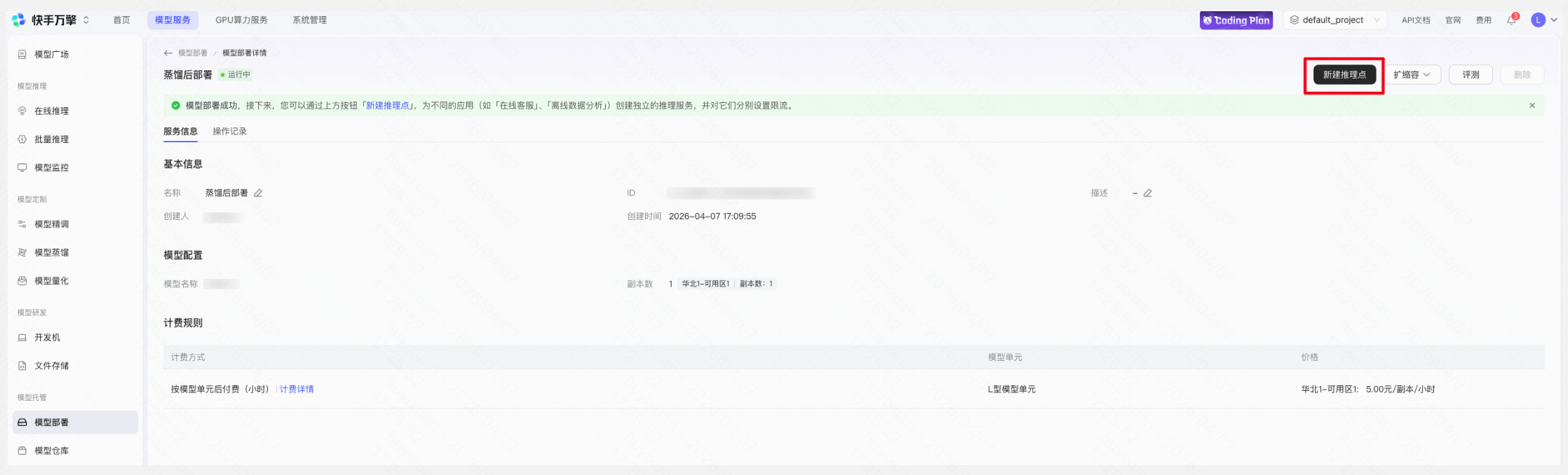
预期效果:推理成本可大幅降低,响应延迟显著缩短。在蒸馏聚焦的特定任务上,小模型可保持较高的业务效果。具体数据视模型选择、数据质量和业务场景而定。蒸馏后还可进一步通过 SFT 微调和量化持续优化。
5.2 知识蒸馏示例
背景:团队希望将 DeepSeek R1 的推理能力迁移到 Qwen3-8B,且已有完整的标注问答数据集,希望跳过教师模型推理阶段、直接进入训练,缩短整体蒸馏周期。
目标:通过知识蒸馏最大化继承 DeepSeek R1 的推理能力,同时大幅降低推理成本。
Step 1:选择蒸馏方式及采样策略
万擎提供 Off-Policy 和 On-Policy 蒸馏两种策略,二者核心区别在于学生模型用谁生成的文本来学习教师模型的概率分布。此处选择 Off-Policy 快速跑通流程、验证基本效果。
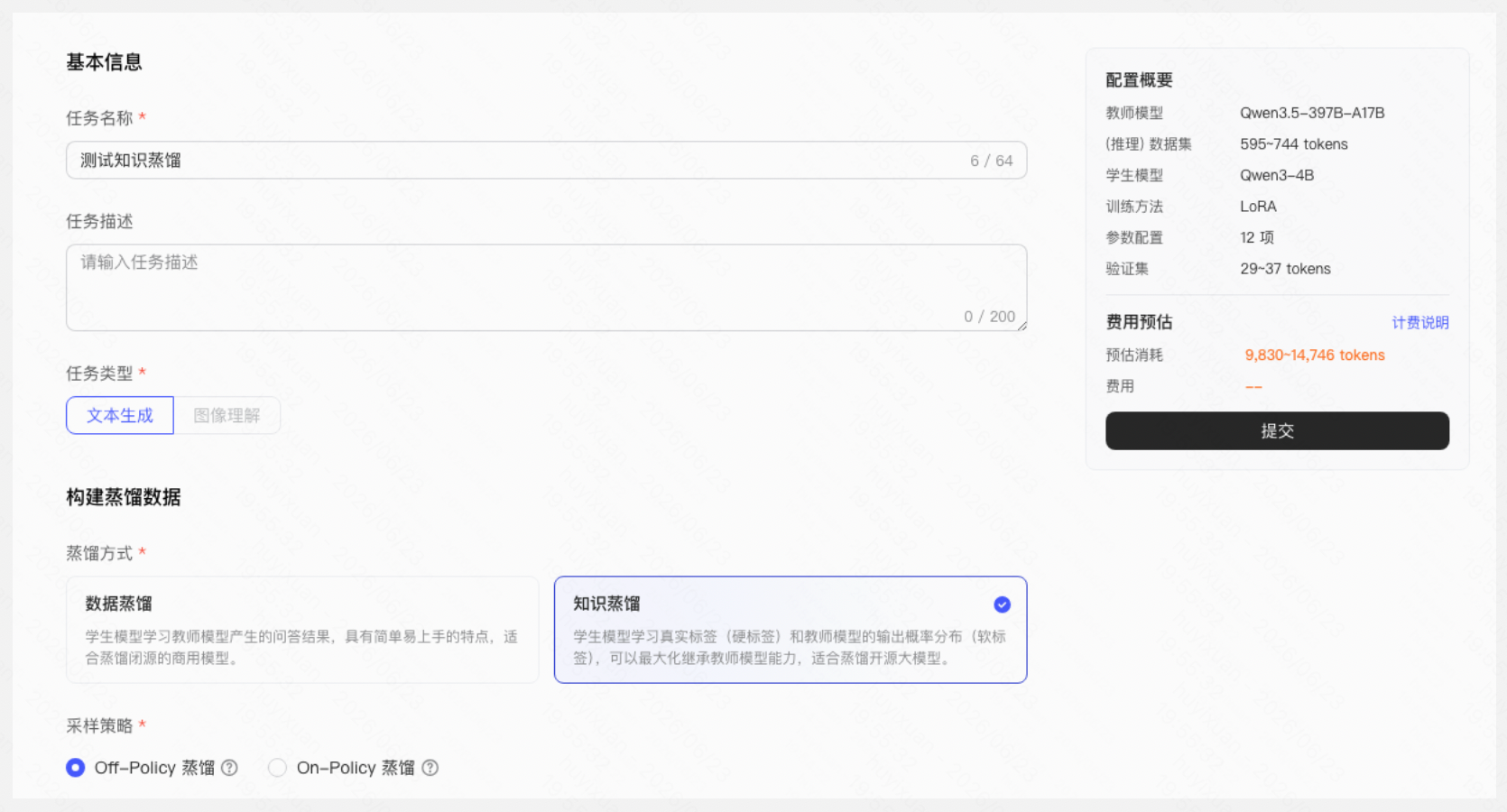
Step 2:选择教师模型及数据集
选择 Qwen3.5-397B-A17B 作为教师模型,上传包含问题的数据集,知识蒸馏无需教师模型预先推理,可直接使用业务积累的数据集
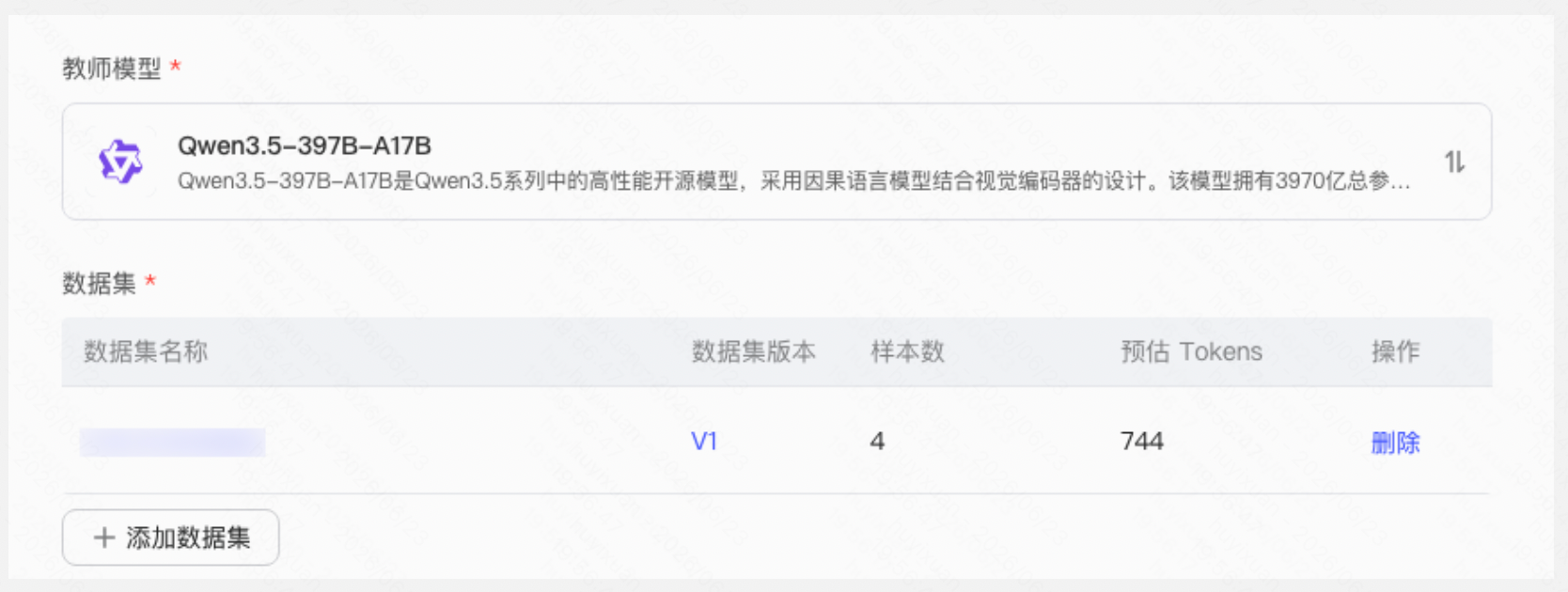
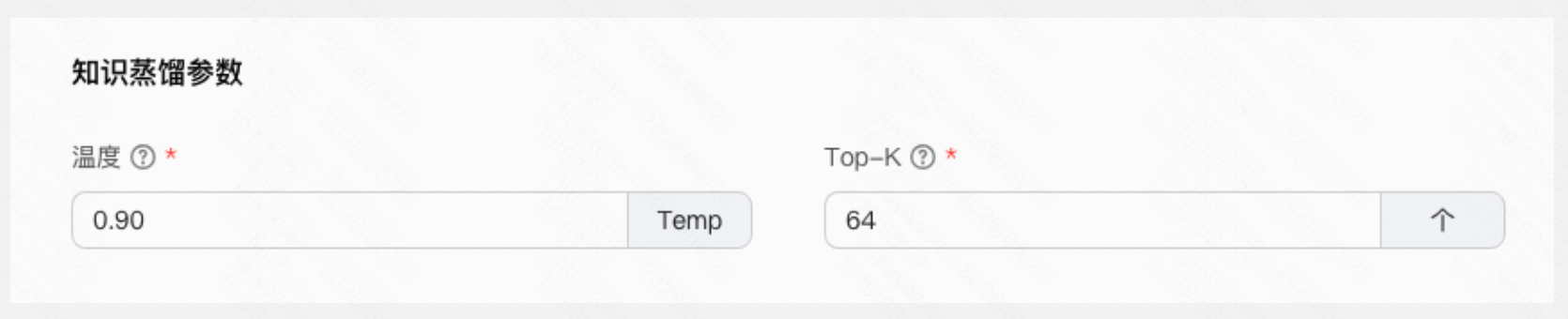
Step 3:配置知识蒸馏参数
根据业务需求调整参数,或直接使用平台默认值快速开始:
- 温度(Temperature):默认 0.9,建议范围 0.9~1.2
- Top-K:默认 64
Step 4:选择学生模型及训练配置
- 选择 Qwen3-4B 作为学生模型,训练方法选择 LoRA(快速验证推荐)或全量更新(追求最优效果),此处选择 LoRA。
- 配置训练参数:配置学习率、训练轮次等参数(可使用默认值),确认费用预估后点击「提交」,任务将直接进入排队中状态(知识蒸馏无需教师推理阶段,相比数据蒸馏流程更短)。
Step 5:监控训练过程-同数据蒸馏
【⚠️仅在任务开始训练后支持查看效果指标/训练日志】
- 用户可通过平台提供的TensorBoard查看验证集和训练集的指标情况,包括loss(损失函数)、learning rate(学习率)、grad norm(梯度范数)等。
- 在任务日志页面,您可查看该蒸馏任务的日志详情,包括数据集处理、模型准备、训练任务执行过程等:
Step 6:部署轻量模型-同数据蒸馏
将训练完成的学生模型部署上线,替换原有的大模型。
Step 7:模型评测-同数据蒸馏
已部署的模型可通过点击评测进入效果评测流程,支持人工评测和自动评测,自动评测可大幅提升评测效率,评测完成后可通过评测详情和评测结果对比模型表现。
您也可以创建性能评测任务检验模型在不同压力条件下的推理性能表现,包括延迟、吞吐量、成功率等关键指标,可基于此制定合理的调用策略和限流配置。
Step 8:创建推理点并上线-同数据蒸馏
在万擎平台创建推理接入点(Endpoint),选择已发布的定制模型创建推理接入点并上线。
附录
蒸馏任务训练配置-参数配置详情:
超参数 | 参数说明 |
学习率 | 控制模型参数更新步长的速度。过高会导致模型难以收敛,过低则会导致模型收敛速度过慢,平台已给出默认推荐值,可根据经验调整。 |
训练轮次 | 控制模型训练过程中遍历整个数据集的次数。建议设置在1-5之间,小数据集可增大Epoch以促进模型收敛。 |
单卡训练批大小 | 每张GPU上的训练批大小(batch size per GPU)。 |
单卡评估批大小 | 每张GPU上的评估批大小。 |
梯度累积步数 | 指模型在更新一次参数前,连续累积多少个小批次(batch)的梯度,从而在不增加显存占用的情况下,实现更大的等效 batch size。全局有效批大小 = 每张GPU的batch size × GPU数量 × 梯度累积步数 |
评估间隔比例 | 按总训练步数的比例进行评估(0~1)。大于0时优先生效,例如0.1表示每10%训练进度评估一次。 |
保存间隔比例 | 按总训练步数比例保存模型(0~1)。大于0时优先生效。 |
最大Checkpoint数量 | 最多保留的模型checkpoint数量,超过后自动删除最旧文件。 |
学习率预热比例 | 学习率预热步数占总训练步数的比例(0~1)。学习率预热可以提高模型稳定性和收敛速度。 |
输入最大长度 | 输入token最大长度,超过将被截断。通常应小于等于模型的最大context长度,超过该长度的数据在训练将被自动截断。如果数据集中的文本普遍较短,建议选择较短的序列长度以提高计算效率。 |
LoRA秩(Rank) | LoRA低秩矩阵的秩(r)。值越大表示可训练参数越多,表达能力更强,但显存和计算开销增加。选择全量训练时该参数无效。 |
LoRA缩放系数 | LoRA缩放因子(alpha),实际缩放比例为 alpha / rank。通常设为 rank 的1~4倍。选择全量训练时该参数无效。 |